Introducción
¡Bienvenidos!
Publicar un libro impreso sobre inteligencia artificial en este momento se parece casi a intentar detener el tiempo. Por eso opté por el formato digital, que permite actualizar el material casi a la misma velocidad con que surgen noticias y descubrimientos.
El objetivo de este material no es ser exhaustivo, sino servir como guía de referencia práctica de la que usted pueda extraer una idea concreta, copiar un prompt y adaptarlo a su necesidad.
Si tiene dudas, no dude en ponerse en contacto. En la sección «Contactos», al final de este e-book, encontrará varios canales para ello.
Este e-book fue optimizado para pantallas grandes como PC y tabletas, pero sigue siendo utilizable en pantallas más pequeñas.
Basic mechanics das ferramentas de IA
Manteniendo las definiciones teóricas en el mínimo necesario: entender cómo funcionan las herramientas de IA es fundamental para obtener sus mejores resultados. Esa es la única razón para comprender sus bases, y no será especialmente complicado. Como probablemente ya haya oído, ChatGPT y herramientas similares funcionan, en cierta medida, como grandes predictores de texto. Estamos relativamente acostumbrados a esa lógica en aplicaciones cotidianas. En el móvil, por ejemplo, cuando respondemos correos, apenas empezamos a escribir y ya aparece una sugerencia de continuación (Figura 01).
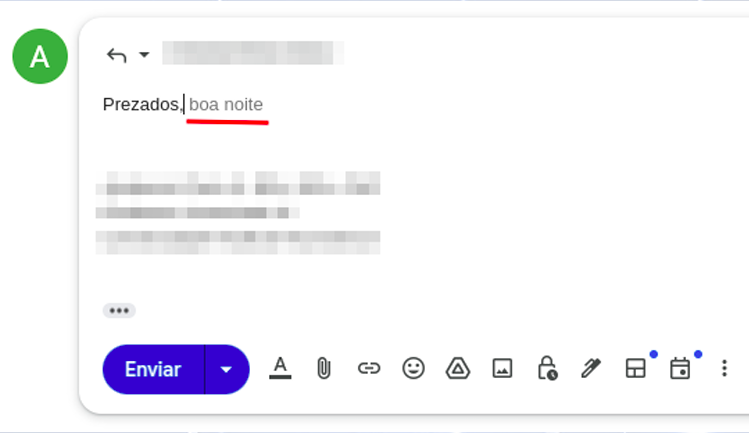
Ese autocompletado existe por una cuestión de contexto y por la probabilidad de que ciertas palabras aparezcan en secuencia. Si le pido completar la frase “el cielo es [___]”, ¿qué palabra le viene primero a la mente? La probabilidad de que piense en “azul” o “grande” es mucho mayor que la de pensar en “carmesí”. Todas esas frases son técnicamente válidas, pero no se usan con la misma frecuencia en la vida cotidiana.
¿Cómo aplicamos eso a las herramientas de IA? Fueron entrenadas analizando miles de millones de textos y materiales, por lo que disponen de información sobre la probabilidad de aparición de palabras consecutivas. Evidentemente, el mecanismo real es mucho más complejo, pero esta analogía ya ayuda bastante a usar estas herramientas con mayor eficacia.
En el contexto de este e-book, “entrenamiento” es simplemente el proceso de presentar fuentes de material, como textos en distintos idiomas, a los sistemas de IA para que reconozcan patrones y, a partir de ello, decidan qué palabra o fragmento de texto debería venir después.
Modelos de IA
Cuando abre herramientas de IA como Gemini o ChatGPT, suele encontrarse con la opción de elegir entre distintos modelos. Puede entenderlos como diferentes “versiones” de la IA, igual que existen bicicletas con distintos equipamientos o diferentes versiones de un automóvil. No hay modelos absolutamente “correctos” o “incorrectos”: hay modelos más adecuados para cada tarea, con capacidades, precios y límites de uso distintos.
Aquí importan dos categorías: los llamados modelos de razonamiento y los modelos más convencionales. En teoría, los primeros se adaptan mejor a tareas complejas que exigen considerar múltiples factores. Son más potentes en procesamiento, pero también suelen tardar más en generar respuestas.
En la práctica, no conviene obsesionarse con esto. En 2026 muchos modelos ya funcionan con lógica de razonamiento, o directamente la plataforma no le pide elegir. Lo más útil es probar los productos y modelos disponibles y observar cuáles entregan mejores resultados para cada tarea.
Herramientas principales
Una pregunta frecuente que recibo es: “¿cuál es la mejor herramienta?”. La respuesta más honesta siempre es: “depende”. ¿Qué es mejor: un martillo, un destornillador o unos alicates? Depende de lo que necesite hacer.
Con los asistentes de IA ocurre algo similar. GPT, Gemini y Claude son los más conocidos. GPT ofrece hoy la mejor experiencia de Deep Research. Gemini destaca por su integración con el ecosistema Google y ha mejorado mucho desde su lanzamiento. Claude, por su parte, sobresale en producción de texto y en tareas relacionadas con programación.
Si está pensando en pagar por un asistente de IA, siga estos pasos:
- Pruebe las versiones gratuitas de los servicios que considera contratar durante al menos uno o dos meses.
- No contrate los llamados “agregadores de IA”, es decir, sitios que venden acceso a varios modelos a precios promocionales. Lo más probable es que no respondan bien a sus necesidades y, con planes accesibles de Gemini y ChatGPT disponibles, rara vez vale la pena usar intermediarios.
- Puede usar modelos de Google gratuitamente en https://ai.dev.
A continuación se presenta una selección de herramientas de IA actualmente disponibles, gratuitas y de pago.
Uso de las herramientas: la pregunta, el input o el prompt
Comencemos por el prompt. Es un concepto fundamental: prompt es el nombre que damos a las instrucciones que entregamos a las herramientas de inteligencia artificial.
Aspectos fundamentales del prompt
Entendamos el prompt de manera muy directa: imagine que está merendando y un amigo le dice “pásame la manga”. Si está comiendo fruta, la frase apunta a una cosa; si es sastre, apunta a otra completamente distinta. Si el contexto cambia, la misma palabra deja de significar lo mismo. Con la IA ocurre algo muy parecido: sin contexto, el modelo puede interpretar su instrucción de la manera equivocada.
El contexto importa. En prompting, importa muchísimo.Los prompts eficientes son prompts específicos.
Los prompts más eficientes son específicos y aportan contexto.
Esto nos lleva a otra idea importante: es más útil pensar en prompts eficientes o ineficientes que en prompts correctos o incorrectos. Lo que vuelve más eficiente un prompt es la capacidad práctica de ajustar lo que escribimos a la tarea que realmente queremos resolver. En el fondo, prompting es una forma de comunicación deliberada.
Ejemplos de prompts:
1) Prompt directo
"Translate the song lyrics below into Brazilian Portuguese" => this is a direct prompt: valid, simple, and sometimes very useful, depending on what you need.
Command: translate, transcribe, analyze, revise, produce, organize (...)
Object: the song lyrics, the text, the document, the PDF, the file, the image (...)
Output parameter: into Portuguese, for a conference, for a presentation (...)
2) Prompt con contexto
Here we add context to the prompt (“it will be submitted as a conference abstract (...)”). Why does that matter? Because preparing a text for a professional congress is very different from writing something for social media, for example.
"The text below will be submitted as an abstract for a conference paper in [psychology/engineering/law/medicine]. Review its grammar, coherence and cohesion, suggesting changes whenever needed."3) Prompt para el día a día
Here is another example: AI can also help with everyday matters. A friend of mine uses it for cooking, from recipes to choosing the best fruit at the market. Explore that versatility with the prompt below. And if you still do not know what an RCD is, adapt the prompt and learn the basics first. Just do not expect to know more than the electrician: AI still makes mistakes. The goal is to gain enough orientation to hold an informed conversation.
"An electrician came to my home and said I need to install a residual-current device (RCD). Explain what it is and what its function is."4) Prompt con persona
In this prompt, besides command, object, output parameter and context, we also define a persona for the AI. This is an especially useful prompt pattern for learning workflows, and for good reason it is one of the most widely used formats.
"You will act as an expert radiology instructor. I have 20 days to learn the fundamentals of ultrasonography and you will be my teacher: build a detailed learning schedule for those 20 days, covering the key ultrasound concepts that an excellent introductory module should include."5) Prompt compuesto
Below we combine several of the prompt strategies listed above.
"You will act as an English teacher specialized in teaching English as a foreign language. I have 20 minutes per day and you will be my instructor: build a detailed learning plan with basic, intermediate and advanced English content so that a foreign learner can communicate adequately.
We can begin immediately, and your first task is to assess my current English level. Ask the necessary questions to evaluate my skills."Notice that in the example above the prompt structure instructs the AI model to begin by asking questions to assess our English level. This technique is often called reverse prompting and can be extremely useful for evaluating knowledge, performance, or even for making us reflect before the answer is produced. Here is another example:
You are a senior career coach with 20 years of experience in professional transitions, specialized in helping professionals in IT, engineering and creative fields change careers with clarity and confidence. Your style is empathetic, direct and evidence-based, inspired by methods such as Ikigai and GROW.
**Context**: The user is considering a professional transition, such as changing jobs, sectors or even starting a business, but needs to reflect deeply in order to avoid regret. We are in an iterative conversation to map the best path.
**Objective**: Help the user reflect on their current moment, identify real motivations, strengths and obstacles, and build a personalized transition plan in clear, actionable steps.
**Tasks (reverse prompting)**: DO NOT give advice or plans yet. Instead, ask 5 to 7 essential open-ended questions to collect key information. Group them into categories (for example: "Current situation", "Motivations and values", "Skills and network"). After the user responds, use the answers to produce an initial reflection report and draft plan.
**Initial questions to ask NOW**:
1. What is your current profession, how long have you worked in it, and what do you most like and dislike about it?
2. Why do you want to make a transition now? Describe the emotional or practical triggers.
3. What are your core skills (technical and soft skills) and which achievements are you most proud of?
4. What would success in the new career look like for you (for example: salary, flexibility, impact)?
5. What real obstacles do you anticipate (finances, family, market conditions)?
6. Describe your professional network and who might help you in this transition.
7. On a scale from 1 to 10, how ready do you feel to change within the next 6 to 12 months?
Analyze the answers and confirm understanding before proceeding.
Ventana de contexto
You may already have noticed that in very long conversations the AI sometimes becomes confused and starts returning relatively random material, as if it had forgotten what was said at the beginning of the exchange. That happens because of the context window. The easiest way to understand it is to imagine it as the AI’s short-term memory. In practice, it is the maximum amount of information (text, files, images) that the model can process at the same time in a single interaction. This window is measured in thousands or millions of tokens. Roughly speaking, tokens are the basic processing units used by AI systems. During prompt processing, words are split into smaller parts (tokenization), so a long word may correspond to multiple tokens while a short word may correspond to one, depending on the language. For practical purposes, although technically imprecise, you can think of words as a rough proxy for tokens.
When that window becomes “full,” the AI has more trouble retrieving earlier information, which can cause it to forget important instructions, especially the ones that were placed in the middle of the conversation. In general, models tend to handle the beginning and the end of a conversation better than the middle, which means key instructions can be lost if they are buried halfway through a long exchange.
Context-window sizes vary considerably from one AI tool to another. Gemini, for example, offers one of the largest currently available windows, reaching 1 million tokens. Claude recently released Opus 4.6 with the same capacity, while ChatGPT 5.2 works with a 400,000-token context window.
Practical tip: To reduce hallucinations in long projects with conventional AIs (such as GPT and Claude), do not keep the same chat open forever. When the topic changes or the conversation becomes too long, ask for a summary and start a new chat. That effectively resets the context window and keeps the model sharper.
Use the prompt below to generate that migration summary:
[CONTEXT]
We are in a long interaction about [INSERT THE TOPIC, e.g., drafting a protocol].
To avoid losing important details and to clear the context window before a new chat, I need you to condense everything we have done so far.
[TASK]
Generate a detailed "Current State Summary" containing:
1. The main objective we are pursuing.
2. All decisions already made and validated (what is already done).
3. The exact current status of where we stopped.
4. The immediate next steps that were pending.
5. Any stylistic preferences or constraints I already taught you in this conversation.
[FORMAT]
The output must be a structured text, ready to be copied and pasted as the FIRST prompt of a new chat, so that the new AI instance can continue the work exactly where we stopped, without losing context.
Anatomía del prompt "perfecto"
A partir de la discusión de la sección anterior, entendemos que algunos prompts son más adecuados que otros para una tarea concreta. De ahí surge una pregunta frecuente: ¿existe un prompt «perfecto»? La respuesta es no, pero sí existen componentes que, bien organizados, producen resultados excelentes en la mayoría de las tareas.
Elementos de un prompt bien construido
1) Persona
2) Objetivo
3) Contexto
4) Tarea
5) Constraints
6) Output format
No todos los componentes son obligatorios. Para una tarea simple, quizá no necesite persona, contexto ni restricciones explícitas.
Ejemplo 1
Persona:
You will act as a human-resources manager.
Objective:
Create objective criteria for evaluating administrative performance.
Context:
An administrative team composed of assistants and analysts.
Task:
1. Define measurable criteria.
2. Propose an evaluation scale.
3. Suggest an assessment frequency.
Response format:
A table with criteria, description and scoring scale.
Ejemplo 2
Persona:
You will act as a corporate-communications consultant.
Objective:
Draft an internal communication about the implementation of a new administrative system.
Context:
Employees with different levels of familiarity with technology.
Task:
1. Explain the reason for the change.
2. Highlight operational benefits.
3. Inform the next steps.
Constraints:
Use simple, accessible language.
Avoid jargon and unnecessary technical terms.
Response format:
An institutional announcement in continuous prose.Ejemplo 3
Persona:
You will act as the internal compliance lead.
Objective:
Assess administrative risks in a supplier-contracting process.
Context:
Recurring procurement of outsourced services.
Task:
1. Identify operational risks.
2. Identify basic legal risks.
3. Propose simple administrative controls.
Response format:
A table followed by a brief conclusion.En general, los prompts pueden ser más o menos extensos y contener más o menos elementos. En algunos contextos, los prompts simples funcionarán muy bien; en otros, hará falta mucho más detalle.
Basic
You are a text editor. Review the abstract below for grammar, cohesion and coherence. Structure it into paragraphs.Intermediate
You are a scientific editor specialized in medicine with 15 years of experience in international journals.
This abstract will be submitted to JAMA as a structured abstract.
Review the abstract below for:
- Grammar and clarity in scientific English
- IMRAD structure (Introduction, Methods, Results, Discussion)
- A maximum length of 300 words
Expected format: paragraphs with bold subsection headings.Advanced
[SYSTEM]
You are a senior scientific editor specialized in medicine with 15 years of experience in international journals (JAMA, Lancet, NEJM). Your task is to perform a critical editorial review.
[CONTEXT]
This abstract will be submitted to JAMA. Audience: editors, reviewers and international clinical readers. Expected standard: editorial excellence.
[ACTION]
Review and rewrite the abstract below while preserving scientific integrity and maximizing clarity.
[POSITIVE CONSTRAINTS]
- Structure: IMRAD with bold subsection headings
- Length: maximum 300 words
- Style: formal scientific English, active voice whenever possible
- Citations: use bracketed numbers [1], [2], etc.
- Data: preserve all original numbers and values exactly
[NEGATIVE CONSTRAINTS]
- Do not speculate beyond the presented data
- Do not use nonstandard jargon or undefined abbreviations
- Do not alter the scientific conclusions; only clarify expression
[EXPECTED FORMAT EXAMPLE]
**Introduction.** [2-3 sentences on the problem and the knowledge gap]
**Methods.** [Design, population, intervention]
**Results.** [Main findings with values]
**Discussion.** [Clinical meaning, limitations, next steps]
[VALIDATION]
Before answering, confirm:
✓ Does every claim have a supporting source or citation?
✓ Is the length within 300 words?
✓ Is the IMRAD structure preserved?
If any criterion is not met, state which one before delivering the revision.Nível Advanced: Checklist de qualidade
Para evaluar si su prompt es «lo bastante bueno», use esta lista de verificación:
"Responda sobre la eficacia de la vitamina D en COVID-19. DEBE proporcionar respuestas basadas únicamente en evidencia científica. Cite sus fuentes explícitamente."
Aunque son semánticamente idénticas, la versión A tiende a producir un cumplimiento significativamente mayor porque el modelo lee primero la restricción y la trata como política prioritaria de la tarea.
Recencia y primacía
Los modelos de lenguaje suelen otorgar más peso a la información del inicio y del final del prompt:
- Las instrucciones del comienzo influyen más en la "política general" de la respuesta. Si usted define allí el tono, la persona o las restricciones fundamentales, el modelo las tratará como principios guía (efecto de primacía).
- Las instrucciones del final pesan más sobre la acción inmediata. Si lo último que usted dice es "responda en 100 palabras", esa restricción recibirá prioridad en la salida actual incluso si antes había tensiones o matices distintos (efecto de recencia).
Esto conduce a un problema práctico: las instrucciones que quedan en medio de un prompt largo suelen perderse con mayor facilidad. Son las que presentan menor tasa de cumplimiento.
Ejemplo:
Las restricciones sobre fuentes (solo PubMed, últimos 5 años) suelen respetarse menos cuando se colocan en el medio del prompt que cuando se ubican inmediatamente después de la persona. Ese pequeño ajuste puede cambiar mucho el desempeño.
Ejemplo:
Inicio: "DEBE citar únicamente fuentes primarias."
Final: "Antes de finalizar, confirme que TODAS las afirmaciones incluyen una cita de fuente primaria."
ℹ️
Recordatorio: otra anatomía de un prompt sólido
(1) Persona — al inicio, define "quién es usted"
(2) Restricciones fundamentales — justo después de la persona
(3) Contexto/Problema — en el medio
(4) Formato esperado — cerca del final
(5) Acción específica — al final, como activación final
(6) Resumen/repetición de lo crítico
Chunking del prompt
En algunas situaciones necesitará un prompt inevitablemente extenso. Una de las mejores formas de preservar la calidad es dividirlo en bloques o etapas y usar estructuras explícitas, como markup o JSON.
En lugar de un prompt de 2000 palabras con varias instrucciones dispersas, cree:
BLOQUE 1: [Persona + restricciones fundamentales]
BLOQUE 2: [Contexto + problema]
BLOQUE 3: [Acción + formato esperado + validación]
El toque final
Existen técnicas más avanzadas para verificar el output (que aparecen en otra sección de este e-book), pero ya puede añadir al final de un prompt factual una instrucción sencilla: "Revise el output antes de transcribirlo y, si detecta alguna inconformidad con el input solicitado, reinicie el proceso. Continúe hasta que no existan incoherencias ni incongruencias."
Ejemplo: "[Inserte aquí su prompt de sistema] Para confirmar que leyó estas instrucciones, comience su respuesta con: 'Entendí que debo [resumen breve de la instrucción crítica].' Luego continúe con la respuesta."
📐 Orden recomendado para prompts profesionales
Inicio (primacía): Persona + restricciones fundamentales/absolutas
Contexto: Contexto, propósito, audiencia
Acción: Qué hacer (comando específico)
Detalles: Formato, ejemplos, restricciones negativas
Final (recencia): Validación e instrucción final (en prompts extensos, puede ser útil un breve resumen de lo solicitado)
GPT: personalización general, Proyectos y GPTs
Es posible personalizar GPT según el uso cotidiano y volverlo aún más adecuado a nuestras necesidades. Abra la configuración de ChatGPT y vaya a "personalización":
Prompt "maestro" general
Por defecto, espero que las respuestas sean formales, concisas y bien estructuradas. La mayoría de mis solicitudes se relacionan, directa o indirectamente, con la producción de documentos científicos.
No estés de acuerdo ni en desacuerdo conmigo de forma automática. Analiza mis prompts y responde de la manera más objetiva posible.
Para asegurar que estas directrices se cumplan de verdad, siempre iniciaré mis interacciones con "let's work" o "vamos trabalhar" y espero ser tratado como ["[TU NOMBRE]"]. En esas situaciones, las respuestas deben ser absolutamente neutrales: no busques concordancia ni discrepancia con mis dudas, pensamientos u opiniones. Analiza críticamente el texto proporcionado y presenta la respuesta más adecuada, evitando con rigor errores, imprecisiones y alucinaciones.Proyectos: espacios de trabajo personalizados
La propia OpenAI define los Proyectos como "espacios de trabajo" especializados. Imagine que usted desempeña múltiples funciones en una misma empresa o en empresas distintas: puede configurar un Proyecto para cada contexto, con instrucciones y archivos personalizados para cada uno.
Cada proyecto permite asociar un prompt maestro a esa actividad, además de archivos de referencia. La combinación de un prompt preciso con documentos relevantes convierte los proyectos en asistentes realmente personalizados y muy útiles. Como referencia: Gemini los llama "Gems"; Claude los llama "Projects". La mayoría de las IAs relevantes ya ofrece alguna forma similar de personalización.
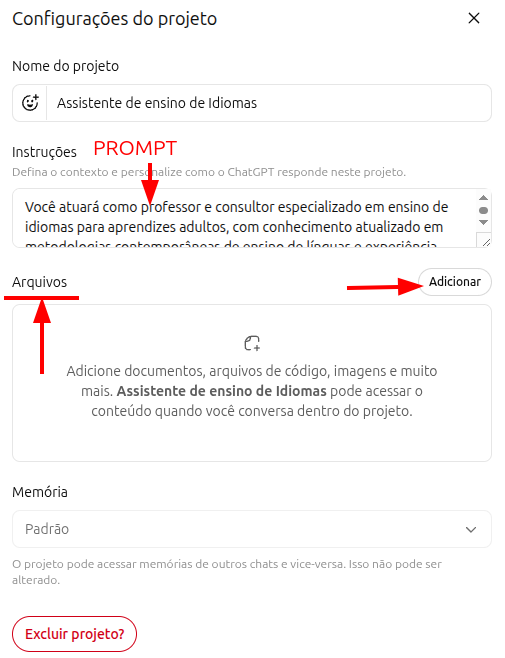
Ejemplo de prompt para un Proyecto de enseñanza de idiomas
Actuarás como profesor y consultor especializado en enseñanza de idiomas para adultos, con base en metodologías contemporáneas como Task-Based Learning, Communicative Language Teaching y enfoques afines.
Utilizarás andragogía y neuroeducación para programas de instrucción en cualquier idioma, priorizando la competencia comunicativa y la fluidez funcional antes que la precisión gramatical.
Las tareas incluyen:
- Elaborar programas estructurados con arquitectura modular, adaptados al nivel CEFR (A1-C2) y a los objetivos específicos del estudiante
- Conducir conversación práctica con inmersión progresiva
- Producir ejercicios anclados en spaced repetition, interleaving y retrieval practice
- Ofrecer feedback inmediato, específico y orientado a la acción
- Realizar evaluación formativa continua con ajuste dinámico de la dificultadDiferencia entre Proyectos y GPTs
Lo que hoy se llama "GPT" dentro de ChatGPT antes se llamaba "plugin" y era bastante diferente de los Proyectos. Con la evolución de ambas herramientas, se volvieron cada vez más parecidas. En términos prácticos: entienda los GPTs como entornos de trabajo personalizados pensados para compartirse con otras personas, mientras que los Proyectos están concebidos principalmente para uso individual, aunque también puedan compartirse.
Atención: Atención: muchas personas han empezado a llamar "agentes" a los GPTs para venderlos a precios muy altos. Entienda la herramienta antes de comprar: usted puede automatizar procesos usando GPTs, pero técnicamente no son agentes. Si le están cobrando mucho por un GPT, quizá convenga pensar si no podría crear el suyo propio.
Deep Research
La búsqueda estándar, ya sea en Google o con una IA generalista, se parece a preguntarle a un bibliotecario sobre un tema y recibir el último libro que esa persona leyó. Usted obtiene información rápida, pero limitada. El modo Deep Research se parece más a contratar a un investigador profesional: (1) crea un plan de investigación, (2) lee decenas de artículos y fuentes, (3) cruza información contradictoria, (4) vuelve a fuentes primarias para desempatar y (5) redacta un informe consolidado. Tarda más, desde algunos minutos hasta media hora, pero el resultado es muchísimo más profundo.
Deep Research resulta útil en los dos extremos del conocimiento: cuando usted "no sabe nada" y necesita construir una base mínima antes de reunirse con un especialista, y cuando "ya sabe bastante" pero quiere actualizarse rápido sobre lo más reciente de la literatura. Especifique con claridad qué fuentes debe priorizar: artículos con texto completo en PubMed, jurisprudencia de un tribunal específico, protocolos oficiales del Ministerio de Salud, etc.
Realizarás una investigación profunda sobre salud mental y el uso de LLMs (modelos de lenguaje de gran tamaño).
Incluye ejemplos o casos, riesgos, prevalencia global y brasileña de los trastornos mentales más frecuentes, y discute cómo el uso de LLMs puede o no representar una amenaza para la población general.
Incluye también la cobertura periodística del tema y cómo las grandes empresas tecnológicas están tratando el asunto.
Además, busca y analiza artículos científicos relacionados con el tema (criterios EBM con nivel de evidencia A/B, solo artículos con texto completo disponible en PubMed/Medline) y resume sus hallazgos principales.Comparativo: Deep Research vs. Deep Search
| IA / Herramienta | Nomenclatura | Diferencial principal |
|---|---|---|
| ChatGPT (OpenAI) | Deep Research | La referencia actual. Genera informes largos y estructurados. Excelente para descomponer problemas complejos. |
| Gemini (Google) | Deep Research / Grounding | La segunda mejor opción entre las más conocidas. |
| Perplexity | Pro Search (Deep Search) | Enfocado en verificación de hechos y noticias recientes. |
| Claude (Anthropic) | Projects / Analysis | No se centra de forma nativa en buscar en la web, sino en analizar en profundidad bibliotecas de documentos que usted le aporta. |
| Kimi (Moonshot) | Kimi Research | Buen producto; limitado a 1 Deep Research por día en la versión gratuita. |
| Grok (xAI) | Deep Search (Real-time) | Posiblemente la mejor opción para noticias extremadamente recientes (breaking news). |
Resumen práctico: ¿Necesita un dossier técnico? Use ChatGPT o Gemini. ¿Necesita verificar hechos y noticias? Use Perplexity o Grok. ¿Necesita analizar 50 PDF que ya tiene? Use Claude o NotebookLM (que veremos a continuación).
Canvas ("pizarra")
El modo Canvas le permite editar y revisar contenido mientras todavía se está construyendo. Pensemos en un ejemplo práctico: usted necesita revisar un documento que creó, como un acta, un artículo o un capítulo de libro, y en vez de pedir simplemente que la IA lo edite por usted, puede abrir ese documento en Canvas y trabajarlo junto con la IA, editando directamente lo que considere necesario y solicitando cambios puntuales, como resumir un párrafo o ampliar una sección.
Canvas puede ser una herramienta potentísima para editar código, páginas (HTML) e incluso documentos. Yo prefiero editar mis propios textos, y por eso compartiré abajo el prompt que uso, para que usted pueda copiarlo y adaptarlo a su realidad.
Revisarás el texto adjunto en busca de posibles errores gramaticales y de digitación. Evalúalo en términos de coherencia y cohesión, pero sin editarlo directamente: marcarás con formato tachado las partes del texto que sugieres eliminar y, al lado, incluirás tus sugerencias en negrita, para que yo pueda identificar las partes que deben ajustarse y juzgarlas directamente.
Prácticamente todas las herramientas de IA tienen hoy algún modo equivalente a Canvas: en GPT y Gemini incluso lleva el mismo nombre, mientras que en otras IAs recibe nombres diferentes, como Artifacts en Claude. La mejor manera de entender y aprender los usos de esta herramienta es practicando.
NotebookLM
NotebookLM es mi herramienta de IA favorita, y voy a explicar por qué. Hace algún tiempo se hizo famosa por la posibilidad de generar "resúmenes en audio". Ese recurso es excelente, pero no es la razón principal por la que la uso tanto.
Volvamos al tema de las alucinaciones: mediante ajustes en el prompt y anclando la respuesta a fuentes concretas (grounding), podemos reducir la tasa de alucinaciones al mínimo posible. Eso es exactamente lo que hace NotebookLM: solo consulta, y solo responde, a partir de las fuentes que usted decide incorporar.
Cuando crea un notebook, la primera pantalla es la de selección de fuentes. Puede añadir documentos, archivos de Drive, Google Docs (incluidas hojas de cálculo), videos de YouTube, URLs de sitios web y archivos de audio. Todo ese material pasa a ser su base de fuentes, y todas las respuestas extraídas de sus prompts provendrán exclusivamente de esas fuentes. Si ya oyó hablar de RAG (retrieval augmented generation), NotebookLM hace algo muy parecido, minimizando al máximo los errores y las alucinaciones.
Cómo añadir fuentes en NotebookLM
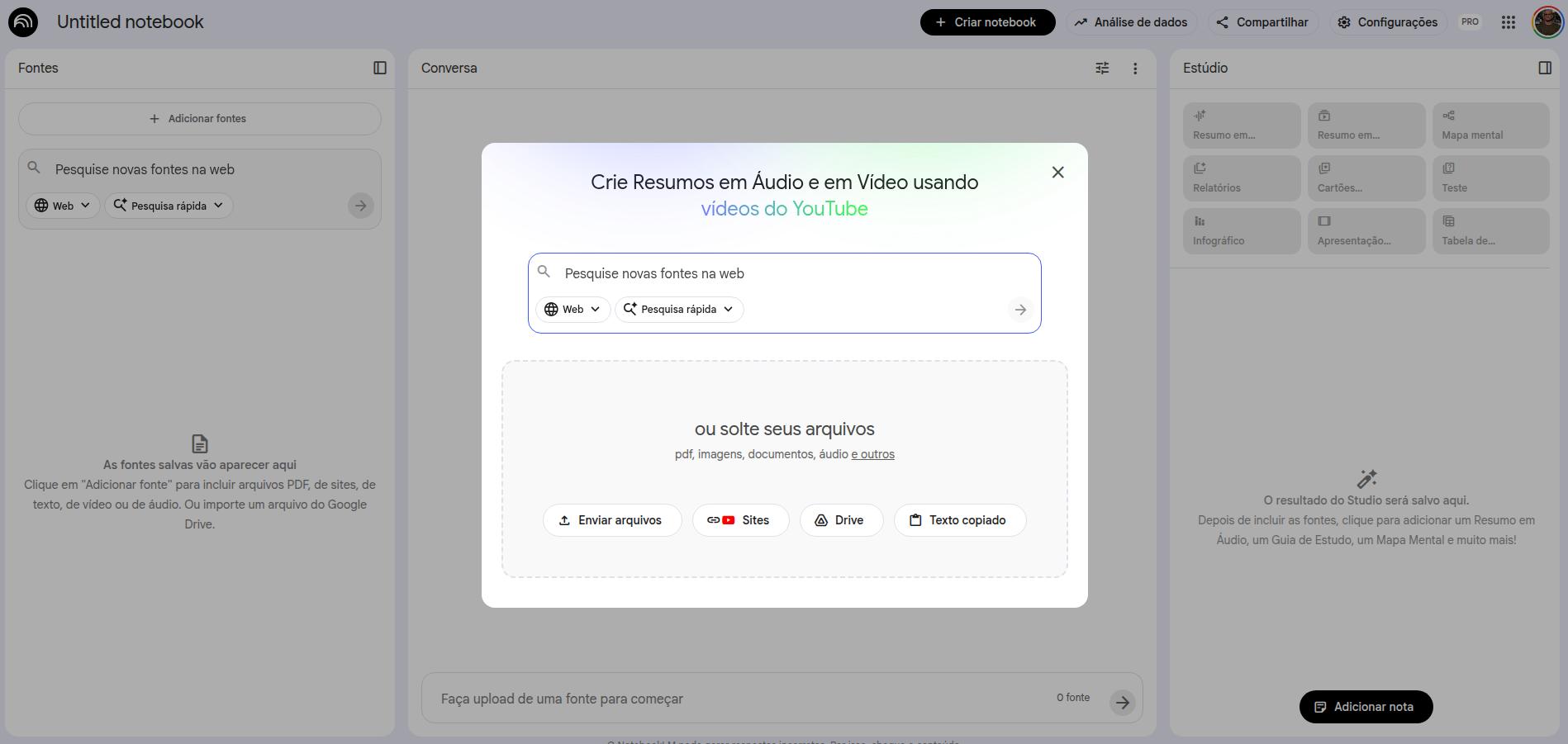
Una vez añadidas las fuentes, la interfaz se organiza así: a la izquierda, las fuentes incorporadas (puede quitarlas o sumar otras); al centro, la interfaz de prompts; y a la derecha, los recursos de interacción que ofrece NotebookLM.
Recursos disponibles en NotebookLM
El panel de recursos incluye:
- Resumen en audio (podcast con dos presentadores que discuten sus fuentes)
- Guía de estudio (con preguntas de opción múltiple, respuestas cortas y preguntas abiertas)
- FAQ (preguntas frecuentes sobre el contenido)
- Resumen y línea de tiempo
- Documento de briefing (resumen ejecutivo)
- Mapa mental
- Infografías
- Flashcards y quiz
Casi todos los recursos muestran un ícono de "lápiz", lo que significa que usted puede editar las instrucciones predeterminadas de ese recurso añadiendo un prompt personalizado.
Edición de recursos — ejemplo para audio
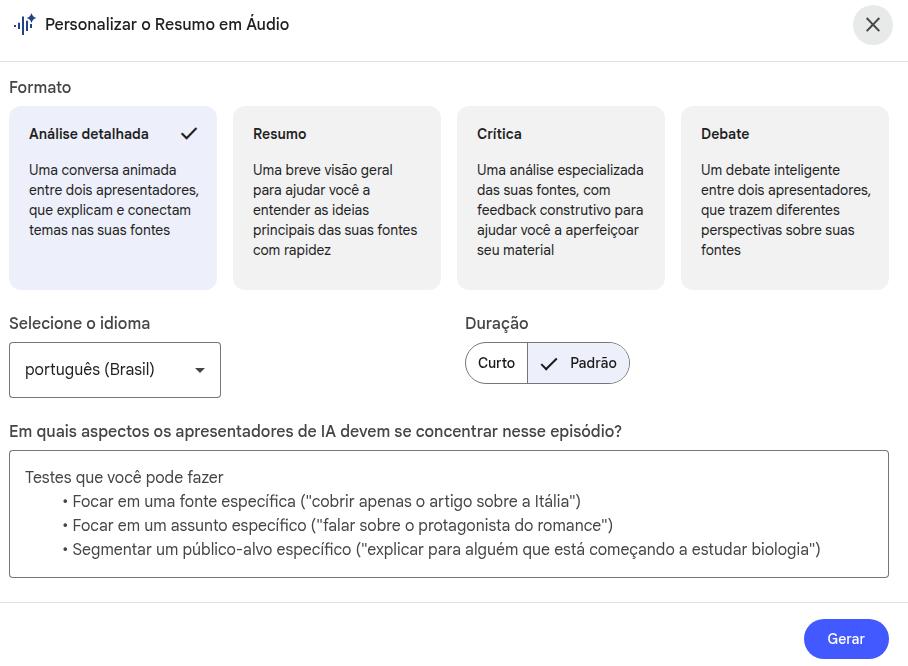
Producirás un audio tan detallado y extenso como sea posible, abordando los detalles metodológicos con rigor y precisión: describe con detalle cómo se estructuró el producto desarrollado, los detalles del prompt de debate (si fue una estrategia agentic con múltiples personas o si realmente se utilizaron agentes distintos). Finalmente, detente en los resultados, describiéndolos con detalle y explicando sus impactos para la salud.Ventana de contexto extensa
NotebookLM ofrece una ventana de contexto de 1 millón de tokens, lo que permite interactuar simultáneamente con múltiples documentos extensos: libros completos, artículos científicos y transcripciones de reuniones. A diferencia de otras IAs convencionales, fue diseñado específicamente para "consultar profesionalmente" múltiples archivos: las fuentes permanecen separadas de la ventana de conversación, pero totalmente accesibles para el modelo. Eso le permite conversar largamente con los documentos sin que su tamaño perjudique la memoria de la interacción.
Cada respuesta viene acompañada de la cita exacta del fragmento original del documento, lo que facilita la verificación y aumenta de forma drástica la confiabilidad para uso profesional.
Ecosistema Google: integración y actualización dinámica
NotebookLM se integra con el ecosistema Google, permitiendo usar carpetas y documentos de Google Drive como fuentes. Lo más útil: al conectar un Google Docs como fuente, NotebookLM mantiene el vínculo con el archivo original, que usted puede actualizar cuando quiera. Si detecta cambios en la última versión, NotebookLM habilita un botón para actualizar esa fuente.
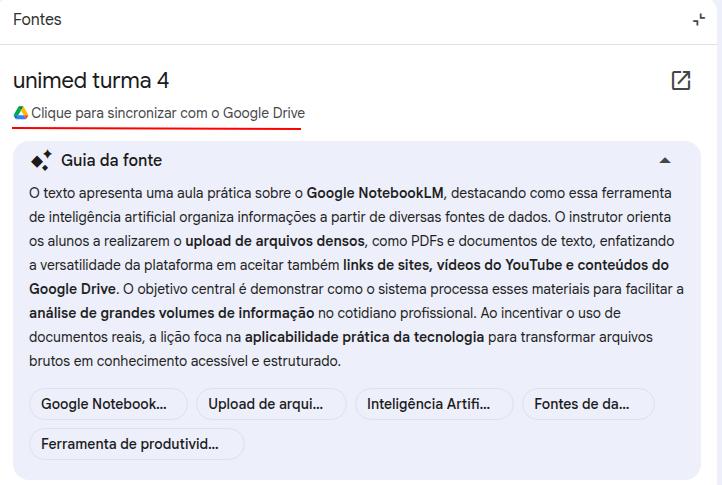
Transcripción de audio y video
NotebookLM permite transcribir audios y videos de forma completa: basta con agregarlos como fuentes y solicitar, mediante prompt, la transcripción del material. También puede incluir instrucciones de énfasis. Imagine, por ejemplo, que grabó una reunión que debe convertirse en acta, o una clase donde el profesor destaca repetidamente información importante. Ejemplos:
Transcribe el material fuente de manera íntegra, identificando, siempre que sea posible, a los distintos interlocutores.
Después, redacta un acta formal de la reunión con los siguientes elementos: fecha, participantes identificados, agenda tratada, decisiones tomadas y tareas pendientes con responsables.NotebookLM gratuito vs. plus
Existen diferencias entre las versiones gratuita y de pago, que afectan la cantidad de notebooks que pueden crearse, el número de fuentes por notebook, la cantidad de recursos generados por día y, subjetivamente, la velocidad de generación de algunos recursos. Mi sugerencia práctica: comience trabajando con la versión gratuita y, solo después de familiarizarse con la herramienta, migre a la versión paga si realmente lo necesita.
- Más de 500 notebooks (vs. 100 en la versión gratuita)
- Generación ilimitada de resúmenes en audio por día
- Audios más largos y detallados
- Integración más profunda con Google Workspace
- Funciones para compartir notebooks con equipos
- Soporte prioritario y acceso anticipado a nuevas funciones
NotebookLM es especialmente útil en contextos académicos. Lo uso mucho para interactuar con textos académicos, como artículos en PDF, y ahora también archivos EPUB.
- Revisión de literatura: añada los artículos seleccionados y use prompts para sintetizar sus hallazgos principales, comparar metodologías o identificar lagunas de conocimiento.
- Estudio de guías: cargue las directrices más recientes de una especialidad y hágales preguntas clínicas directas.
- Preparación de presentaciones: utilice la Guía de estudio y las FAQ para generar preguntas sobre el contenido de clases o conferencias.
- Diario de aprendizaje: mantenga un Google Docs con anotaciones diarias y conéctelo a NotebookLM; al final de la semana, genere un resumen o un quiz de lo aprendido.
- Consejo pro: use NotebookLM como tutor personalizado. Estudie un artículo y explíqueselo a NotebookLM, pidiéndole que corrija y complemente los puntos críticos en los que usted se equivocó o dejó pasar algo importante.
OpenEvidence
¿Qué es OpenEvidence?
OpenEvidence es una plataforma de apoyo a la toma de decisiones clínicas basada en IA, desarrollada específicamente para médicos y profesionales de salud. A diferencia de los modelos de uso general como ChatGPT y Gemini, OpenEvidence fue entrenado y optimizado para consultas médicas, con acceso a literatura médica especializada y curada por su equipo editorial.
La plataforma cuenta con acuerdos de contenido con varias organizaciones de referencia, como NEJM, JAMA, NCCN, Cochrane, Wiley, ACC, ADA y otras sociedades médicas.

¿Cómo funciona?
La lógica es simple y muy parecida a la de otros LLMs:
- Usted hace una pregunta clínica en inglés o portugués
- La herramienta busca en sus propias bases de literatura médica
- Devuelve una respuesta con citas de las fuentes originales y enlaces a los artículos
- Puede hacer preguntas de seguimiento dentro de la misma sesión para profundizar
Access it at: www.openevidence.com
Mejores prácticas de prompt para OpenEvidence
Como ocurre con cualquier herramienta de IA, la calidad de la respuesta depende de la calidad de la pregunta. En OpenEvidence, las siguientes prácticas marcan una diferencia real:
1. Incluya el contexto clínico relevante del paciente
Instead of asking generically, “what is the treatment for hypertension?”, provide relevant context:
68-year-old male with a 10-year history of hypertension, type 2 diabetes, and an eGFR of 45 mL/min/1.73m². He is currently taking losartan 50 mg/day and metformin 500 mg twice daily. Current blood pressure: 155/95 mmHg. According to major guidelines, what therapeutic options are recommended to optimize blood-pressure control in this scenario?2. Especifique el tipo de información deseada
What are the current indications for anticoagulation in non-valvular atrial fibrillation? Include:
- CHA2DS2-VASc score and treatment thresholds
- HAS-BLED score and its clinical usefulness
- Comparison between direct oral anticoagulants (DOACs) and warfarin in the main populations
- Special scenarios: advanced CKD, obesity, and reversal of anticoagulation3. Solicite nivel de evidencia y calidad de los estudios
What is the current evidence on the use of ivermectin for treating COVID-19? Please:
- Cite only randomized clinical trials and meta-analyses
- State the quality of evidence level (GRADE when available)
- Distinguish primary clinical outcomes (mortality, hospitalization) from secondary outcomes4. Compare directamente opciones terapéuticas
Compare the efficacy and safety of SGLT2 inhibitors versus GLP-1 receptor agonists in patients with type 2 diabetes and established cardiovascular disease, based on randomized clinical trials with hard cardiovascular outcomes (MACE, cardiovascular mortality, hospitalization for heart failure).5. Use preguntas de seguimiento para profundizar
OpenEvidence permite preguntas de seguimiento dentro de la misma sesión. Por ejemplo, después de obtener una respuesta sobre el tratamiento inicial, puede preguntar:
What if this patient also has heart failure with reduced ejection fraction (HFrEF)? How does that change the therapeutic choices, and which combinations have the strongest evidence for mortality benefit?Cautelas fundamentales en el uso de OpenEvidence
OpenEvidence es una herramienta poderosa, pero un uso inadecuado puede llevar a errores clínicos. Tres cautelas son especialmente importantes:
1. El prompt orienta la respuesta y puede sesgarla
La forma en que usted construye el prompt influye directamente en lo que la herramienta mostrará. Si pregunta "¿qué evidencias favorecen el uso de X?", la herramienta tenderá a presentar evidencias favorables, incluso cuando existan evidencias contrarias más relevantes o de mejor calidad metodológica. Las preguntas más neutrales generan respuestas más equilibradas. Formular preguntas de manera neutra y verificar activamente si existen evidencias contrarias es una muy buena práctica.
2. La herramienta puede confundir desenlaces primarios con desenlaces secundarios
Un error frecuente, tanto en usuarios como en la herramienta, es tratar desenlaces sustitutos, de laboratorio o radiológicos como si fueran equivalentes a desenlaces clínicos duros. Un antibiótico puede "erradicar" una bacteria sin mejorar la supervivencia del paciente, y un fármaco puede reducir HbA1c sin reducir mortalidad cardiovascular. Pregúntese siempre: ¿el estudio citado mide el desenlace que realmente importa para mi paciente?
3. Saber que una evidencia existe y saber interpretarla son cosas muy distintas
OpenEvidence puede citar un ensayo clínico aleatorizado sin contextualizar adecuadamente la calidad metodológica, el tamaño real del efecto, la aplicabilidad al paciente o el riesgo de sesgo. Conceptos como NNT, intervalos de confianza, heterogeneidad en meta-análisis y calidad GRADE siguen siendo esenciales para interpretar correctamente la evidencia. La herramienta apoya la decisión clínica; no la sustituye.
Cautela adicional: la herramienta no sustituye el juicio clínico individualizado
Las respuestas de OpenEvidence se basan en poblaciones de estudios que pueden no reflejar las características específicas de su paciente, incluidas comorbilidades, interacciones farmacológicas, valores y preferencias. No trate ninguna herramienta de IA, ni siquiera OpenEvidence, como un oráculo definitivo.

Precauciones en el uso de herramientas de IA
Aunque las IAs son herramientas poderosas, su uso exige responsabilidad y conocimiento de sus limitaciones, especialmente en áreas críticas como la salud. A continuación se destacan tres puntos fundamentales de atención.
1) Alucinación (Hallucination)
En IA, el término "alucinación" se refiere a la generación de información que parece correcta y se presenta con alta confianza, pero que en realidad es falsa o inventada. Eso ocurre porque el modelo predice la palabra siguiente más probable, no necesariamente la verdad. En salud, esto puede traducirse en conductas inventadas, dosis incorrectas o citas de artículos inexistentes. Verifique siempre las fuentes.
2) Riesgo de sesgo (Bias)
Los modelos de IA se entrenan con enormes conjuntos de datos de internet, que arrastran los sesgos de la sociedad. Eso puede traducirse en respuestas que perpetúan estereotipos de género, raza o nivel socioeconómico, o en sesgos dentro del razonamiento médico, como subdiagnosticar ciertas condiciones en grupos demográficos específicos. Manténgase atento a estas distorsiones.
3) El paradigma de la "caja negra" (Black Box)
No sabemos exactamente cómo ni por qué una IA llegó a una determinada conclusión. Tampoco sabemos siempre qué materiales se usaron en el entrenamiento ni qué fuentes exactas sustentaron una respuesta concreta. Además, los procesos internos de las redes neuronales siguen siendo complejos y poco transparentes. Eso es crítico en la práctica clínica, donde la explicabilidad es esencial para la seguridad y la confianza.
Cautela extra: la necesidad de revisión humana
Nunca utilice directamente el resultado de una IA para una decisión clínica sin una revisión rigurosa. La herramienta puede servir como apoyo, pero la responsabilidad y el juicio final siguen siendo humanos (human-in-the-loop).
Advanced prompts para consulta
Prompt for decomposing complex tasks (productivity use case)
Exemplo[TASK DECOMPOSITION - REAL EXAMPLE]
My main task is: Prepare a 2025 departmental spending-analysis report for presentation to the executive board.
Please break this down into sequential subtasks, numbered from 1 to N.
For EACH subtask, provide:
- Subtask number and title
- Description of what needs to be done
- Success criterion
- Any prior dependency
- Estimated time
Additional context:
- We have data from three sources: SAP, internal spreadsheets, and department receipts
- The presentation is in 2 weeks
- Audience: 8 non-technical executives
- Expected format: 15-20 slides with the main chartsEjemplo editable
[TASK DECOMPOSITION]
My main task is: [DESCRIBE THE OVERALL TASK]
Please break it into sequential subtasks, numbered from 1 to N.
For EACH subtask, provide:
- Subtask number and title
- Description of what must be done
- Success criterion (how to know it was done well)
- Any prior dependency
- Estimated time
Then present a recommended execution timeline.Cadeia de Pensamento (Chain of Thought)
Ejemplo editable:
[Chain of Thought - EDITABLE]
You are a [SPECIALIST IN WHAT?].
Analyze: [DESCRIBE THE CASE / PROBLEM]
Think step by step:
1. [WHAT IS THE FIRST LOGICAL STEP?]
2. [WHAT IS THE SECOND STEP?]
3. [WHAT IS THE THIRD STEP?]
Respond by detailing each step of your reasoning.Ejemplo completo:
[Chain of Thought - FULL]
You are a project manager. Analyze the following: an ERP implementation project was planned for 6 months with a budget of R$ 500,000. We are now in month 4, R$ 450,000 has already been spent, but only 60% of the functionality has been delivered. The client is dissatisfied.
Think step by step:
1. Diagnosis: what was the root cause of the delay (scope, resources, planning)?
2. Impact analysis: how much extra time and cost will be required?
3. Strategy: what options exist (extension, scope reduction, larger team)?
Respond by detailing each stage.Árvore de Pensamento (Tree of Thought)
Ejemplo editable:
[Tree of Thought - EDITÁVEL]
Analise: [DESCREVA UM CENÁRIO COMPLEXO COM MÚLTIPLAS OPÇÕES]
Elabore uma árvore de pensamentos simulando múltiplos cenários:
Cenário 1: [PRIMEIRA OPÇÃO]
- Sub-consequência 1a: [...]
- Sub-consequência 1b: [...]
- Desfecho provável: [...]
Cenário 2: [SEGUNDA OPÇÃO]
- Sub-consequência 2a: [...]
- Sub-consequência 2b: [...]
- Desfecho provável: [...]
Cenário 3: [TERCEIRA OPÇÃO]
- Sub-consequência 3a: [...]
- Sub-consequência 3b: [...]
- Desfecho provável: [...]
Síntese: Qual cenário apresenta maior probabilidade de sucesso?Ejemplo completo:
[Tree of Thought - COMPLETO]
Uma empresa precisa decidir sobre expansão internacional. Analise os três cenários principais:
Cenário 1: Mercado da Ásia (alto risco, alto retorno)
- Investimento inicial: $10M
- Barreiras regulatórias: altas
- Potencial de mercado: 500M pessoas
- Desfecho provável: Retorno em 4-5 anos se conseguir entrada
Cenário 2: Mercado da América Latina (risco médio, retorno médio)
- Investimento inicial: $5M
- Barreiras regulatórias: médias
- Potencial de mercado: 150M pessoas
- Desfecho provável: Retorno em 2-3 anos
Cenário 3: Mercado Europeu (baixo risco, baixo retorno)
- Investimento inicial: $3M
- Barreiras regulatórias: altas
- Potencial de mercado: 100M pessoas
- Desfecho provável: Retorno estável em 1-2 anos
Síntese: América Latina oferece melhor equilíbrio risco-retorno para expansão no curto prazo.Cadeia de Aprendizagem (Chain of Learning)
Ejemplo editable:
[Chain of Learning - Ejemplo editable]
Actuará como simulador interactivo para mi entrenamiento en [¿QUÉ DOMINIO?].
[Su papel]
1. Cree un escenario o problema inicial sobre [TEMA ESPECÍFICO]
2. No revele la solución de inmediato
3. Proporcione información neutra a medida que yo avance
4. Ajuste la dificultad según mi desempeño
5. Revise mi razonamiento y señale lagunas
[Formato de interacción]
- Yo presento mi análisis o solución
- Usted ofrece retroalimentación constructiva
- Iteramos hasta alcanzar dominio del tema
Estoy listo para comenzar. ¿Cuál es el dominio y el tema?Ejemplo completo:
[Chain of Learning - Ejemplo completo]
Actuará como simulador interactivo para mi entrenamiento en Epidemiología Clínica.
[Su papel como profesor-simulador]
1. Cree un escenario realista de brote epidemiológico (por ejemplo: "Detectamos 15 casos de gastroenteritis en una guardería durante 3 días")
2. No revele de inmediato la etiología más probable
3. Proporcione datos cuando yo los solicite (síntomas, incubación, exposiciones, laboratorio)
4. Aumente la complejidad a medida que demuestre comprensión (por ejemplo: factores de confusión)
5. Revise mi razonamiento epidemiológico (¿fue adecuada mi hipótesis inicial?)
[Mi enfoque]
- Formularé hipótesis sobre la fuente y la vía de transmisión
- Solicitaré datos específicos para probar esas hipótesis
- Usted me dará feedback sobre la adecuación de la investigación
Estoy listo. Presente un escenario de brote.Chain of Verification
Técnica que reduce las alucinaciones al pedirle a la IA que genere preguntas de verificación y revise sus propias premisas antes de ofrecer la respuesta final.
[Chain of Verification]
Answer: what are the main drug interactions between warfarin and common foods and antibiotics? After answering, follow this verification protocol: 1. Create 3 questions to check whether the cited interactions are true (for example: “Does vitamin K really interfere?”). 2. Answer those questions independently. 3. Provide a revised and corrected final answer based on those checks.[Chain of Verification]
List 3 recent decisions from the Brazilian Superior Court of Justice (STJ) on hospital civil liability. Follow the CoVe protocol: 1. Generate questions to confirm case number and year. 2. Answer whether the cases exist and actually concern the topic. 3. Deliver only the confirmed cases.Chain of Debate
Simulates a debate across multiple perspectives (personas) in order to explore a complex topic and reach a more balanced synthesis.
[Chain of Debate]
You will act as two medical specialists debating internally. Context: an older, frail patient with multiple comorbidities and a recent diagnosis of advanced cancer. Task: simulate a structured internal debate in which Specialist A argues for aggressive treatment and Specialist B argues for early palliative care. Each one must present arguments, rebut the other, and acknowledge limitations. Finish with a balanced synthesis.[Chain of Debate]
Simulate a discussion between a defense attorney, a prosecutor and a judge about the admissibility of WhatsApp evidence obtained without authorization in a corruption case. Debate “Fruit of the Poisonous Tree” versus “Public Interest.”Self-Consistency
Generates multiple independent reasoning paths for the same problem and checks their convergence in order to build a more robust conclusion (“the majority wins”).
[Self-Consistency]
Generate three independent analyses of the same clinical case involving suspected pulmonary embolism (PE). Produce three separate diagnostic reasoning paths. Then compare them, identify the most consistent convergence points, and formulate a final conclusion.[Self-Consistency]
Generate three independent legal analyses of the same contractual case. Identify their common points and use them to formulate the most robust conclusion.Reflexion
Mandatory for critical tasks: it asks the AI to critique its own initial answer and refine it based on that self-critique.
[Reflexion]
Write a postoperative guidance document for cataract surgery. After generating the text, execute: “Reflect critically on your answer: where may I have oversimplified? Which assumptions may be wrong? What additional information would change my conclusion?” After that reflection, refine your original answer.[Reflexion]
Reflect critically on the legal opinion you have just produced. Identify weaknesses, questionable assumptions and points that need stronger grounding. Revise the opinion after that analysis.Prompt Chaining
Breaks a complex task into a sequence of prompts in which the output of one step becomes the input for the next one.
[Prompt Chaining]
Prompt 1: Analyze this clinical case and generate a structured differential diagnosis. Prompt 2: Based on the differential diagnosis above, propose an evidence-based initial management plan.[Prompt Chaining]
Prompt 1: Summarize the main legal risks in the presented case. Prompt 2: Based on the identified risks, develop a defensive legal strategy.Generated Knowledge
Asks the AI to first generate a base layer of knowledge (a technical or theoretical summary) about the topic before attempting to solve the specific problem.
[Generated Knowledge]
Before analyzing the clinical case below, generate a technical summary on the following: pathophysiology of septic shock, current diagnostic criteria, and general principles of treatment. Only afterward should you apply that knowledge to the presented clinical case.[Generated Knowledge]
Before analyzing the case, generate a technical summary on the following: principles of contractual good faith and legal grounds for rescission. Then apply that knowledge to the concrete case.Least-to-Most
Estrategia educativa y de resolución de problemas que pide explicar el concepto de lo básico a lo avanzado, o resolver primero subproblemas simples antes de enfrentar el problema complejo.
[Least-to-Most]
First explain, in simple language, what heart failure is. Then: 1. Explain the pathophysiological mechanisms. 2. Differentiate HF with preserved versus reduced ejection fraction. 3. Relate that distinction to therapeutic choice.[Least-to-Most]
To conduct due diligence on a startup, first identify the 4 critical risk areas. Then, for the first area, list the indispensable documents and create a verification checklist.Directional Stimulus
Proporciona "pistas" o señales específicas para orientar el razonamiento de la IA hacia una prioridad deseada (por ejemplo, priorizar la seguridad).
[Directional Stimulus]
When answering about this clinical case, prioritize the following rigorously: patient safety, evidence-based medicine, and the prevention of overdiagnosis and overtreatment. [Describe the clinical case here].
[Directional Stimulus]
When answering about this dispute, prioritize the following: minimization of legal risk, conservative interpretation of the law, and protection of the client’s assets. [Describe the case.]Program-Aided Language
Solicita que la IA use lógica de programación o pseudo-código para estructurar razonamientos lógicos o matemáticos con mayor precisión.
[Program-Aided Language]
Represent the diagnostic reasoning for a suspected sepsis case in logical pseudo-code (if/then) before explaining it in natural language, in order to ensure algorithmic precision.[Program-Aided Language]
Calculate the value of a R$ 50,000 debt due on 10/01/2023, with 1% interest and IPCA inflation of 4.5%. Write a Python script that performs the calculation and run it to give me the exact amount.ReAct (Reasoning + Acting)
Alterna pensamiento (razonamiento) y acción (búsqueda de información o uso de herramientas) en un ciclo continuo para resolver problemas dinámicos.
[ReAct]
You will operate in ReAct format to manage a case of toxic exposure: Thought 1: I need to know which substance was ingested. Action 1: Ask the user. Thought 2: Based on the response, I should check the antidote. Action 2: Provide the dose. Continue the cycle until stabilization.[ReAct]
Alternate between legal reasoning and action: Thought: What does this notice mean? Action: Which document should be reviewed? Thought: What are the implications? Action: What response is recommended? Continue until a final strategy is reached.Contactos


IA e Medicina