Introdução
Sejam bem-vindos(as)!
Produzir um documento impresso (livro físico) sobre inteligência artificial, ao menos no momento, é quase tão útil quanto tentar parar o tempo: esse é o principal motivo pelo qual optei, já há algum tempo, por produzir conteúdo digital — isso torna viável sua atualização de forma quase tão célere quanto as notícias e descobertas do campo são feitas.
O objetivo deste material não é apresentar um conteúdo exaustivo sobre o tema, mas servir como guia de referência prática — de onde você pode extrair informações específicas, copiar um prompt e adaptá-lo à sua necessidade.
Quaisquer dúvidas, sinta-se à vontade para entrar em contato (na seção "Contatos", ao final deste e-book, você encontrará diversos canais para isso).
Por fim, este ebook foi feito otimizado para uso em telas grandes (PC, tablets, etc.), mas também funcionará em telas menores (celulares).
Funcionamento básico das ferramentas de IA
Mantendo as definições teóricas ao mínimo necessário: entender como funcionam as ferramentas de IA é fundamental para extrair seus melhores resultados. É apenas por essa razão que faz sentido compreender o básico sobre os fundamentos dessas ferramentas — e não será muito complicado. Como você já deve ter ouvido falar, o ChatGPT (e correlatos) funciona como se fosse um grande previsor de texto. Estamos mais ou menos acostumados com esses recursos em alguns aplicativos cotidianos. Por exemplo, no celular, quando respondemos a nossos e-mails, mal começamos a mensagem e já há uma sugestão de texto subsequente (Figura 01).
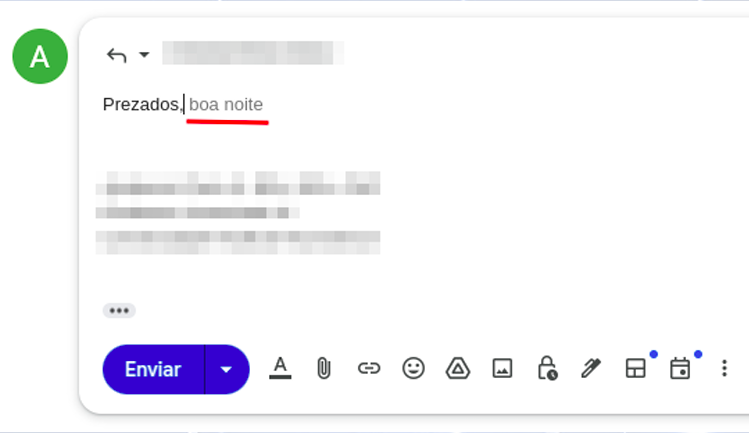
Esse autocompletar existe por uma questão de "contexto" e pela probabilidade das palavras na sequência. Se eu te peço para completar a frase "o céu é [___]", qual palavra veio à sua mente? A probabilidade de você ter pensado em "azul" ou "grande" é muito maior do que a de ter pensado em "carmim". As frases "O céu é azul", "O céu é grande" e "O céu é carmim" estão todas tecnicamente corretas, mas não são usadas com a mesma frequência em nosso cotidiano.
Como aplicamos isso às ferramentas de IA? Elas foram apresentadas ("treinadas") analisando bilhões — literalmente — de textos e materiais, de forma que possuem dados sobre as probabilidades de ocorrência de palavras sequenciais. Obviamente é muito mais complexo do que isso, mas essa analogia nos ajudará a usar as ferramentas de IA de maneira mais efetiva.
No contexto deste e-book: treinamento, de maneira bem simples, é o nome dado ao processo de apresentação de fontes de material (por exemplo, textos em diferentes idiomas) às IAs, para que seja possível o reconhecimento de padrões e, a partir daí, a decisão sobre qual texto ou palavra deve vir na sequência.
Modelos de IA
Quando você abre as ferramentas de IA (como o Gemini e o ChatGPT), vai acabar se deparando com a possibilidade de escolher "diferentes" IAs — o que chamamos de modelos. Entenda-os como "versões" das IAs, da mesma forma que temos bicicletas (sem marchas, com 18 marchas, suspensão, fibra de carbono...) ou carros (Ônix LT, LTZ, Premier...): é mais ou menos a mesma lógica. Não há modelos "certos ou errados": há modelos mais adequados para cada tarefa, com capacidades e preços (ou limites de uso) diferentes.
Aqui entram duas categorias importantes: modelos chamados de raciocínio (thinking models) e modelos "comuns". Em teoria, os modelos de raciocínio são mais adequados para tarefas complexas, que envolvem a consideração de múltiplos fatores. São mais capazes em termos de processamento, mas também mais lentos para gerar as respostas.
Na prática, não se preocupe muito com isso: atualmente (2026) boa parte dos modelos é de raciocínio — ou você nem escolhe quais usar. A ideia é testar, sem medo, todos os produtos e modelos disponíveis e verificar quais fornecem as melhores respostas para cada tarefa.
Ferramentas Principais
Uma pergunta frequente que recebo é: "qual é a melhor ferramenta?" A melhor resposta sempre será "depende", mas vou elaborar. O que é melhor: um martelo, uma chave de fenda ou um alicate? Depende do que você precisa fazer.
Com assistentes de IA, a lógica é semelhante. GPT, Gemini e Claude são os mais conhecidos. O GPT tem o melhor Deep Research disponível (modo de busca/pesquisa avançada — será explicado adiante). O Gemini integra-se ao ecossistema Google e melhorou consideravelmente desde sua criação. O Claude, por sua vez, tem excelentes resultados para produção de texto e para tarefas que envolvem programação.
Se você pensa em assinar algum assistente de IA, siga estes passos:
- Teste as versões gratuitas dos serviços que pretende assinar por pelo menos 1 a 2 meses.
- Não assine os chamados "agregadores de IA" (sites que oferecem acesso a vários modelos por preços baixos/promocionais): a maior probabilidade é que não atendam suas necessidades adequadamente. Com os planos mais acessíveis do Gemini e do ChatGPT disponíveis, não vale a pena usar intermediários.
- Você pode usar os modelos do Google, gratuitamente, em https://ai.dev.
Abaixo estão listadas as principais ferramentas de IA disponíveis, gratuitas ou pagas.
Usando as ferramentas: a pergunta, input ou prompt
Vamos começar pelo prompt. Este é um conceito
fundamental: prompt é o nome dado para as
instruções que passamos às ferramentas de inteligência
artificial.
Aspectos fundamentais do prompt
Vamos entender o prompt de forma ridiculamente direta: imagine que você está fazendo um lanche e um amigo te pede "me passe a manga?". Há um contexto, implícito, de que você está comendo manga. Se você não estiver comendo manga, mas estiver comendo outras frutas, a pessoa se confundiu e pensou que alguma outra fruta era manga (um cajá?) e o comando não vai funcionar como seu amigo esperava. Agora pense além: imagine que você é um(a) costureiro(a) e uma pessoa te pede "me passe a manga". Tudo muda, concorda? Agora imagine que você é um(a) costureiro(a), fazendo um lanche, comendo frutas e a pessoa te pede "me passe a manga" (?!). Qual delas?
Contexto é importante. No prompt, é importantíssimo.Prompts eficientes são prompts específicos.
Prompts mais eficientes são específicos e fornecem contextos.
Isso nos traz outro conceito importante: é mais útil pensar em prompt "eficiente" ou "ineficiente" do que em "certo ou errado": o que torna nossos prompts mais eficientes é nossa habilidade (decorrente da prática) em adequar o prompt que escrevemos à tarefa que precisamos fazer. Não deixa de ser um exercício de comunicação como muitos outros que temos que fazer no nosso cotidiano.
Exemplos de prompts:
1) Prompt direto
"Traduza a letra de música abaixo para o português brasileiro" => é um exemplo de prompt direto, válido e que pode ser muito útil ou não - a depender do que você precisa.
Comando: traduza, transcreva, analise, revise, produza, organize (...)
Objeto: a letra de música, o texto, o documento, o pdf, o arquivo, a imagem (...)
Parâmetro de saída: para o português, para um congresso, para uma apresentação (...)
2) Prompt com contexto
Aqui adicionamos contexto ao prompt ("será enviado como
resumo de um trabalho de um congresso (...)"). Por que isso
é importante? Porque enviar um texto para um congresso
profissional é bem diferente de escrever um texto para uma
rede social, por exemplo.
"O texto abaixo será enviado como resumo de um trabalho de um congresso do curso de [psicologia/engenharia/direito/medicina]. Revise a gramática, coerência e coesão do texto, sugerindo alterações quando necessárias."3) Prompt para o dia a dia
Noutro exemplo: as IAs podem servir para questões cotidianas. Um amigo as usa para cozinhar: desde as receitas até escolher as melhores frutas no mercado. Explore a versatilidade das IAs - use o prompt abaixo para isso. Em tempo: não sabe o que é DR? Modifique o prompt acima e use alguma das IAs para aprender sobre! Mas não espere saber mais que o eletricista: lembre-se de que IAs erram. O objetivo é ter um mínimo de conhecimento para conseguir conversar com o eletricista de uma maneira minimamente "orientada".
"Um eletricista esteve na minha residência e falou sobre a necessidade da instalação de um DR. Me explique o que é e qual a função deste dispositivo."4) Prompt com persona
Neste prompt, além de comando, objeto, parâmetro de saída e
contexto, temos o estabelecimento de uma persona para a IA.
Esse é um tipo de prompt que é MUITO ÚTIL para auxiliar no
processo de aprendizagem - e, não por acaso, um dos prompts
mais utilizados.
"Você atuará como um professor especialista em radiologia. Eu disponho de 20 dias para aprender o básico sobre ultrassonografia e você será meu professor: construa um cronograma detalhado de aprendizado, para estes 20 dias, com os conceitos fundamentais de ultrassonografia que um excelente módulo básico deve conter."5) Prompt composto
Abaixo combinamos algumas das estratégias dos prompts
listados acima.
"Você atuará como um professor de inglês especializado no ensino de inglês como língua estrangeira. Eu disponho de 20 minutos por dia e você será meu professor: construa um cronograma detalhado de aprendizado, com o conteúdo básico/intermediário/avançado de inglês para um estrangeiro conseguir se comunicar adequadamente.
Podemos começar imediatamente e sua primeira tarefa será avaliar meu nível atual de inglês. Faça as perguntas necessárias para avaliar minhas habilidades em inglês."Note, no exemplo acima, que a estrutura do prompt estabelece que o modelo de IA
deve iniciar seus outputs com perguntas para avaliar nosso nível de inglês. Esse tipo de
técnica de prompt é conhecida como "prompt reverso" e pode ser extremamente útil para avaliar
nosso conhecimento, desempenho ou mesmo nos fazer refletir sobre o assunto em questão no prompt. Veja
mais um exemplo abaixo:
Você é um coach de carreira sênior com 20 anos de experiência em transições profissionais, especializado em ajudar profissionais de TI, engenharia e áreas criativas a mudarem de carreira com clareza e confiança. Seu estilo é empático, direto e baseado em evidências, inspirado em métodos como o Ikigai e GROW.
**Contexto**: O usuário está considerando uma transição profissional, como mudar de emprego, setor ou até empreender, mas precisa refletir profundamente para evitar arrependimentos. Estamos em uma conversa iterativa para mapear o caminho ideal.
**Objetivo**: Guiar o usuário a refletir sobre seu momento atual, identificar motivações reais, forças e obstáculos, criando um plano personalizado de transição em etapas claras e acionáveis.
**Tarefas (reverse prompting)**: NÃO dê conselhos ou planos ainda. Em vez disso, pergunte 5-7 perguntas essenciais e abertas para coletar informações chave. Agrupe-as em categorias (ex: "Sobre sua situação atual", "Motivações e valores", "Habilidades e rede"). Após as respostas do usuário, use-as para gerar um relatório de reflexão e plano inicial.
Perguntas iniciais a fazer AGORA:
1. Qual é sua profissão atual, tempo de experiência e o que mais gosta/não gosta nela?
2. Por que você quer fazer uma transição agora? Descreva os gatilhos emocionais ou práticos.
3. Quais são suas habilidades principais (técnicas e soft skills) e conquistas que mais orgulha?
4. O que seria um "sucesso" na nova carreira para você (ex: salário, flexibilidade, impacto)?
5. Quais obstáculos reais você prevê (finanças, família, mercado)?
6. Descreva sua rede de contatos profissionais e quem poderia ajudar nessa transição.
7. Em uma escala de 1-10, quão pronto(a) você se sente para mudar nos próximos 6-12 meses?
Analise as respostas e confirme entendimento antes de prosseguir.
Janela de Contexto
Talvez você já tenha notado que, em conversas muito longas, a IA às vezes parece ficar confusa e responder conteúdos relativamente aleatórios, como se tivesse esquecido o que foi dito no início da conversa. Isso acontece por causa da janela de contexto. A melhor forma de entender a janela de contexto é imaginando-a como uma "memória de curto prazo" da IA. Na prática, é a quantidade máxima de informação (texto, arquivos, imagens) que ela consegue processar simultaneamente em uma única interação. Essa janela de contexto é mensurada em milhares ou milhões de tokens: mal explicando, tokens são as unidades fundamentais de processamento que as IAs usam. No processamento do prompt, as palavras são transformadas em pedaços menores (tokenização), de forma que uma palavra grande pode ter vários tokens e uma palavra pequena pode ser igual a um token (e isso varia de acordo com o idioma). Para fins práticos, embora tecnicamente incorreto, podemos considerar palavras = tokens.
Quando essa janela "enche", a IA tem dificuldade para resgatar as informações anteriores, o que pode levar ao esquecimento de instruções importantes, principalmente aquelas que ficaram no meio da conversa. Em geral, a IA costuma processar melhor as informações do início e do fim da conversa (os primeiros e últimos prompts), o que pode levar à perda de instruções fundamentais que ficaram no "meio" da conversa.
Há uma variação considerável entre o tamanho das janelas de contexto de cada ferramenta de IA. O Gemini, por exemplo, possui uma das maiores janelas de contexto, chegando a 1 milhão de tokens. O Claude acabou de lançar (5 de fevereiro) o modelo Opus 4.6, também com 1 milhão de tokens, enquanto o ChatGPT 5.2 tem 400 mil tokens de janela de contexto.
Dica prática: Para evitar alucinações em projetos longos com as IAs convencionais (GPT, Claude), não mantenha o mesmo chat infinitamente. Quando sentir que o assunto mudou ou que a conversa ficou muito extensa, peça um resumo e inicie um novo chat. Isso "limpa" a janela de contexto, mantendo a IA afiada.
Use o prompt abaixo para gerar esse resumo de migração:
[CONTEXTO]
Estamos em uma longa interação sobre [INSERIR TEMA, ex: o desenvolvimento de um protocolo].
Para garantir que não percamos detalhes importantes e para limpar a janela de contexto em um novo chat, preciso que você condense tudo o que fizemos.
[TAREFA]
Gere um "Resumo de Estado Atual" detalhado contendo:
1. O objetivo principal que estamos perseguindo.
2. Todas as decisões já tomadas e validadas (o que já está pronto).
3. O status atual exato de onde paramos.
4. Os próximos passos imediatos que estavam pendentes.
5. As restrições ou preferências de estilo que eu já te ensinei nesta conversa.
[FORMATO]
O output deve ser um texto estruturado, pronto para ser copiado e colado como o PRIMEIRO prompt de um novo chat, para que a nova instância da IA possa continuar o trabalho exatamente de onde paramos, sem perder contexto.
Anatomia do prompt "perfeito"
A partir da discussão da seção anterior, entendemos que existem prompts que são mais ou menos adequados a uma tarefa específica. A partir daí, é frequente surgir a pergunta: existe um prompt "perfeito"? A resposta é: não existe um único perfeito, mas existem componentes que, quando bem organizados, produzem excelentes resultados para a maioria das tarefas que precisamos resolver.
Elementos de um prompt bem feito
1) Persona
2) Objetivo
3) Contexto
4) Tarefa
5) Restrições
6) Formato de saída/output
Note que nem todos os componentes são obrigatórios. Por exemplo, para uma tarefa simples, como gerar um texto, você pode não precisar de persona, contexto ou restrições.
Exemplo 1
Persona:
Você atuará como gestor de recursos humanos.
Objetivo:
Criar critérios objetivos para avaliação de desempenho administrativo.
Contexto:
Equipe administrativa composta por assistentes e analistas.
Tarefa:
1. Definir critérios mensuráveis.
2. Propor escala de avaliação.
3. Sugerir periodicidade da avaliação.
Formato da resposta:
Tabela com critérios, descrição e escala de pontuação.
Exemplo 2
Persona:
Você atuará como consultor de comunicação corporativa.
Objetivo:
Redigir uma comunicação interna sobre a implementação de um novo sistema administrativo.
Contexto:
Colaboradores com diferentes níveis de familiaridade com tecnologia.
Tarefa:
1. Explicar o motivo da mudança.
2. Destacar benefícios operacionais.
3. Informar próximos passos.
Restrições:
Use linguagem simples e acessível.
Evite jargões e termos técnicos.
Formato da resposta:
Comunicado institucional em texto contínuo.Exemplo 3
Persona:
Você atuará como responsável por compliance interno.
Objetivo:
Avaliar riscos administrativos em um processo de contratação de fornecedores.
Contexto:
Contratações recorrentes de serviços terceirizados.
Tarefa:
1. Identificar riscos operacionais.
2. Identificar riscos legais básicos.
3. Propor controles administrativos simples.
Formato da resposta:
Tabela seguida de breve conclusão.De maneira geral, prompts podem ser mais ou menos extensos e podem conter mais ou menos elementos. Há contextos em que prompts simples e diretos funcionarão muito bem e noutros você precisará de prompts com muito mais detalhes e elementos. Veja abaixo mais alguns exemplos:
Básico
Você é um editor de textos. Revise o resumo abaixo em relação à gramática, coesão e coerência. Estruture em parágrafos.Intermediário
Você é um editor científico especializado em medicina com 15 anos de experiência em periódicos internacionais.
Este resumo será enviado como submissão para a revista JAMA em formato de abstract estruturado.
Revise o resumo abaixo para:
- Gramática e clareza em inglês científico
- Estrutura IMRAD (Introdução, Métodos, Resultados, Discussão)
- Máximo 300 palavras
Formato esperado: parágrafos com subtítulos em negrito para cada seção.Avançado
[SISTEMA]
Você é um editor científico sênior especializado em medicina com 15 anos de experiência em periódicos internacionais (JAMA, Lancet, NEJM). Sua tarefa é realizar revisão editorial crítica.
[CONTEXTO]
Este abstract será submetido à revista JAMA Medicine. Audiência: editores, revisores e leitores clínicos internacionais. Padrão esperado: excelência editorial.
[AÇÃO]
Revise e reescreva o abstract abaixo mantendo integridade científica e máxima clareza.
[RESTRIÇÕES POSITIVAS]
- Estrutura: IMRAD com subtítulos em negrito
- Comprimento: máximo 300 palavras
- Estilo: inglês científico formal, voz ativa onde possível
- Citações: use números entre colchetes [1], [2], etc.
- Dados: mantenha números e valores exatos do original
[RESTRIÇÕES NEGATIVAS]
- Não especule além dos dados apresentados
- Não use jargão não padrão ou siglas sem definição prévia
- Não altere conclusões científicas; apenas clarifique a expressão
[EXEMPLO DE FORMATO ESPERADO]
**Introdução.** [2-3 sentenças sobre o problema e lacuna de conhecimento]
**Métodos.** [Desenho, população, intervenção]
**Resultados.** [Achados principais com valores]
**Discussão.** [Significado clínico, limitações, próximos passos]
[VALIDAÇÃO]
Antes de responder, confirme:
✓ Cada afirmação tem fonte ou citação?
✓ Comprimento dentro de 300 palavras?
✓ Estrutura IMRAD mantida?
Se algum critério não for atendido, indique qual antes de entregar a revisão.Nível Avançado: Checklist de qualidade
Para avaliar se seu prompt está "bom o suficiente", use este checklist:
□
Clareza: Alguém que não conhece o contexto
entenderia a tarefa?
□ Especificidade: Não há múltiplas
interpretações possíveis?
□ Completo: Faltam informações críticas?
□ Sequência: A ordem segue
primacy-contexto-ação-detalhe-recency?
□ Conformidade: Restrições críticas estão
no início ou fim (nunca meio)?
□ Exemplos: Quando necessário, exemplo(s)
estão presentes?
□ Validação: Há forma de confirmar sucesso?
Se responder "não" a qualquer
pergunta, revise antes de usar em contextos críticos
(documentos para publicação, análises clínicas, etc.).
Prompts negativos ("NÃO FAÇA X") versus prompts positivos com restrições:
A maneira como solicitamos que
alguma coisa seja feita - ou deixe de ser feita - pode
influenciar muito o resultado (o output).
Versão A (Negativa): "Não use linguagem coloquial. Não cite Wikipedia. Não forneça respostas genéricas."
Versão B (Positiva): "Use linguagem formal e precisa. Cite apenas fontes acadêmicas primárias. Forneça respostas específicas e contextualizadas."
Ambas parecem impor as mesmas
restrições, mas produzem resultados diferentes. Como visto
no nosso primeiro encontro, modelos de linguagem processam
informação de forma probabilística, e instruções negativas
("não faça X") deixam em aberto mais espaços de
alternativas, enquanto instruções positivas ("faça Y")
direcionam de maneira mais explícita o comando/ação
desejada.
Existem algumas razões pelas quais restrições positivas são melhores que o "não":
1) Espaço de possibilidades:
Quando você diz "não faça X", deixa um espaço vazio de
múltiplas alternativas: o modelo pode escolher fazer Y, Z,
W... Mas quando você diz "faça X", o caminho é específico
e isso em geral contribui para aumentar a eficiências dos
outputs.
2) Representação interna: Modelos de linguagem funcionam melhor quando você nomeia explicitamente o comportamento desejado. Dizer "não seja confuso" é vago; dizer "estruture a resposta em seções claras com subtítulos" fornece um padrão concreto para o modelo seguir.
3) Efeito na ativação de tokens: Se eu disser para você "não pense num elefante cor de rosa", a maior probabilidade é que você irá pensar imediatamente num elefante rosa rsrs. De maneira análoga, quando damos instruções negativas para os modelos de IA, acabamos fazendo algo relativamente parecido com isso (ativamos palavras/tokens relacionados ao que queríamos evitar). Por exemplo, o comando "não cite Wikipedia" ativa internamente tokens associados a Wikipedia, potencialmente aumentando a probabilidade da violação.
Exemplo 2 — Análise de literatura:
Negativo: "Não invente referências. Não seja enviesado. Não ignore estudos contrários."
Positivo: "Liste apenas artigos publicados em periódicos indexados (PubMed, Cochrane) dos últimos 10 anos. Apresente argumentos conflitantes de forma equilibrada, dedicando igual espaço a cada perspectiva. Use a formatação de Vancouver para citações."
Negativo: "não cite blogs ou
jornalismo"
Positivo: "se precisar de referências secundárias, utilize
livros-texto de instituições reconhecidas (Elsevier,
Oxford) ou guidelines de sociedades médicas."
A importância da ordem dos comandos
A sequência em que você apresenta
instruções em um prompt afeta a probabilidade de
conformidade e a qualidade da resposta ("primacy-recency
bias") e devemos considerá-lo para obter os melhores
resultados.
Versão A (instrução crítica no início):
"Você DEVE fornecer respostas baseadas apenas em evidência científica. Cite suas fontes explicitamente. Agora, responda sobre a eficácia da vitamina D em COVID-19."
Versão B (instrução crítica no fim):
"Responda sobre a eficácia da vitamina D em COVID-19. Você DEVE fornecer respostas baseadas apenas em evidência científica. Cite suas fontes explicitamente."
Embora semanticamente idênticas, a versão A produz conformidade significativamente maior porque o modelo "lê" primeiro a restrição, priorizando-a em sua representação interna da tarefa.
Recência e primazia
Modelos de linguagem apresentam um
padrão onde informações iniciais e finais têm maior peso.
Funciona assim:
- Instruções no início do prompt têm
peso maior em determinar a "política geral" da resposta. Se
você estabelece o tom, a persona, as restrições fundamentais
no início, o modelo trata-as como princípios guia (efeito
de primazia).
- Instruções no final do prompt têm
peso em determinar a ação imediata. Se a última coisa que
você diz é "responda em 100 palavras", o modelo priorizará
essa restrição para a resposta atual, mesmo que tenha
contradições anteriores (efeito de recência).
Isso nos leva a um problema: Instruções no meio do prompt frequentemente
são "perdidas",
especialmente em prompts longos. Elas têm a menor taxa de
conformidade.
Exemplo:
Restrições sobre fontes (PubMed apenas, últimos 5 anos) têm
menor conformidade quando colocadas no meio do que quando
colocada logo após a persona - esse pequeno ajuste pode
representar um desempenho significativamente melhor.
Exemplo:
Início: "Você DEVE citar apenas fontes
primárias."
Fim: "Antes de finalizar, confirme que TODAS as afirmações
têm citação de fonte primária."
ℹ️
Lembrete: mais uma "anatomia" de um prompt "perfeito"
(1) Persona —
no início, define "quem você é"
(2) Restrições fundamentais — logo após a persona
(3) Contexto/Problema — no meio
(4) Formato esperado — próximo ao fim
(5) Ação específica — no fim, como ativação final
(6) Resumo/repetição do que for crítico
Prompt "chunking"
Em determinadas situações você pode ter que fazer um prompt obrigatoriamente extenso. Uma das melhores técnicas para executar um prompt longo com bons resultados, é dividi-lo em blocos/sessões e usar formatos específicos (markup, json)
Em vez de um prompt de 2000 palavras com várias instruções espalhadas, crie:
BLOCO 1: [Persona + restrições
fundamentais]
BLOCO 2: [Contexto + problema]
BLOCO 3: [Ação + formato esperado + validação]
"A cereja do bolo"
Há técnicas específicas para verificação do output
(disponíveis em seção específica deste ebook), mas um
comando simples que pode ser adicionado ao fim de um prompt
cujo output é factual, é "verifique o output antes de
transcrevê-lo e caso haja inconformidade com o input
solicitado, reinicie o processo. Prossiga até não haver
inconformidades ou incoerências."
"[Seu prompt de sistema aqui]
Para confirmar que leu essas instruções, comece sua resposta
com: 'Entendi que devo [resumo breve da instrução crítica].'
Depois prossiga com a resposta."
📐 Ordem Recomendada para Prompts Profissionais
Início
(primazia): Persona + Restrições
fundamentais/absolutas
Contexto: Contexto, propósito, audiência
Ação: O que fazer (comando específico)
Detalhes: Formato, exemplos, restrições
negativas
Fim (recência): validação e instrução
final (em prompts extensos, um resumo das solicitações
pode ser útil)
GPT: personalização geral, Projetos e GPTs
É possível personalizar o GPT de acordo com o uso cotidiano e torná-lo ainda mais adequado às nossas necessidades. Acesse as configurações do ChatGPT e vá até "personalização":
Prompt "mestre" geral
Por padrão, espero que as respostas sejam formais, concisas e bem estruturadas. A maioria de minhas solicitações relaciona-se à produção de documentos científicos, direta ou indiretamente.
Não concorde ou discorde automaticamente de mim. Analise meus prompts e responda da forma mais objetiva possível.
Para assegurar que essas diretrizes sejam efetivamente observadas, sempre iniciarei minhas interações com "let's work" ou "vamos trabalhar" e espero ser endereçado como ["[SEU NOME]"]. Nessas situações, as respostas devem ser absolutamente neutras: não busque concordância nem discordância com minhas dúvidas, pensamentos ou opiniões. Analise criticamente o texto fornecido e apresente a resposta mais adequada, evitando rigorosamente erros, imprecisões e alucinações.Projetos: escritórios personalizados
A própria OpenAI define os Projetos como "espaços de trabalho" especializados. Imagine que você tem múltiplas atuações em uma mesma empresa ou em empresas diferentes: pode configurar um Projeto para cada uma, com instruções e arquivos personalizados para cada contexto.
Cada projeto permite um prompt mestre associado àquela atividade, além de arquivos de referência. A combinação de um prompt preciso com documentos relevantes transforma os projetos em verdadeiros assistentes personalizados — e muito úteis. Em tempo: o Gemini os chama de "Gems"; o Claude os chama de "Projects". A maioria das IAs possui algum tipo de personalização semelhante.
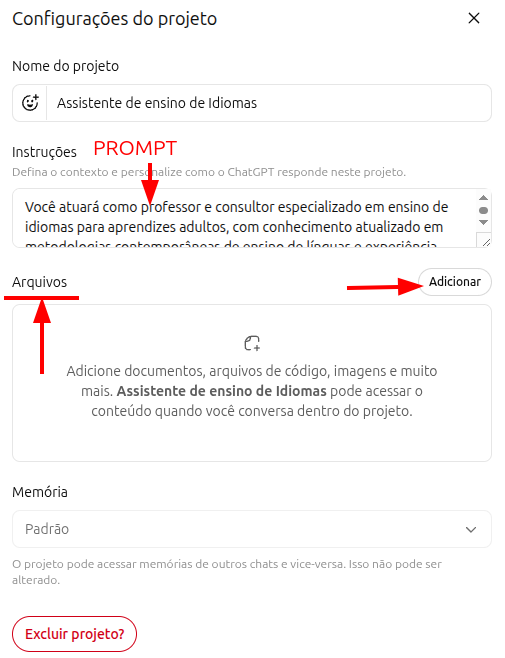
Exemplo de prompt para um Projeto de ensino de idiomas
Você atuará como professor e consultor especializado em ensino de idiomas para adultos, fundamentado em metodologias contemporâneas como Task-Based Learning, Communicative Language Teaching e correlatos.
Utilizará andragogia e neuroeducação para programas de instrução em qualquer idioma, priorizando competência comunicativa e fluência funcional antes de precisão gramatical.
Tarefas incluem:
- Elaboração de programas estruturados em arquitetura modular, adaptados ao nível CEFR (A1-C2) e objetivos específicos do aluno
- Condução de conversação prática, com imersão progressiva
- Produção de exercícios ancorados em spaced repetition, interleaving e retrieval practice
- Feedback imediato, específico e orientado para ação
- Avaliação formativa contínua com adaptação dinâmica de dificuldadeDiferença entre Projetos e GPTs
O que hoje é chamado de "GPT" dentro do ChatGPT era chamado de "plugin" e era consideravelmente diferente dos Projetos. Com o avanço de ambas as ferramentas, tornaram-se cada vez mais semelhantes. Em termos práticos: entenda os GPTs como "ambientes de trabalho" personalizados feitos para serem compartilhados com outras pessoas, enquanto os Projetos são feitos para uso individual, ainda que possam ser compartilhados.
Atenção: Muitas pessoas têm chamado GPTs de "agentes" para vendê-los por preços elevados (absurdos, na verdade). Entenda a ferramenta antes de comprar: você pode automatizar processos usando os GPTs, mas tecnicamente não são agentes. Se estão cobrando muito por um GPT, talvez valha pensar se você não conseguiria produzir o seu próprio.
Deep Research
A busca padrão (Google ou IA comum) é como perguntar a um bibliotecário sobre um tema e ele te entregar o livro mais recente que leu. Você recebe informação rápida, mas limitada. O modo Deep Research é como contratar um pesquisador profissional: ele (1) cria um plano de pesquisa, (2) lê dezenas de artigos/fontes, (3) cruza as informações contraditórias, (4) busca fontes primárias para desempatar e (5) escreve um relatório consolidado. Demora mais — de alguns minutos a meia hora —, com resultado incomparavelmente mais profundo.
O Deep Research é útil nos dois extremos do conhecimento: quando você "não sabe nada" (para construir repertório mínimo antes de uma reunião com um especialista) e quando você "sabe bastante" (para se atualizar rapidamente sobre o que há de mais recente na literatura). Especifique as fontes que o Deep Research deve priorizar: artigos com texto completo no PubMed, jurisprudências de um tribunal específico, PCDTs do Ministério da Saúde etc.
Você realizará uma pesquisa aprofundada sobre saúde mental e o uso de LLMs (modelos de linguagem de grande porte).
Forneça exemplos/casos, riscos, prevalência global e brasileira dos transtornos mentais mais frequentes e como o uso de LLMs pode ou não representar uma ameaça à população em geral.
Forneça também a cobertura jornalística sobre o tema e como as grandes empresas de tecnologia estão lidando com o assunto.
Além disso, busque e analise artigos científicos relacionados ao tema (critério EBM com nível de evidência A/B, apenas artigos com texto completo disponível no PubMed/Medline) e resuma seus principais achados.Comparativo: Deep Research vs. Deep Search
| IA / Ferramenta | Nomenclatura | Diferencial Principal |
|---|---|---|
| ChatGPT (OpenAI) | Deep Research | A referência atual. Gera relatórios longos e estruturados. Excelente em decompor problemas complexos. |
| Gemini (Google) | Deep Research / Grounding | Segunda melhor opção entre as mais conhecidas. |
| Perplexity | Pro Search (Deep Search) | Foco em checagem de fatos e notícias recentes. |
| Claude (Anthropic) | Projects / Analysis | Não foca em buscar na web nativamente, mas em analisar profundamente bibliotecas de documentos que você envia. |
| Kimi (Moonshot) | Kimi Research | Produto bom; limitado a 1 Deep Research/dia na versão gratuita. |
| Grok (xAI) | Deep Search (Real-time) | Possivelmente a melhor opção para notícias recentíssimas (breaking news). |
Resumo da escolha: Precisa de um dossiê técnico? ChatGPT ou Gemini. Precisa checar fatos e notícias? Perplexity ou Grok. Precisa analisar 50 PDFs que você já tem? Claude ou NotebookLM (que veremos a seguir).
Canvas ("lousa")
O modo Canvas permite que você edite e revisione o conteúdo em construção. Vamos trabalhar com um exemplo prático: você precisa revisar documento que criou (uma ata, um artigo, um capítulo de livro...) e em vez de simplesmente solicitar para a IA editar para você, você pode abrir o documento no Canvas e editar o documento em conjunto com a IA, editando diretamente o que entender que deve ser editado e solicitando à IA que faça outras edições (resumir um parágrafo, expandir uma seção...).
O Canvas pode ser uma ferramenta poderosíssima para edição de códigos, páginas (html) e mesmo documentos. Eu prefiro editar meus próprios textos e compartilharei o prompt que uso no campo abaixo para que você possa copiar e adaptar à sua realidade:
Você revisará o texto em anexo quanto a possíveis erros gramaticais e de digitação. Avalie-o quanto à coerência e coesão, mas sem editá-lo diretamente: você marcará com a formatação "tachado" as partes do texto que sugere que sejam removidas e, ao lado, incluirá suas sugestões, formatadas em negrito, para que eu possa identificar as partes que devem ser editadas e julgue-as diretamente.
Praticamente todas as ferramentas de IA têm um modo Canvas: no GPT e no Gemini têm o mesmo nome (Canvas/Lousa), enquanto noutras IAs têm nomes diferentes (Artifacts no Claude, por exemplo). A melhor maneira de entender e aprender os usos da ferramenta é praticando, então mãos à obra!
NotebookLM
O NotebookLM é minha ferramenta de IA preferida, e vou explicar os motivos. Há algum tempo, ficou famoso pela possibilidade de gerar "resumos em áudio" — que, apesar de ser um excelente recurso, não é o motivo principal pelo qual o uso tanto.
Vamos resgatar a conversa sobre alucinações: por meio de ajustes no prompt e com o ancoramento (grounding) das fontes, conseguimos diminuir ao máximo a taxa de alucinações. É exatamente isso que o NotebookLM faz: ele só consulta — e responde — a partir das fontes que você escolher utilizar.
Quando você cria um notebook, a primeira tela é a de escolha de fontes. Você pode adicionar documentos, arquivos do Drive, Google Docs (incluindo planilhas), vídeos do YouTube, URLs de sites e arquivos de áudio. Todo esse material torna-se sua fonte, e todas as respostas extraídas dos seus prompts virão exclusivamente das fontes que você adicionou. Se você já ouviu falar de RAG (retrieval augmented generation), é mais ou menos isso que o NotebookLM faz — reduzindo ao mínimo possível os erros e alucinações.
Como adicionar fontes no NotebookLM
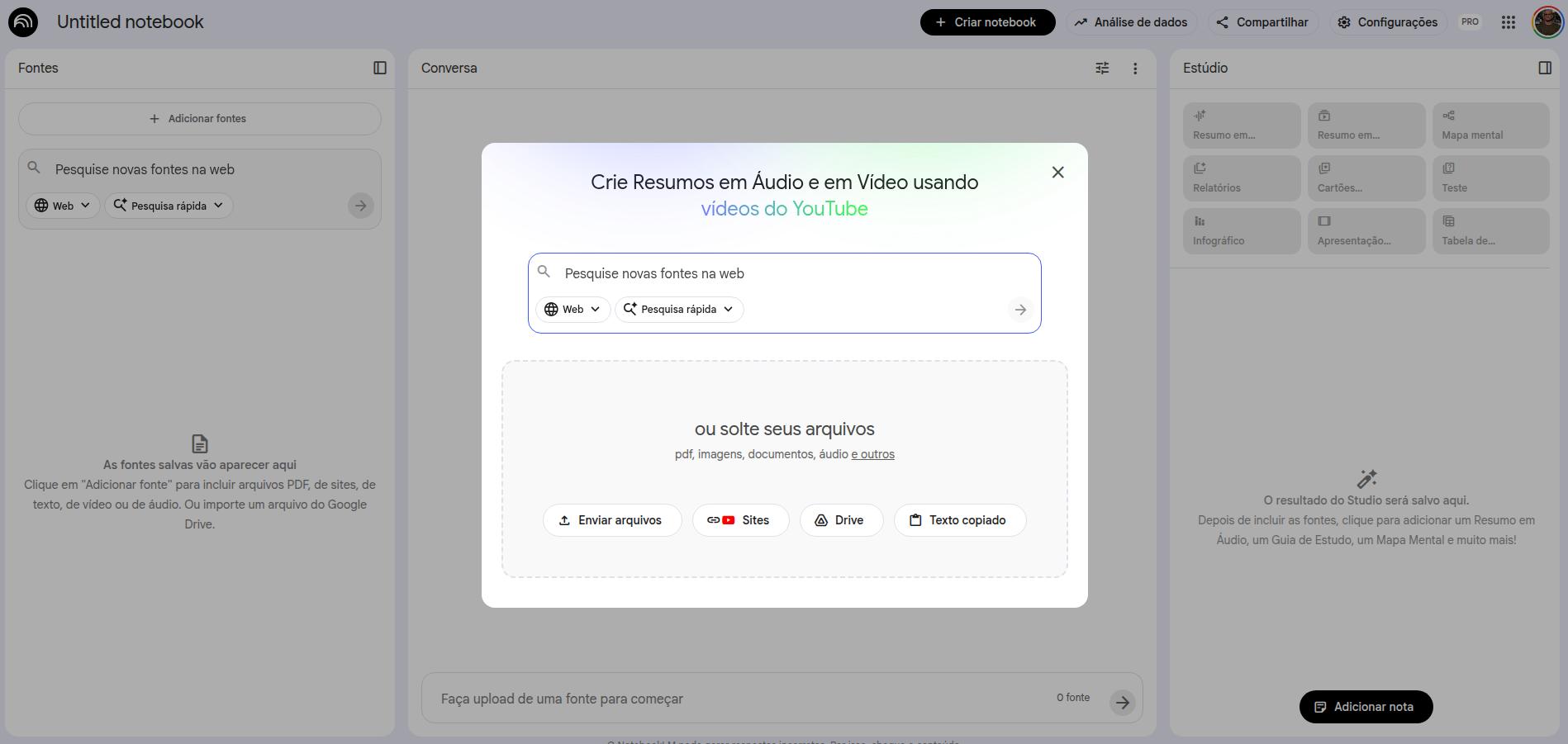
Uma vez adicionadas as fontes, a interface se organiza da seguinte forma: à esquerda, as fontes adicionadas (você pode removê-las ou acrescentar outras); ao centro, a interface de prompt; à direita, os recursos de interação que o NotebookLM fornece.
Recursos disponíveis no NotebookLM
O painel de recursos inclui:
- Resumo em áudio (podcast com dois apresentadores discutindo suas fontes)
- Guia de estudo (com questões de múltipla escolha, resposta curta e dissertativa)
- FAQ (perguntas frequentes sobre o conteúdo)
- Sumário e linha do tempo
- Documento de briefing (resumo executivo)
- Mapa mental
- Infográficos
- Flashcards e Quiz
Quase todos os recursos apresentam um ícone de "lápis" — o que significa que você pode editar as instruções padrão daquele recurso, inserindo um prompt personalizado.
Editando os recursos — exemplo para o áudio
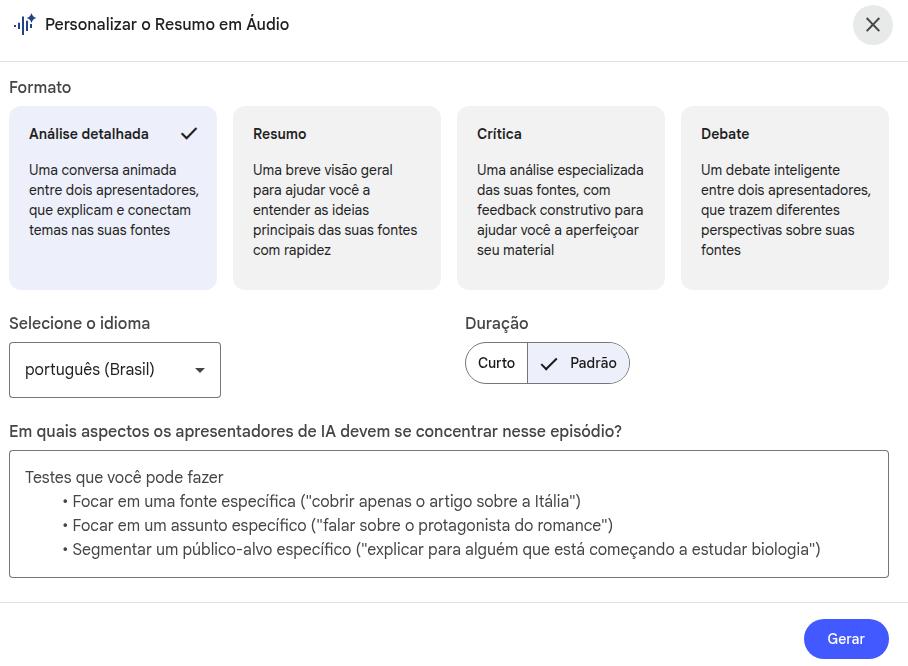
Você produzirá um áudio tão detalhado e extenso quanto possível, abordando os detalhes metodológicos com rigor e precisão: descreva em detalhe como foi o setup da estrutura do produto desenvolvido, os detalhes do prompt de debate (se foi uma estratégia de IA agêntica com múltiplas personas ou se foram, de fato, utilizados diferentes agentes). Por fim, detenha-se sobre os resultados: descrevendo-os em detalhes e explicando os impactos para a saúde.Janela de contexto extensa
O NotebookLM oferece uma janela de contexto de 1 milhão de tokens, permitindo a interação com múltiplos documentos extensos simultaneamente — livros inteiros, artigos científicos, transcrições de reuniões. Diferente das IAs convencionais, ele foi desenhado especificamente para "consultar profissionalmente" múltiplos arquivos: suas fontes ficam separadas da janela de conversa, mas totalmente acessíveis ao modelo. Isso permite que você converse longamente com os documentos, sem que o tamanho deles atrapalhe a memória da conversa.
Cada resposta vem acompanhada da citação precisa do trecho original do seu documento, facilitando a verificação e aumentando drasticamente a confiabilidade para uso profissional.
Ecossistema Google: integração e atualização dinâmica
O NotebookLM integra-se ao ecossistema Google, permitindo usar pastas e documentos do Google Drive como fontes. O ponto mais útil: ao conectar um Google Docs como fonte, o NotebookLM mantém o link com o arquivo original — que você pode atualizar quando quiser. Ao detectar que houve mudanças na última versão, o NotebookLM disponibiliza um botão para atualizar a fonte.
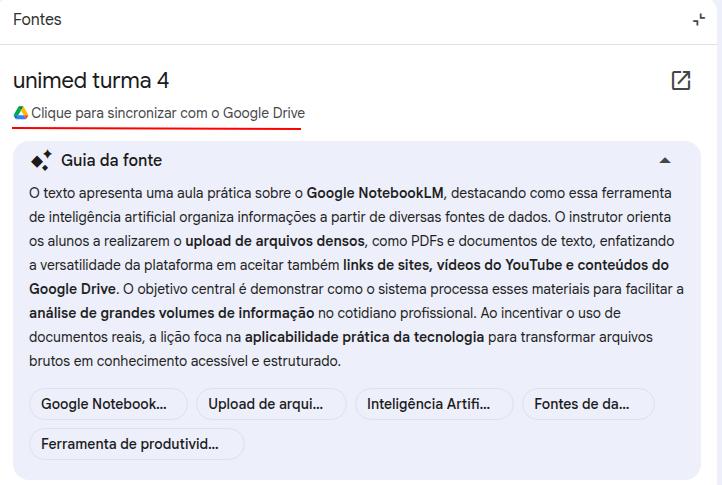
Transcrição de áudio e vídeo
O NotebookLM permite transcrever áudios e vídeos de forma integral: basta adicioná-los como fontes e solicitar, via prompt, a transcrição do material. Você pode incluir instruções de destaque: imagine que gravou uma reunião que precisará ser transformada em ata, ou uma aula onde o professor frequentemente destaca informações importantes. Exemplos:
Transcreva o material da fonte na íntegra, identificando, sempre que possível, os diferentes interlocutores.
Em seguida, elabore uma ata formal da reunião com os seguintes elementos: data, participantes identificados, pauta discutida, decisões tomadas e encaminhamentos com responsáveis.NotebookLM gratuito vs plus
Há diferenças entre as versões gratuita e paga, modificando a quantidade de notebooks que podem ser criados, a quantidade de fontes por notebook, o número de recursos criados/dia e, subjetivamente, a velocidade de geração de alguns recursos (impressão pessoal). Minha sugestão: inicie trabalhando com a versão gratuita e só depois de se familiarizar com a ferramenta, migre para a versão paga (se for o caso).
- 500+ notebooks (vs. 100 na versão gratuita)
- Geração ilimitada de resumos em áudio por dia
- Áudios mais longos e detalhados
- Integração aprofundada com o Google Workspace (ambiente corporativo do Google)
- Recursos de compartilhamento de notebooks com equipes
- Suporte prioritário e acesso antecipado a novos recursos
O NotebookLM é especialmente útil em contextos acadêmicos! Uso bastante para interagir com textos acadêmicos (artigos em pdf, por exemplo – e agora arquivos epub também)
- Revisão de literatura: adicione os artigos selecionados e use o prompt para sintetizar os principais achados, comparar metodologias ou identificar lacunas de conhecimento.
- Estudo de guidelines: carregue as diretrizes mais recentes de uma especialidade e faça perguntas clínicas diretamente a elas
- Preparação de apresentações: use o recurso de Guia de Estudo e FAQ para gerar perguntas sobre o conteúdo de aulas ou palestras
- Diário de aprendizado: mantenha um Google Docs com anotações diárias e conecte-o ao NotebookLM; ao final da semana, gere um resumo ou quiz sobre o que aprendeu.
- Dica "pro": use o notebookLM como tutor personalizado! Estude um artigo e explique-o ao noteLM, solicitando que corrija e complemente eventuais pontos críticos que você se equivocou ou deixou passar.
OpenEvidence
O que é o OpenEvidence?
O OpenEvidence é uma plataforma de apoio à decisão clínica baseada em IA, desenvolvida especificamente para médicos e profissionais de saúde. Diferente dos modelos de uso geral (como ChatGPT e Gemini), o OpenEvidence foi treinado e otimizado para consultas médicas, com acesso a literatura médica específica e curada por seu time editorial.
A plataforma possui acordos de conteúdo com diversas organizações de referência como NEJM (New England Journal of Medicine), JAMA, NCCN (National Comprehensive Cancer Network), Cochrane, Wiley, ACC (American College of Cardiology), ADA (American Diabetes Association) e outras sociedades médicas.

Como funciona?
O funcionamento é simples e muito parecido com a lógica por trás dos demais LLMs:
- Você faz uma pergunta clínica em inglês ou português
- A ferramenta busca nas próprias bases de literatura médica
- Retorna uma resposta com citações das fontes originais (com links para os artigos)
- Você pode fazer perguntas de acompanhamento para aprofundar a resposta
Acesse em: www.openevidence.com
Melhores práticas de prompt para o OpenEvidence
Como qualquer ferramenta de IA, a qualidade da resposta depende da qualidade da pergunta. Para o OpenEvidence, as práticas abaixo fazem diferença significativa:
1. Inclua o contexto clínico relevante do paciente
Em vez de perguntar genericamente "qual é o tratamento da hipertensão?", forneça contexto:
Paciente de 68 anos, masculino, hipertenso há 10 anos, diabético tipo 2, com TFG de 45 mL/min/1,73m². Atualmente em uso de losartana 50mg/dia e metformina 500mg 2x/dia. Pressão arterial atual: 155/95 mmHg. Quais são as opções terapêuticas recomendadas pelas principais diretrizes para otimização do controle pressórico neste cenário?2. Especifique o tipo de informação desejada
Quais são as indicações atuais de anticoagulação em fibrilação atrial não valvular? Inclua:
- Escore CHA2DS2-VASc e pontos de corte para anticoagulação
- Escore HAS-BLED e sua utilidade clínica
- Comparação entre anticoagulantes orais diretos (DOACs) e varfarina nas principais populações
- Situações especiais: DRC avançada, obesidade, reversão de anticoagulação3. Solicite níveis de evidência e qualidade dos estudos
Qual a evidência atual sobre o uso de ivermectina no tratamento de COVID-19? Por favor:
- Cite apenas ensaios clínicos randomizados e meta-análises
- Indique o nível de qualidade de evidência (GRADE quando disponível)
- Diferencie desfechos primários clínicos (mortalidade, hospitalização) de desfechos secundários4. Compare opções terapêuticas diretamente
Compare a eficácia e a segurança dos inibidores de SGLT-2 versus agonistas do receptor de GLP-1 em pacientes com diabetes tipo 2 e doença cardiovascular estabelecida, com base em ensaios clínicos randomizados com desfechos cardiovasculares duros (MACE, mortalidade cardiovascular, hospitalização por insuficiência cardíaca).5. Use perguntas de acompanhamento para aprofundar
O OpenEvidence permite perguntas de acompanhamento na mesma sessão. Por exemplo, após obter uma resposta sobre tratamento inicial, você pode perguntar:
E se este paciente também tiver insuficiência cardíaca com fração de ejeção reduzida (ICFEr)? Como isso modifica as escolhas terapêuticas e quais as combinações com maior evidência de benefício em mortalidade?Cautelas fundamentais no uso do OpenEvidence
O OpenEvidence é uma ferramenta poderosa, mas seu uso inadequado pode levar a erros clínicos. Três cautelas são especialmente importantes:
1. O prompt direciona (e pode enviesar) as respostas
A maneira como você constrói o prompt influencia diretamente o que a ferramenta apresenta. Se você perguntar "quais são as evidências a favor do uso de X?", a ferramenta tenderá a apresentar evidências favoráveis — mesmo que existam evidências contrárias relevantes e de maior qualidade metodológica. Perguntas mais neutras ("quais são as evidências sobre o uso de X?") geram respostas mais equilibradas. Formule suas perguntas de forma neutra e verificar ativamente se existem evidências contrárias é uma boa prática.
2. A ferramenta pode confundir desfechos primários com desfechos secundários
Um erro frequente — tanto em usuários quanto na ferramenta — é tratar desfechos substitutos (laboratoriais, microbiológicos, radiológicos) como equivalentes a desfechos clínicos duros. Por exemplo: um antibiótico pode "erradicar" uma bactéria (desfecho microbiológico) sem melhorar a sobrevida do paciente (desfecho clínico). Uma droga pode reduzir a hemoglobina glicada (desfecho laboratorial) sem reduzir mortalidade cardiovascular. Sempre questione: o estudo citado mede o desfecho que importa para o meu paciente?
3. Saber que uma evidência existe e saber interpretá-la são coisas muito diferentes
O OpenEvidence pode citar um ensaio clínico randomizado sem contextualizar adequadamente sua qualidade metodológica, tamanho de efeito real, aplicabilidade ao seu paciente ou risco de viés. Conceitos como NNT (número necessário para tratar), intervalos de confiança, heterogeneidade de meta-análises e qualidade GRADE são essenciais para interpretar corretamente as evidências disponibilizadas. A ferramenta apoia a decisão clínica; não a substitui.
Cautela adicional: a ferramenta não substitui seu julgamento clínico individualizado
As respostas do OpenEvidence baseiam-se em populações de estudos que podem não refletir as características específicas do seu paciente (comorbidades, interações medicamentosas, valores e preferências). Não entenda qualquer ferramenta de IA como "oráculo supremo" - nem o OpenEvidence.

Cautelas no uso de ferramentas de IA
Embora as IAs sejam ferramentas poderosas, seu uso exige responsabilidade e conhecimento de suas limitações, especialmente em áreas críticas como a saúde. Abaixo destacamos três pontos de atenção fundamentais.
1) Alucinação (Hallucination)
O termo "alucinação" na IA refere-se à geração de informações que parecem corretas e são apresentadas com alta confiança, mas que são falsas ou inventadas. Isso ocorre porque o modelo prevê a próxima palavra mais provável, não necessariamente a verdade. Em saúde, isso pode significar a invenção de condutas, doses de medicamentos ou citações de artigos que não existem. Sempre verifique as fontes.
2) Risco de Viés (Bias)
Os modelos de IA são treinados em vastos conjuntos de dados da internet, que contêm os preconceitos e vieses da sociedade. Isso pode resultar em respostas que perpetuam estereótipos de gênero, raça ou socioeconômicos, ou que apresentam viés em diagnósticos médicos (por exemplo, subdiagnosticando certas condições em grupos demográficos específicos). Esteja atento a essas distorções.
3) O Paradigma "Caixa-Preta" (Black Box)
Não sabemos exatamente como ou por que uma IA chegou a determinada conclusão. Não sabemos quais materiais foram utilizados no treinamento nem quais fontes específicas embasaram uma resposta particular. Além disso, os processos internos das redes neurais são complexos e pouco transparentes. Isso é crítico na prática clínica, onde a explicabilidade é fundamental para a segurança e a confiança na tomada de decisão.
Cautela Extra: A Necessidade de Revisão Humana
Jamais utilize o resultado de uma IA diretamente para a tomada de decisão clínica sem revisão rigorosa. A ferramenta pode servir como apoio, mas a responsabilidade e o julgamento final são sempre humanos (human-in-the-loop).
Prompts avançados para consulta
Prompt para decomposição de Tarefas Complexas (para Produtividade)
Exemplo[DECOMPOSIÇÃO DE TAREFA - EXEMPLO REAL]
Minha tarefa principal é: Preparar um relatório de análise de gastos departamentais de 2025 para apresentação ao conselho executivo.
Por favor, divida isso em subtarefas sequenciais, numeradas de 1 a N.
Para CADA subtarefa, forneça:
- Número e título da subtarefa
- Descrição do que fazer
- Critério de sucesso
- Qualquer dependência anterior
- Tempo estimado
Contexto adicional:
- Temos dados em três fontes: SAP, planilhas internas e recibos de departamentos
- A apresentação é em 2 semanas
- Audiência: 8 executivos não-técnicos
- Formato esperado: 15-20 slides com gráficos principaisExemplo editável
[DECOMPOSIÇÃO DE TAREFA]
Minha tarefa principal é: [DESCREVA A TAREFA GERAL]
Por favor, divida isso em subtarefas sequenciais, numeradas de 1 a N.
Para CADA subtarefa, forneça:
- Número e título da subtarefa
- Descrição do que fazer
- Critério de sucesso (como saber que foi bem feito)
- Qualquer dependência anterior
- Tempo estimado
Depois, apresente um cronograma recomendado para execução.Cadeia de Pensamento (Chain of Thought)
Exemplo editável:
[Chain of Thought - EDITÁVEL]
Você é um [ESPECIALISTA EM QUÊ?].
Analise: [DESCREVA O CASO/PROBLEMA]
Pense passo a passo:
1. [QUAL É O PRIMEIRO PASSO LÓGICO?]
2. [QUAL É O SEGUNDO PASSO?]
3. [QUAL É O TERCEIRO PASSO?]
Responda detalhando cada etapa do seu raciocínio.Exemplo completo:
[Chain of Thought - COMPLETO]
Você é um gerente de projetos. Analise: Um projeto de implementação de ERP estava planejado para 6 meses e orçado em R$ 500 mil. Estamos no 4º mês, consumimos R$ 450 mil, mas apenas 60% da funcionalidade foi entregue. O cliente está insatisfeito.
Pense passo a passo:
1. Diagnose: Qual foi a causa raiz do atraso (escopo, recursos, planejamento)?
2. Análise de impacto: Quanto tempo e custo adicionais serão necessários?
3. Estratégia: Que opções existem (extensão, redução de escopo, equipe maior)?
Responda detalhando cada etapa.Árvore de Pensamento (Tree of Thought)
Exemplo editável:
[Tree of Thought - EDITÁVEL]
Analise: [DESCREVA UM CENÁRIO COMPLEXO COM MÚLTIPLAS OPÇÕES]
Elabore uma árvore de pensamentos simulando múltiplos cenários:
Cenário 1: [PRIMEIRA OPÇÃO]
- Sub-consequência 1a: [...]
- Sub-consequência 1b: [...]
- Desfecho provável: [...]
Cenário 2: [SEGUNDA OPÇÃO]
- Sub-consequência 2a: [...]
- Sub-consequência 2b: [...]
- Desfecho provável: [...]
Cenário 3: [TERCEIRA OPÇÃO]
- Sub-consequência 3a: [...]
- Sub-consequência 3b: [...]
- Desfecho provável: [...]
Síntese: Qual cenário apresenta maior probabilidade de sucesso?Exemplo completo:
[Tree of Thought - COMPLETO]
Uma empresa precisa decidir sobre expansão internacional. Analise os três cenários principais:
Cenário 1: Mercado da Ásia (alto risco, alto retorno)
- Investimento inicial: $10M
- Barreiras regulatórias: altas
- Potencial de mercado: 500M pessoas
- Desfecho provável: Retorno em 4-5 anos se conseguir entrada
Cenário 2: Mercado da América Latina (risco médio, retorno médio)
- Investimento inicial: $5M
- Barreiras regulatórias: médias
- Potencial de mercado: 150M pessoas
- Desfecho provável: Retorno em 2-3 anos
Cenário 3: Mercado Europeu (baixo risco, baixo retorno)
- Investimento inicial: $3M
- Barreiras regulatórias: altas
- Potencial de mercado: 100M pessoas
- Desfecho provável: Retorno estável em 1-2 anos
Síntese: América Latina oferece melhor equilíbrio risco-retorno para expansão no curto prazo.Cadeia de Aprendizagem (Chain of Learning)
Exemplo editável:
[Chain of Learning - EDITÁVEL]
Atuará como simulador interativo para meu treinamento em [QUAL DOMÍNIO?].
[Seu Papel]
1. Crie um cenário/problema inicial sobre [TÓPICO ESPECÍFICO]
2. Não revele a solução imediatamente
3. Forneça informações neutras conforme eu progresso
4. Ajuste a dificuldade conforme meu desempenho
5. Revise meu raciocínio e aponte gaps
[Formato de Interação]
- Eu apresento minha análise/solução
- Você fornece feedback construtivo
- Iteramos até atingir domínio do tópico
Estou pronto para começar. Qual é o domínio e tópico?Exemplo completo:
[Chain of Learning - COMPLETO]
Atuará como simulador interativo para meu treinamento em Epidemiologia Clínica.
[Seu Papel como Professor-Simulador]
1. Crie um cenário de surto epidemiológico realista (ex: "Detectamos 15 casos de gastroenterite em uma creche em 3 dias")
2. Não revele a etiologia provável imediatamente
3. Forneça dados conforme eu os solicite (sintomas, incubação, exposições, lab)
4. Aumente a complexidade conforme eu demonstre compreensão (ex: fatores de confusão)
5. Revise meu raciocínio epidemiológico (foi adequada minha hipótese inicial?)
[Minha Abordagem]
- Formularei hipóteses sobre fonte, modo de transmissão
- Solicitarei dados específicos para testar hipóteses
- Você fornecerá feedback sobre adequação da investigação
Estou pronto. Apresente um cenário de surto.Chain of Verification
Técnica que reduz alucinações ao pedir que a IA gere perguntas de verificação para checar suas próprias premissas antes de dar a resposta final.
[Chain of Verification]
Responda: Quais são as principais interações medicamentosas da Varfarina com alimentos e antibióticos comuns? Após responder, siga este protocolo de verificação: 1. Crie 3 perguntas para checar se as interações citadas são verdadeiras (ex: 'A vitamina K realmente interfere?'). 2. Responda a essas perguntas de forma independente. 3. Forneça uma resposta final revisada e corrigida com base nessas verificações.[Chain of Verification]
Liste 3 decisões recentes do STJ sobre responsabilidade civil hospitalar. Siga o protocolo CoVe: 1. Gere perguntas para confirmar número de processo e ano. 2. Responda se os processos existem e tratam do tema. 3. Entregue apenas os casos confirmados.Chain of Debate
Simula um debate entre múltiplas perspectivas (personas) para explorar um tema complexo e chegar a uma síntese mais equilibrada.
[Chain of Debate]
Você atuará como dois médicos especialistas debatendo internamente. Contexto: Paciente idoso, frágil, com múltiplas comorbidades, diagnóstico recente de câncer avançado. Tarefa: Simule um debate interno estruturado: Especialista A defende tratamento agressivo e Especialista B defende cuidados paliativos precoces. Cada um deve apresentar seus argumentos, refutar os do outro e reconhecer limitações. Finalize com uma síntese equilibrada.[Chain of Debate]
Simule uma discussão entre um Advogado de Defesa, um Promotor e um Juiz sobre a admissibilidade de prova obtida via WhatsApp sem autorização em caso de corrupção. Debatam 'Frutos da Árvore Envenenada' vs 'Interesse Público'.Self-Consistency
Gera múltiplos raciocínios independentes para o mesmo problema e verifica a coerência entre eles para formular uma conclusão mais robusta (a "maioria vence").
[Self-Consistency]
Gere três análises independentes sobre o mesmo caso clínico de suspeita de tromboembolismo pulmonar (TEP). Produza três raciocínios diagnósticos separados. Depois, compare as três análises, identifique os pontos de convergência mais consistentes e formule a conclusão final.[Self-Consistency]
Gere três análises jurídicas independentes sobre o mesmo caso contratual. Identifique os pontos comuns entre elas e use-os para formular a conclusão mais robusta.Reflexion
Obrigatório para tarefas críticas: pede para a IA criticar sua própria resposta inicial e refiná-la com base nessa autocrítica.
[Reflexion]
Escreva um guia de orientações pós-operatórias para cirurgia de catarata. Após gerar o texto, execute: 'Reflita criticamente sobre sua resposta: Onde posso ter simplificado demais? Que premissas podem estar erradas? Que informação adicional mudaria minha conclusão?'. Após essa reflexão, refine sua resposta original.[Reflexion]
Reflita criticamente sobre o parecer jurídico que você acabou de produzir. Identifique fragilidades, pressupostos questionáveis e pontos que poderiam ser melhor fundamentados. Revise o parecer após a análise.Prompt Chaining
Quebra uma tarefa complexa em uma sequência de prompts onde a saída de um serve como entrada para o próximo.
[Prompt Chaining]
Prompt 1: Analise este caso clínico e gere um diagnóstico diferencial estruturado. Prompt 2: Com base no diagnóstico diferencial acima, proponha uma conduta inicial baseada em evidências.[Prompt Chaining]
Prompt 1: Resuma os principais riscos jurídicos do caso apresentado. Prompt 2: Com base nos riscos identificados, elabore uma estratégia jurídica defensiva.Generated Knowledge
Solicita que a IA primeiro gere um conhecimento base (resumo técnico/teórico) sobre o tema antes de tentar resolver o problema específico.
[Generated Knowledge]
Antes de analisar o caso clínico abaixo, gere um resumo técnico sobre: Fisiopatologia do choque séptico, Critérios diagnósticos atuais e Princípios gerais de tratamento. Somente depois aplique esse conhecimento ao caso clínico apresentado.[Generated Knowledge]
Antes de analisar o caso, gere um resumo técnico sobre: Princípios da boa-fé contratual e Hipóteses legais de rescisão. Depois, aplique esse conhecimento ao caso concreto.Least-to-Most
Estratégia educacional e de resolução de problemas que pede para explicar o conceito do "básico para o avançado" ou resolver subproblemas simples antes do complexo.
[Least-to-Most]
Explique inicialmente, em linguagem simples, o que é insuficiência cardíaca. Depois: 1. Explique os mecanismos fisiopatológicos. 2. Diferencie IC com fração preservada e reduzida. 3. Relacione isso à escolha terapêutica.[Least-to-Most]
Para realizar uma due diligence em uma startup, identifique primeiro as 4 áreas críticas de risco. Resolvido isso, para a primeira área, liste os documentos indispensáveis e crie um checklist de verificação.Directional Stimulus
Fornece "dicas" ou diretrizes específicas (estímulos) para guiar o raciocínio da IA em uma direção desejada (ex: priorizar segurança).
[Directional Stimulus]
Ao responder sobre este caso clínico, priorize rigorosamente: Segurança do paciente, Medicina baseada em evidências e a prevenção de overdiagnosis/overtreatment. [Descreva o caso clínico aqui].
[Directional Stimulus]
Ao responder sobre este litígio, priorize: Minimização de riscos legais, Interpretação conservadora da lei e Proteção patrimonial do cliente. [Descreva o caso].Program-Aided Language
Solicita que a IA use lógica de programação ou pseudo-código para estruturar raciocínios lógicos ou matemáticos, aumentando a precisão.
[Program-Aided Language]
Represente o raciocínio diagnóstico de um caso suspeito de sepse em formato de pseudo-código lógico (if/then) antes de explicar em linguagem natural, para garantir precisão algorítmica.[Program-Aided Language]
Calcule o valor de uma dívida de R$ 50.000, vencida em 10/01/2023, com juros de 1% e IPCA de 4,5%. Escreva um script Python que realize os cálculos e execute-o para me dar o valor exato.ReAct (Reasoning + Acting)
Intercala pensamento (raciocínio) e ação (busca de informação/ferramenta) em um ciclo contínuo para resolver problemas dinâmicos.
[ReAct]
Você atuará no formato ReAct para gerenciar um caso de intoxicação exógena: Pensamento 1: Preciso saber qual substância foi ingerida. Ação 1: Pergunte ao usuário. Pensamento 2: Com base na resposta, devo consultar o antídoto. Ação 2: Forneça a dose. Prossiga no ciclo até a estabilização.[ReAct]
Alterne entre raciocínio jurídico e ação: Pensamento: O que esta notificação significa? Ação: Que documento analisar? Pensamento: Implicações? Ação: Resposta recomendada. Continue até a estratégia final.Contatos


IA e Medicina