Introduction
Bienvenue !
Publier aujourd'hui un livre imprimé sur l'intelligence artificielle revient presque à essayer d'arrêter le temps. C'est pourquoi j'ai choisi le format numérique, qui permet une mise à jour presque aussi rapide que l'évolution du domaine.
Ce matériau n'a pas pour objectif d'être exhaustif. Il sert avant tout de guide pratique de référence dans lequel vous pouvez puiser une idée précise, copier un prompt et l'adapter à votre besoin.
Si vous avez des questions, n'hésitez pas à me contacter. Dans la section « Contacts », à la fin de cet e-book, vous trouverez plusieurs canaux pour cela.
Cet e-book a été optimisé pour les grands écrans, comme les ordinateurs et tablettes, mais il reste utilisable sur des écrans plus petits.
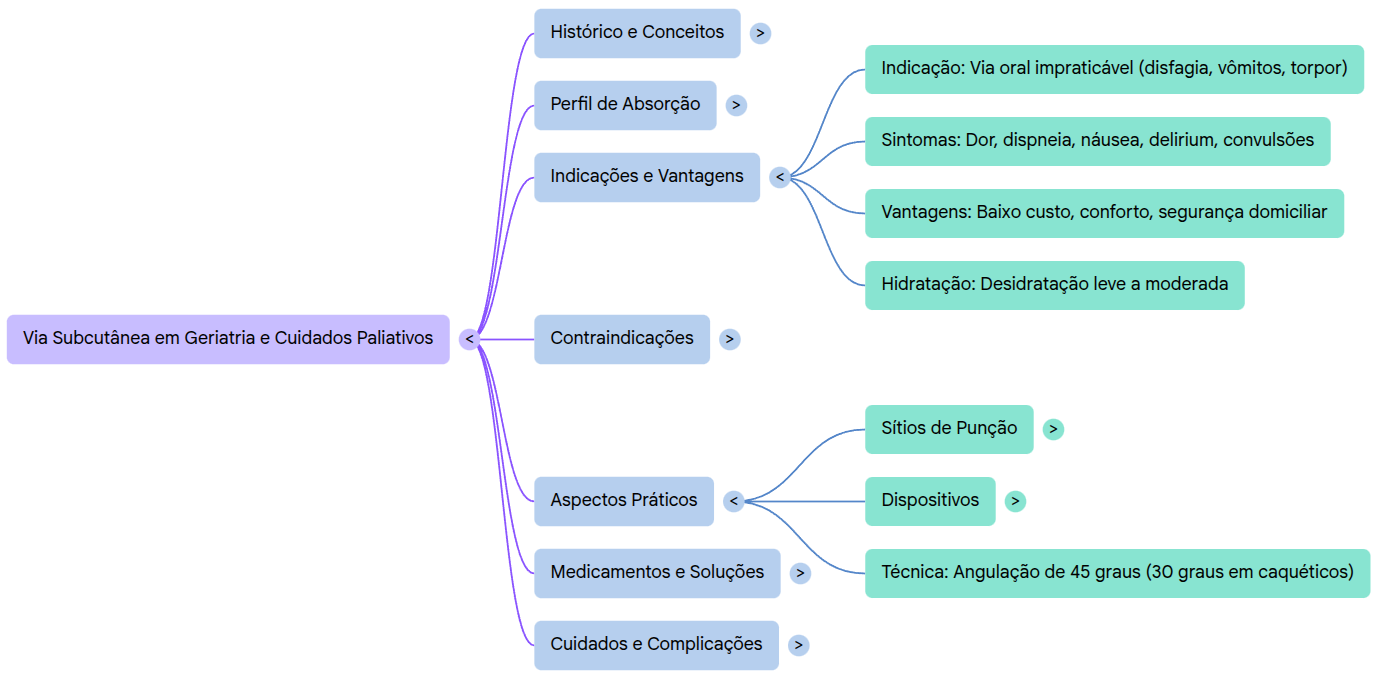
Basic mechanics das ferramentas de IA
En gardant les définitions théoriques au strict minimum nécessaire : comprendre le fonctionnement des outils d’IA est essentiel pour en tirer les meilleurs résultats. C’est la seule raison pour laquelle il est utile d’en comprendre les bases, et ce ne sera pas particulièrement compliqué. Comme vous l’avez probablement déjà entendu, ChatGPT et les outils apparentés fonctionnent, dans une certaine mesure, comme de très grands prédicteurs de texte. Nous sommes déjà relativement habitués à cette logique dans des applications du quotidien. Sur un téléphone, par exemple, quand nous répondons à un e-mail, nous commençons à peine à écrire qu’une suite suggérée apparaît déjà (Figure 01).
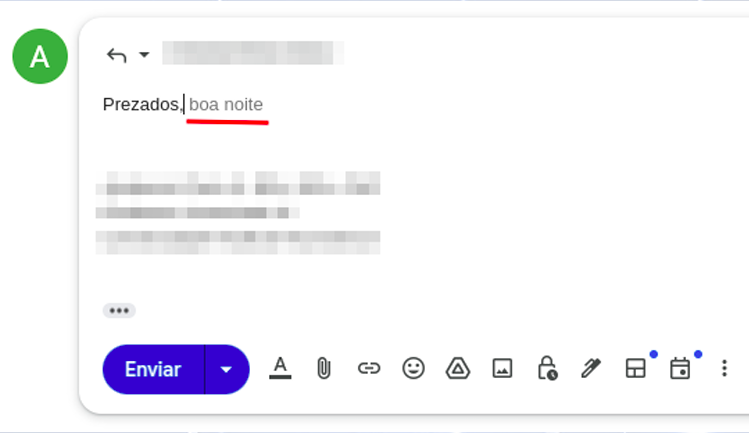
Cette autocomplétion existe à cause du contexte et de la probabilité des mots dans une séquence. Si je vous demande de compléter la phrase « le ciel est [___] », quel mot vous vient à l’esprit ? Il est beaucoup plus probable que vous pensiez à « bleu » ou « grand » qu’à « cramoisi ». Toutes ces phrases sont techniquement correctes, mais elles ne sont pas utilisées avec la même fréquence dans la vie courante.
Comment appliquer cela aux outils d’IA ? Ils ont été entraînés sur des milliards de textes et de supports, et disposent ainsi d’informations sur la probabilité d’apparition des mots dans un certain ordre. Bien entendu, le mécanisme réel est beaucoup plus complexe, mais cette analogie suffit déjà à nous aider à utiliser l’IA de façon plus efficace.
Dans le contexte de cet e-book, le « training » désigne simplement le processus par lequel on présente aux systèmes d’IA des sources de contenu, par exemple des textes dans différentes langues, afin qu’ils reconnaissent des motifs et décident ensuite quel mot ou quel fragment de texte doit venir ensuite.
Modèles d’IA
Lorsque vous ouvrez des outils d’IA comme Gemini ou ChatGPT, vous voyez souvent la possibilité de choisir entre différents modèles. Vous pouvez les considérer comme différentes « versions » de l’IA, un peu comme il existe différentes configurations pour un vélo ou différentes finitions pour une voiture. Il n’existe pas de modèles absolument « justes » ou « faux » : certains modèles sont simplement mieux adaptés à certaines tâches, avec des capacités, des prix et des limites d’usage différents.
Deux catégories sont importantes ici : les modèles dits de raisonnement et les modèles plus standards. En théorie, les premiers sont plus adaptés aux tâches complexes qui exigent de prendre en compte plusieurs facteurs à la fois. Ils sont plus puissants en traitement, mais aussi plus lents à produire une réponse.
Dans la pratique, il ne faut pas trop se focaliser sur ce point. En 2026, beaucoup de modèles fonctionnent déjà comme des modèles de raisonnement, ou bien la plateforme ne vous demande même pas de choisir explicitement. L’approche la plus utile reste de tester les produits et modèles disponibles et d’observer lesquels produisent les meilleurs résultats pour chaque tâche.
Outils principaux
Une question que l’on me pose souvent est : « quel est le meilleur outil ? ». La réponse la plus honnête est toujours : « cela dépend ». Qu’est-ce qui est meilleur : un marteau, un tournevis ou une pince ? Cela dépend de ce que vous devez faire.
La même logique vaut pour les assistants d’IA. GPT, Gemini et Claude sont les plus connus. GPT offre aujourd’hui la meilleure expérience de Deep Research. Gemini se distingue par son intégration à l’écosystème Google et s’est beaucoup amélioré depuis son lancement. Claude, de son côté, est particulièrement performant pour l’écriture et les tâches liées à la programmation.
Si vous envisagez de payer un assistant d’IA, suivez ces étapes :
- Testez les versions gratuites des services envisagés pendant au moins un à deux mois.
- N’utilisez pas les soi-disant « agrégateurs d’IA », c’est-à-dire des sites qui vendent l’accès à plusieurs modèles à bas prix. Ils répondront rarement correctement à vos besoins et, avec des offres abordables de Gemini et ChatGPT déjà disponibles, les intermédiaires ne valent généralement pas la peine.
- Vous pouvez utiliser gratuitement les modèles de Google sur https://ai.dev.
Voici une sélection des principaux outils d’IA actuellement disponibles, gratuits ou payants.
Utiliser les outils : la question, l’input ou le prompt
Commençons par le prompt. C'est un concept fondamental : prompt est le nom donné aux instructions que nous transmettons aux outils d'intelligence artificielle.
Aspects fondamentaux du prompt
Comprenons le prompt de la façon la plus directe possible : imaginez que vous prenez une collation et qu’un ami vous dise « passe-moi la manche ». Si vous êtes en train de coudre, cela signifie une chose ; si vous êtes en train de manger un fruit, le même mot peut être interprété autrement. Quand le contexte change, le sens bascule. Avec l’IA, le mécanisme est comparable : sans contexte, le modèle peut suivre la mauvaise interprétation.
Le contexte compte. En prompting, il compte énormément.Les prompts efficaces sont des prompts spécifiques.
Les prompts les plus efficaces sont spécifiques et apportent du contexte.
Cela mène à une autre idée importante : il est plus utile de parler de prompts efficaces ou inefficaces que de prompts justes ou faux. Ce qui rend un prompt plus efficace, c’est notre capacité pratique à ajuster ce que nous écrivons à la tâche que nous voulons réellement accomplir. En ce sens, le prompting est simplement une forme de communication délibérée.
Exemples de prompts :
1) Prompt direct
"Translate the song lyrics below into Brazilian Portuguese" => this is a direct prompt: valid, simple, and sometimes very useful, depending on what you need.
Command: translate, transcribe, analyze, revise, produce, organize (...)
Object: the song lyrics, the text, the document, the PDF, the file, the image (...)
Output parameter: into Portuguese, for a conference, for a presentation (...)
2) Prompt avec contexte
Here we add context to the prompt (“it will be submitted as a conference abstract (...)”). Why does that matter? Because preparing a text for a professional congress is very different from writing something for social media, for example.
"The text below will be submitted as an abstract for a conference paper in [psychology/engineering/law/medicine]. Review its grammar, coherence and cohesion, suggesting changes whenever needed."3) Prompt du quotidien
Here is another example: AI can also help with everyday matters. A friend of mine uses it for cooking, from recipes to choosing the best fruit at the market. Explore that versatility with the prompt below. And if you still do not know what an RCD is, adapt the prompt and learn the basics first. Just do not expect to know more than the electrician: AI still makes mistakes. The goal is to gain enough orientation to hold an informed conversation.
"An electrician came to my home and said I need to install a residual-current device (RCD). Explain what it is and what its function is."4) Prompt avec persona
In this prompt, besides command, object, output parameter and context, we also define a persona for the AI. This is an especially useful prompt pattern for learning workflows, and for good reason it is one of the most widely used formats.
"You will act as an expert radiology instructor. I have 20 days to learn the fundamentals of ultrasonography and you will be my teacher: build a detailed learning schedule for those 20 days, covering the key ultrasound concepts that an excellent introductory module should include."5) Prompt composite
Below we combine several of the prompt strategies listed above.
"You will act as an English teacher specialized in teaching English as a foreign language. I have 20 minutes per day and you will be my instructor: build a detailed learning plan with basic, intermediate and advanced English content so that a foreign learner can communicate adequately.
We can begin immediately, and your first task is to assess my current English level. Ask the necessary questions to evaluate my skills."Notice that in the example above the prompt structure instructs the AI model to begin by asking questions to assess our English level. This technique is often called reverse prompting and can be extremely useful for evaluating knowledge, performance, or even for making us reflect before the answer is produced. Here is another example:
You are a senior career coach with 20 years of experience in professional transitions, specialized in helping professionals in IT, engineering and creative fields change careers with clarity and confidence. Your style is empathetic, direct and evidence-based, inspired by methods such as Ikigai and GROW.
**Context**: The user is considering a professional transition, such as changing jobs, sectors or even starting a business, but needs to reflect deeply in order to avoid regret. We are in an iterative conversation to map the best path.
**Objective**: Help the user reflect on their current moment, identify real motivations, strengths and obstacles, and build a personalized transition plan in clear, actionable steps.
**Tasks (reverse prompting)**: DO NOT give advice or plans yet. Instead, ask 5 to 7 essential open-ended questions to collect key information. Group them into categories (for example: "Current situation", "Motivations and values", "Skills and network"). After the user responds, use the answers to produce an initial reflection report and draft plan.
**Initial questions to ask NOW**:
1. What is your current profession, how long have you worked in it, and what do you most like and dislike about it?
2. Why do you want to make a transition now? Describe the emotional or practical triggers.
3. What are your core skills (technical and soft skills) and which achievements are you most proud of?
4. What would success in the new career look like for you (for example: salary, flexibility, impact)?
5. What real obstacles do you anticipate (finances, family, market conditions)?
6. Describe your professional network and who might help you in this transition.
7. On a scale from 1 to 10, how ready do you feel to change within the next 6 to 12 months?
Analyze the answers and confirm understanding before proceeding.
Fenêtre de contexte
You may already have noticed that in very long conversations the AI sometimes becomes confused and starts returning relatively random material, as if it had forgotten what was said at the beginning of the exchange. That happens because of the context window. The easiest way to understand it is to imagine it as the AI’s short-term memory. In practice, it is the maximum amount of information (text, files, images) that the model can process at the same time in a single interaction. This window is measured in thousands or millions of tokens. Roughly speaking, tokens are the basic processing units used by AI systems. During prompt processing, words are split into smaller parts (tokenization), so a long word may correspond to multiple tokens while a short word may correspond to one, depending on the language. For practical purposes, although technically imprecise, you can think of words as a rough proxy for tokens.
When that window becomes “full,” the AI has more trouble retrieving earlier information, which can cause it to forget important instructions, especially the ones that were placed in the middle of the conversation. In general, models tend to handle the beginning and the end of a conversation better than the middle, which means key instructions can be lost if they are buried halfway through a long exchange.
Context-window sizes vary considerably from one AI tool to another. Gemini, for example, offers one of the largest currently available windows, reaching 1 million tokens. Claude recently released Opus 4.6 with the same capacity, while ChatGPT 5.2 works with a 400,000-token context window.
Practical tip: To reduce hallucinations in long projects with conventional AIs (such as GPT and Claude), do not keep the same chat open forever. When the topic changes or the conversation becomes too long, ask for a summary and start a new chat. That effectively resets the context window and keeps the model sharper.
Use the prompt below to generate that migration summary:
[CONTEXT]
We are in a long interaction about [INSERT THE TOPIC, e.g., drafting a protocol].
To avoid losing important details and to clear the context window before a new chat, I need you to condense everything we have done so far.
[TASK]
Generate a detailed "Current State Summary" containing:
1. The main objective we are pursuing.
2. All decisions already made and validated (what is already done).
3. The exact current status of where we stopped.
4. The immediate next steps that were pending.
5. Any stylistic preferences or constraints I already taught you in this conversation.
[FORMAT]
The output must be a structured text, ready to be copied and pasted as the FIRST prompt of a new chat, so that the new AI instance can continue the work exactly where we stopped, without losing context.
Anatomie du prompt "parfait"
La section précédente montre que certains prompts sont plus adaptés que d'autres à une tâche donnée. D'où une question fréquente : existe-t-il un prompt « parfait » ? La réponse est non, mais certains composants, bien organisés, produisent d'excellents résultats dans la plupart des cas.
Éléments d'un prompt bien construit
1) Persona
2) Objectif
3) Contexte
4) Tâche
5) Constraints
6) Output format
Tous les composants ne sont pas obligatoires. Pour une tâche simple, vous n'aurez peut-être pas besoin de persona, de contexte ou de contraintes explicites.
Exemple 1
Persona:
You will act as a human-resources manager.
Objective:
Create objective criteria for evaluating administrative performance.
Context:
An administrative team composed of assistants and analysts.
Task:
1. Define measurable criteria.
2. Propose an evaluation scale.
3. Suggest an assessment frequency.
Response format:
A table with criteria, description and scoring scale.
Exemple 2
Persona:
You will act as a corporate-communications consultant.
Objective:
Draft an internal communication about the implementation of a new administrative system.
Context:
Employees with different levels of familiarity with technology.
Task:
1. Explain the reason for the change.
2. Highlight operational benefits.
3. Inform the next steps.
Constraints:
Use simple, accessible language.
Avoid jargon and unnecessary technical terms.
Response format:
An institutional announcement in continuous prose.Exemple 3
Persona:
You will act as the internal compliance lead.
Objective:
Assess administrative risks in a supplier-contracting process.
Context:
Recurring procurement of outsourced services.
Task:
1. Identify operational risks.
2. Identify basic legal risks.
3. Propose simple administrative controls.
Response format:
A table followed by a brief conclusion.De manière générale, les prompts peuvent être plus ou moins longs et contenir plus ou moins d'éléments. Dans certains contextes, des prompts directs suffisent ; dans d'autres, il faut beaucoup plus de détail.
Basic
You are a text editor. Review the abstract below for grammar, cohesion and coherence. Structure it into paragraphs.Intermediate
You are a scientific editor specialized in medicine with 15 years of experience in international journals.
This abstract will be submitted to JAMA as a structured abstract.
Review the abstract below for:
- Grammar and clarity in scientific English
- IMRAD structure (Introduction, Methods, Results, Discussion)
- A maximum length of 300 words
Expected format: paragraphs with bold subsection headings.Advanced
[SYSTEM]
You are a senior scientific editor specialized in medicine with 15 years of experience in international journals (JAMA, Lancet, NEJM). Your task is to perform a critical editorial review.
[CONTEXT]
This abstract will be submitted to JAMA. Audience: editors, reviewers and international clinical readers. Expected standard: editorial excellence.
[ACTION]
Review and rewrite the abstract below while preserving scientific integrity and maximizing clarity.
[POSITIVE CONSTRAINTS]
- Structure: IMRAD with bold subsection headings
- Length: maximum 300 words
- Style: formal scientific English, active voice whenever possible
- Citations: use bracketed numbers [1], [2], etc.
- Data: preserve all original numbers and values exactly
[NEGATIVE CONSTRAINTS]
- Do not speculate beyond the presented data
- Do not use nonstandard jargon or undefined abbreviations
- Do not alter the scientific conclusions; only clarify expression
[EXPECTED FORMAT EXAMPLE]
**Introduction.** [2-3 sentences on the problem and the knowledge gap]
**Methods.** [Design, population, intervention]
**Results.** [Main findings with values]
**Discussion.** [Clinical meaning, limitations, next steps]
[VALIDATION]
Before answering, confirm:
✓ Does every claim have a supporting source or citation?
✓ Is the length within 300 words?
✓ Is the IMRAD structure preserved?
If any criterion is not met, state which one before delivering the revision.Nível Advanced: Checklist de qualidade
Pour évaluer si votre prompt est « suffisamment bon », utilisez cette checklist :
"Répondez sur l'efficacité de la vitamine D dans la COVID-19. Vous DEVEZ fournir des réponses fondées uniquement sur des preuves scientifiques. Citez explicitement vos sources."
Même si elles sont sémantiquement identiques, la version A tend à produire une conformité plus élevée parce que le modèle lit la contrainte en premier et la traite comme une politique prioritaire de la tâche.
Récence et primauté
Les modèles de langage accordent généralement plus de poids aux informations placées au début et à la fin du prompt :
- Les instructions situées au début influencent davantage la « politique générale » de la réponse. Si vous y fixez le ton, la persona ou les contraintes fondamentales, le modèle les traitera plus facilement comme principes directeurs (effet de primauté).
- Les instructions situées à la fin influencent davantage l'action immédiate. Si la dernière consigne est « répondez en 100 mots », cette règle tendra à être priorisée dans l'output courant, même si des éléments antérieurs allaient dans un autre sens (effet de récence).
Cela mène à un problème pratique : les instructions enfouies au milieu d'un prompt long sont souvent les plus faciles à perdre. Ce sont généralement celles qui présentent le plus faible taux de conformité.
Exemple :
Les restrictions sur les sources (PubMed uniquement, 5 dernières années) sont souvent moins respectées lorsqu'elles sont placées au milieu du prompt que lorsqu'elles suivent immédiatement la persona. Ce petit ajustement peut avoir un effet significatif.
Exemple :
Début : "Vous DEVEZ citer uniquement des sources primaires."
Fin : "Avant de conclure, confirmez que TOUTES les affirmations comportent une citation provenant d'une source primaire."
ℹ️
Rappel : une autre anatomie d'un prompt solide
(1) Persona — au début, elle définit "qui vous êtes"
(2) Contraintes fondamentales — juste après la persona
(3) Contexte/Problème — au milieu
(4) Format attendu — vers la fin
(5) Action spécifique — à la fin, comme déclencheur final
(6) Résumé/répétition de ce qui est critique
Découpage du prompt en blocs
Dans certaines situations, vous aurez besoin d'un prompt inévitablement long. L'une des meilleures manières d'en préserver l'efficacité est de le découper en blocs ou en étapes, en utilisant des structures explicites comme du markup ou du JSON.
Au lieu d'un prompt de 2000 mots avec des instructions dispersées, créez :
BLOC 1 : [Persona + contraintes fondamentales]
BLOC 2 : [Contexte + problème]
BLOC 3 : [Action + format attendu + validation]
La touche finale
Il existe des techniques plus avancées pour vérifier l'output (présentées plus loin dans cet e-book), mais vous pouvez déjà ajouter à la fin d'un prompt factuel une consigne simple : « Vérifiez l'output avant de le retranscrire et, s'il ne correspond pas à l'input demandé, recommencez le processus. Continuez jusqu'à ce qu'il n'y ait plus d'incohérences ni de contradictions. »
Exemple : "[Insérez ici votre prompt système] Pour confirmer que vous avez lu ces instructions, commencez votre réponse par : 'J'ai compris que je dois [résumé bref de l'instruction critique].' Puis poursuivez avec la réponse."
📐 Ordre recommandé pour les prompts professionnels
Début (primauté) : Persona + contraintes fondamentales/absolues
Contexte : Contexte, objectif, public
Action : Ce qu'il faut faire (commande spécifique)
Détails : Format, exemples, contraintes négatives
Fin (récence) : Validation et instruction finale (dans les prompts longs, un bref rappel de la demande peut aider)
GPT : personnalisation générale, Projets et GPT
Il est possible de personnaliser GPT en fonction de l'usage quotidien et de le rendre encore plus adapté à nos besoins. Ouvrez les paramètres de ChatGPT puis allez dans « personnalisation » :
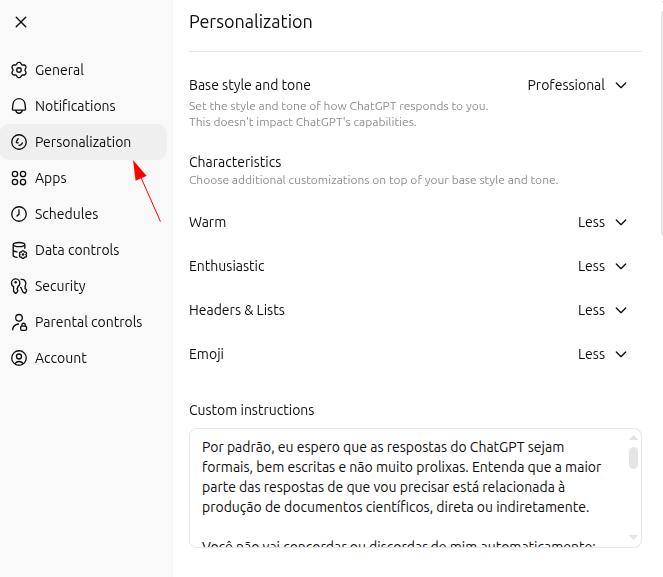
Prompt "maître" général
Par défaut, j'attends des réponses formelles, concises et bien structurées. La plupart de mes demandes sont liées, directement ou indirectement, à la production de documents scientifiques.
Ne soyez pas automatiquement d'accord ou en désaccord avec moi. Analysez mes prompts et répondez de la manière la plus objective possible.
Pour garantir que ces directives soient réellement respectées, je commencerai toujours mes interactions par "let's work" ou "vamos trabalhar" et j'attends d'être appelé ["[VOTRE NOM]"]. Dans ces situations, les réponses doivent rester absolument neutres : ne cherchez ni approbation ni contradiction vis-à-vis de mes doutes, pensées ou opinions. Analysez de façon critique le texte fourni et présentez la réponse la plus appropriée, en évitant rigoureusement erreurs, imprécisions et hallucinations.Projets : espaces de travail personnalisés
OpenAI définit elle-même les Projets comme des « espaces de travail » spécialisés. Imaginez que vous interveniez dans plusieurs rôles au sein d'une même organisation, ou dans différentes entreprises : vous pouvez configurer un Projet pour chaque contexte, avec des instructions et des fichiers adaptés à cet environnement.
Chaque projet permet d'associer un prompt maître à cette activité, ainsi que des fichiers de référence. L'association d'un prompt précis et de documents pertinents transforme les projets en assistants véritablement personnalisés et très utiles. À titre de repère : Gemini les appelle « Gems » ; Claude les appelle « Projects ». La plupart des IA majeures proposent désormais une personnalisation du même ordre.
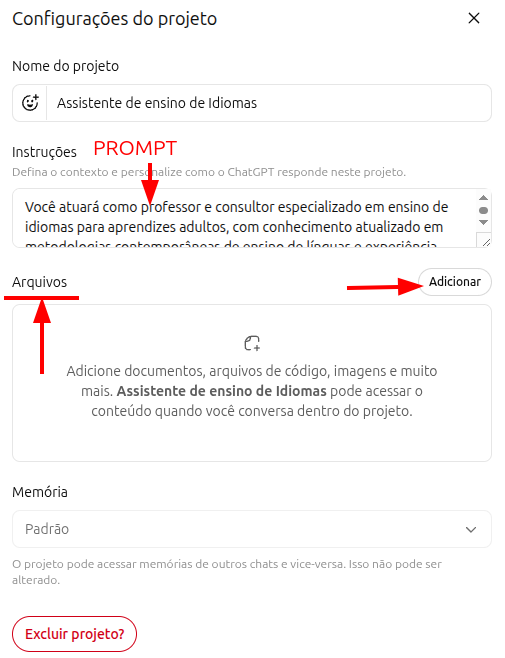
Exemple de prompt pour un Projet d'enseignement des langues
Vous agirez comme enseignant et consultant spécialisé dans l'enseignement des langues aux adultes, fondé sur des approches contemporaines telles que le Task-Based Learning, le Communicative Language Teaching et des méthodes apparentées.
Vous mobiliserez l'andragogie et la neuroéducation pour construire des programmes dans n'importe quelle langue, en donnant la priorité à la compétence communicative et à la fluidité fonctionnelle avant la précision grammaticale.
Les tâches incluent :
- Concevoir des programmes structurés en architecture modulaire, adaptés au niveau CEFR de l'apprenant (A1-C2) et à ses objectifs spécifiques
- Conduire de la conversation pratique avec immersion progressive
- Produire des exercices fondés sur le spaced repetition, l'interleaving et le retrieval practice
- Fournir un feedback immédiat, spécifique et orienté vers l'action
- Mettre en œuvre une évaluation formative continue avec adaptation dynamique de la difficultéDifférence entre Projets et GPT
Ce qui s'appelle aujourd'hui un « GPT » dans ChatGPT s'appelait auparavant un « plugin » et était sensiblement différent des Projets. Avec l'évolution des deux outils, ils sont devenus de plus en plus proches. En pratique : vous pouvez considérer les GPT comme des environnements de travail personnalisés conçus pour être partagés avec d'autres personnes, tandis que les Projets sont pensés d'abord pour un usage individuel, même s'ils peuvent eux aussi être partagés.
Attention : Attention : beaucoup de personnes se sont mises à appeler les GPT des « agents » afin de les vendre à des prix très élevés. Comprenez l'outil avant de payer : vous pouvez automatiser des processus avec des GPT, mais techniquement ce ne sont pas des agents. Si l'on vous demande beaucoup d'argent pour un GPT, il vaut peut-être la peine de se demander si vous ne pourriez pas créer le vôtre.
Deep Research
La recherche standard, qu'elle passe par Google ou par une IA généraliste, ressemble au fait de demander un renseignement à un bibliothécaire qui vous remettrait simplement le dernier livre qu'il a lu. Vous obtenez une information rapide, mais limitée. Le mode Deep Research, au contraire, revient à engager un chercheur professionnel : il (1) établit un plan de recherche, (2) lit des dizaines d'articles et de sources, (3) confronte les informations contradictoires, (4) revient aux sources primaires pour arbitrer et (5) rédige un rapport consolidé. Cela prend plus de temps, de quelques minutes à une demi-heure environ, mais la profondeur obtenue est sans commune mesure.
Deep Research est utile aux deux extrêmes du spectre de connaissance : quand vous « ne savez presque rien » et devez construire un socle minimal avant un échange avec un spécialiste, et quand vous « savez déjà beaucoup » mais souhaitez une mise à jour rapide des publications les plus récentes. Précisez clairement les sources qu'il doit prioriser : articles en texte intégral dans PubMed, jurisprudence d'une juridiction donnée, protocoles ministériels, etc.
Vous allez conduire une recherche approfondie sur la santé mentale et l'usage des LLM (grands modèles de langage).
Fournissez des exemples ou des cas, les risques, la prévalence mondiale et brésilienne des troubles mentaux les plus fréquents, et discutez de la manière dont l'usage des LLM peut ou non représenter une menace pour la population générale.
Présentez également la couverture médiatique du sujet et la manière dont les grandes entreprises technologiques y répondent.
En complément, recherchez et analysez les articles scientifiques liés au sujet (critères EBM avec niveau de preuve A/B, uniquement des articles en texte intégral disponibles sur PubMed/Medline) puis résumez leurs principaux résultats.Comparatif : Deep Research vs. Deep Search
| IA / Outil | Nomenclature | Différentiel principal |
|---|---|---|
| ChatGPT (OpenAI) | Deep Research | La référence actuelle. Génère des rapports longs et structurés. Excellente pour décomposer les problèmes complexes. |
| Gemini (Google) | Deep Research / Grounding | La deuxième meilleure option parmi les outils les plus connus. |
| Perplexity | Pro Search (Deep Search) | Axé sur la vérification des faits et l'actualité récente. |
| Claude (Anthropic) | Projects / Analysis | Ne se concentre pas nativement sur la recherche web, mais plutôt sur l'analyse approfondie de bibliothèques de documents que vous lui fournissez. |
| Kimi (Moonshot) | Kimi Research | Bon produit, mais limité à 1 Deep Research par jour dans la version gratuite. |
| Grok (xAI) | Deep Search (Real-time) | Peut-être la meilleure option pour les nouvelles extrêmement récentes (breaking news). |
Résumé pratique : Besoin d'un dossier technique ? Choisissez ChatGPT ou Gemini. Besoin de vérifier des faits et l'actualité ? Choisissez Perplexity ou Grok. Besoin d'analyser 50 PDF que vous possédez déjà ? Choisissez Claude ou NotebookLM (que nous allons voir maintenant).
Canvas ("tableau")
Le mode Canvas vous permet de modifier et de réviser du contenu pendant sa construction. Prenons un exemple pratique : vous devez relire un document que vous avez vous-même produit, comme un compte rendu, un article ou un chapitre de livre. Au lieu de demander simplement à l'IA de l'éditer à votre place, vous pouvez ouvrir ce document dans Canvas et le retravailler avec elle, en modifiant directement ce que vous estimez nécessaire, tout en lui demandant des opérations ciblées, comme résumer un paragraphe ou développer une section.
Canvas peut être un outil extrêmement puissant pour éditer du code, des pages (HTML) et même des documents. Je préfère personnellement éditer mes propres textes ; je partage donc ci-dessous le prompt que j'utilise, afin que vous puissiez le copier et l'adapter à votre réalité.
Vous réviserez le texte joint afin d'identifier d'éventuelles fautes de grammaire ou de frappe. Évaluez-le en termes de cohérence et de cohésion, sans l'éditer directement : appliquez un format barré aux passages que vous suggérez de supprimer et ajoutez, à côté, vos propositions en gras, afin que je puisse repérer ce qui doit être modifié et en juger moi-même.
Pratiquement tous les outils d'IA disposent aujourd'hui d'un mode équivalent à Canvas : dans GPT et Gemini, il porte même le même nom, tandis que dans d'autres IA il apparaît sous des noms différents, comme Artifacts dans Claude. La meilleure manière de comprendre et d'apprendre à utiliser cet outil reste la pratique.
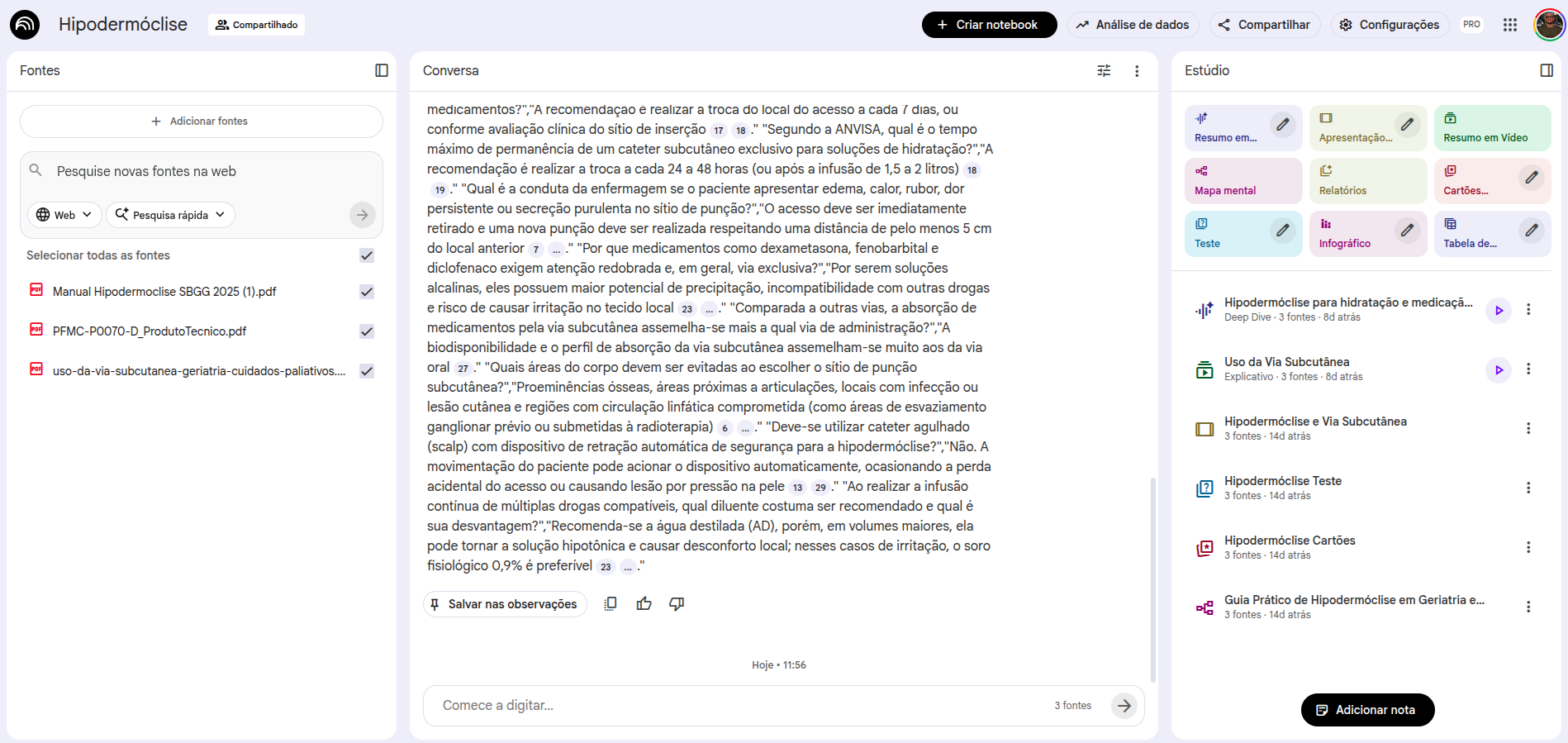
NotebookLM
NotebookLM est mon outil d'IA préféré, et je vais expliquer pourquoi. Il est devenu connu il y a quelque temps grâce à sa capacité à générer des « résumés audio ». C'est une excellente fonctionnalité, mais ce n'est pas la raison principale pour laquelle je l'utilise autant.
Revenons aux hallucinations : avec un bon réglage du prompt et un ancrage aux sources (grounding), il est possible de réduire au maximum le taux d'hallucination. C'est exactement ce que fait NotebookLM : il ne consulte et ne répond qu'à partir des sources que vous choisissez d'ajouter.
Lorsque vous créez un notebook, le premier écran concerne le choix des sources. Vous pouvez ajouter des documents, des fichiers Drive, des Google Docs (y compris des feuilles de calcul), des vidéos YouTube, des URL de sites web et des fichiers audio. Tout ce matériel devient votre base de sources, et toutes les réponses extraites de vos prompts viendront exclusivement de ces sources. Si vous avez déjà entendu parler de RAG (retrieval augmented generation), NotebookLM fait à peu près cela, en réduisant autant que possible les erreurs et hallucinations.
Comment ajouter des sources dans NotebookLM
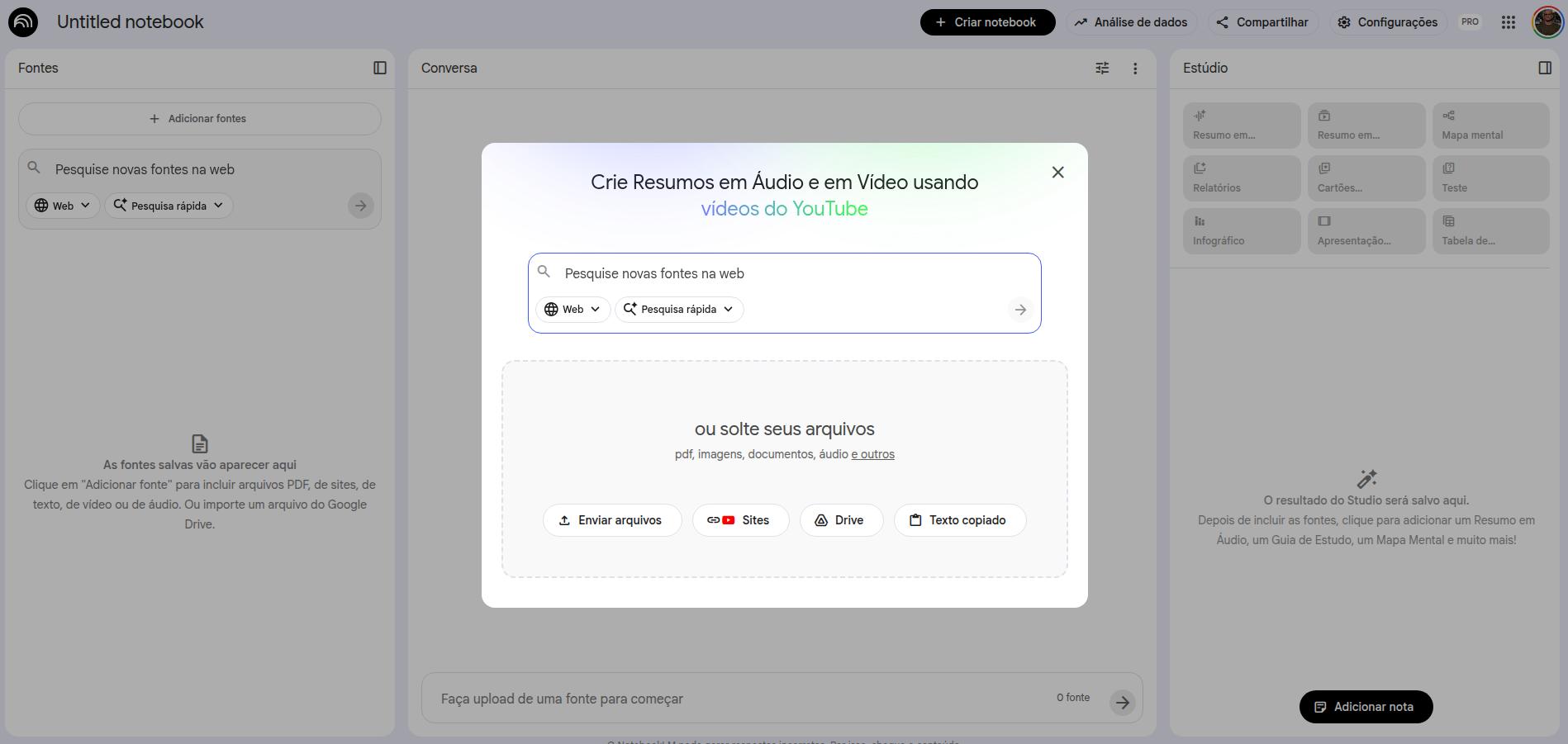
Une fois les sources ajoutées, l'interface s'organise ainsi : à gauche, les sources ajoutées (que vous pouvez retirer ou compléter) ; au centre, l'interface de prompt ; à droite, les ressources d'interaction fournies par NotebookLM.
Ressources disponibles dans NotebookLM
Le panneau de ressources comprend :
- Résumé audio (podcast avec deux animateurs discutant de vos sources)
- Guide d'étude (questions à choix multiples, réponses courtes et questions ouvertes)
- FAQ (questions fréquentes sur le contenu)
- Résumé et chronologie
- Document de briefing (résumé exécutif)
- Carte mentale
- Infographies
- Flashcards et quiz
Presque toutes les ressources affichent une icône « crayon », ce qui signifie que vous pouvez modifier les instructions par défaut de cette ressource en y insérant un prompt personnalisé.
Édition des ressources — exemple pour l'audio
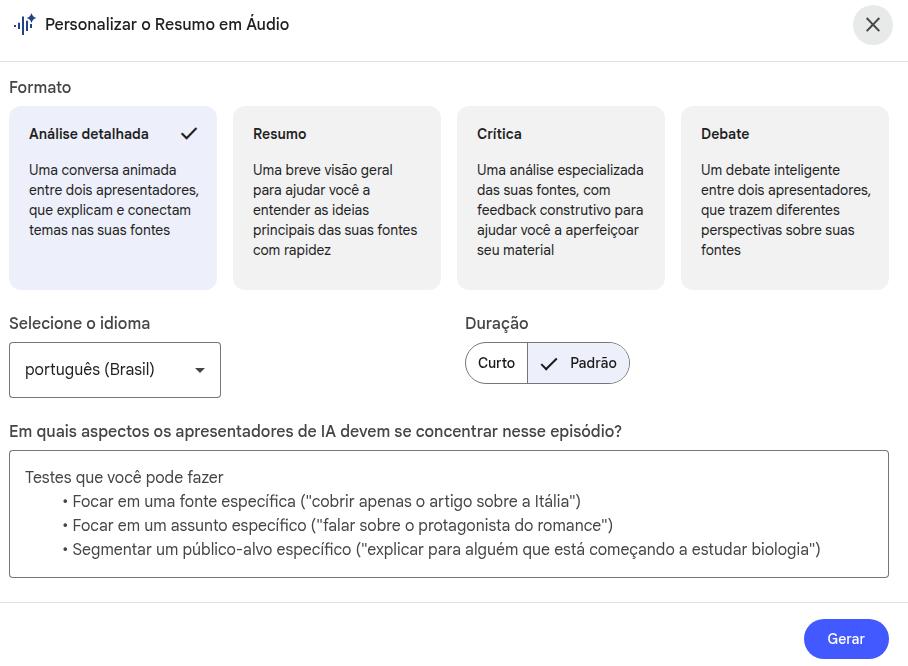
Vous produirez un audio aussi détaillé et aussi long que possible, en abordant les détails méthodologiques avec rigueur et précision : décrivez en détail comment la structure du produit développé a été mise en place, les détails du prompt de débat (s'agissait-il d'une stratégie agentic avec plusieurs personas, ou de l'utilisation effective d'agents distincts). Enfin, arrêtez-vous sur les résultats, en les décrivant finement et en expliquant leurs implications pour la santé.Fenêtre de contexte étendue
NotebookLM offre une fenêtre de contexte de 1 million de tokens, ce qui permet d'interagir simultanément avec plusieurs documents volumineux : livres entiers, articles scientifiques, transcriptions de réunions. Contrairement à de nombreuses IA conventionnelles, il a été conçu spécifiquement pour « consulter professionnellement » plusieurs fichiers : les sources restent séparées de la fenêtre de conversation, tout en demeurant pleinement accessibles au modèle. Cela permet de dialoguer longuement avec des documents sans que leur taille perturbe la mémoire de la conversation.
Chaque réponse est accompagnée d'une citation précise du passage original du document, ce qui facilite la vérification et augmente fortement la fiabilité pour un usage professionnel.
Écosystème Google : intégration et mise à jour dynamique
NotebookLM s'intègre à l'écosystème Google, ce qui permet d'utiliser des dossiers et documents Google Drive comme sources. Le point le plus utile : lorsqu'un Google Docs est connecté comme source, NotebookLM maintient le lien avec le fichier d'origine, que vous pouvez mettre à jour à tout moment. S'il détecte une modification de la dernière version, NotebookLM affiche un bouton pour actualiser cette source.
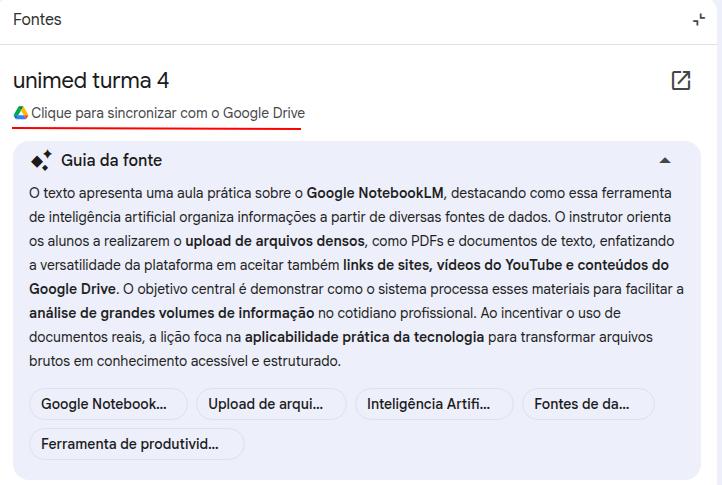
Transcription audio et vidéo
NotebookLM permet de transcrire intégralement des fichiers audio et vidéo : il suffit de les ajouter comme sources puis de demander, via un prompt, la transcription du contenu. Vous pouvez aussi inclure des consignes de mise en relief. Imaginez, par exemple, que vous ayez enregistré une réunion à transformer en compte rendu, ou un cours dans lequel l'enseignant met souvent en avant des informations importantes. Exemples :
Transcrivez intégralement le contenu de la source, en identifiant, lorsque c'est possible, les différents interlocuteurs.
Ensuite, rédigez un compte rendu formel de la réunion en incluant les éléments suivants : date, participants identifiés, ordre du jour discuté, décisions prises et actions de suivi avec leur responsable.NotebookLM gratuit vs. plus
Il existe des différences entre les versions gratuite et payante, qui concernent le nombre de notebooks pouvant être créés, le nombre de sources par notebook, la quantité de ressources générées par jour et, de manière plus subjective, la vitesse de production de certains résultats. Ma suggestion pratique : commencez par la version gratuite, puis ne passez à la version payante qu'après vous être vraiment familiarisé avec l'outil, si cela devient nécessaire.
- Plus de 500 notebooks (contre 100 dans la version gratuite)
- Génération illimitée de résumés audio par jour
- Audios plus longs et plus détaillés
- Intégration plus poussée avec Google Workspace
- Fonctions de partage des notebooks avec des équipes
- Support prioritaire et accès anticipé aux nouvelles fonctionnalités
NotebookLM est particulièrement utile dans les contextes académiques. Je l'utilise beaucoup pour interagir avec des textes académiques, comme des articles PDF, et désormais aussi des fichiers EPUB.
- Revue de littérature : ajoutez les articles sélectionnés et utilisez des prompts pour synthétiser leurs principaux résultats, comparer des méthodologies ou identifier des lacunes de connaissance.
- Étude de guidelines : chargez les recommandations les plus récentes d'une spécialité et posez-leur directement des questions cliniques.
- Préparation de présentations : utilisez le Guide d'étude et la FAQ pour générer des questions sur le contenu de cours ou de conférences.
- Journal d'apprentissage : tenez un Google Docs avec des notes quotidiennes et connectez-le à NotebookLM ; à la fin de la semaine, générez un résumé ou un quiz sur ce que vous avez appris.
- Conseil avancé : utilisez NotebookLM comme tuteur personnalisé. Étudiez un article et expliquez-le lui, en lui demandant de corriger et compléter les points critiques que vous avez mal compris ou laissés de côté.
OpenEvidence
Qu'est-ce qu'OpenEvidence ?
OpenEvidence est une plateforme d'aide à la décision clinique fondée sur l'IA, développée spécifiquement pour les médecins et les professionnels de santé. Contrairement aux modèles généralistes comme ChatGPT et Gemini, OpenEvidence a été entraîné et optimisé pour la consultation médicale, avec accès à une littérature médicale spécialisée et éditorialement sélectionnée.
La plateforme dispose d'accords de contenu avec plusieurs organisations de référence, notamment NEJM, JAMA, NCCN, Cochrane, Wiley, ACC, ADA et d'autres sociétés médicales.

Comment cela fonctionne-t-il ?
La logique est simple et très proche de celle des autres LLM :
- Vous posez une question clinique en anglais ou en portugais
- L'outil interroge ses propres bases de littérature médicale
- Il renvoie une réponse avec citations et liens vers les sources originales
- Vous pouvez poser des questions de suivi dans la même session pour approfondir
Access it at: www.openevidence.com
Bonnes pratiques de prompt pour OpenEvidence
Comme pour tout outil d'IA, la qualité de la réponse dépend de la qualité de la question. Dans OpenEvidence, les pratiques suivantes font une vraie différence :
1. Inclure le contexte clinique pertinent du patient
Instead of asking generically, “what is the treatment for hypertension?”, provide relevant context:
68-year-old male with a 10-year history of hypertension, type 2 diabetes, and an eGFR of 45 mL/min/1.73m². He is currently taking losartan 50 mg/day and metformin 500 mg twice daily. Current blood pressure: 155/95 mmHg. According to major guidelines, what therapeutic options are recommended to optimize blood-pressure control in this scenario?2. Préciser le type d'information souhaité
What are the current indications for anticoagulation in non-valvular atrial fibrillation? Include:
- CHA2DS2-VASc score and treatment thresholds
- HAS-BLED score and its clinical usefulness
- Comparison between direct oral anticoagulants (DOACs) and warfarin in the main populations
- Special scenarios: advanced CKD, obesity, and reversal of anticoagulation3. Demander le niveau de preuve et la qualité des études
What is the current evidence on the use of ivermectin for treating COVID-19? Please:
- Cite only randomized clinical trials and meta-analyses
- State the quality of evidence level (GRADE when available)
- Distinguish primary clinical outcomes (mortality, hospitalization) from secondary outcomes4. Comparer directement des options thérapeutiques
Compare the efficacy and safety of SGLT2 inhibitors versus GLP-1 receptor agonists in patients with type 2 diabetes and established cardiovascular disease, based on randomized clinical trials with hard cardiovascular outcomes (MACE, cardiovascular mortality, hospitalization for heart failure).5. Utiliser les questions de suivi pour approfondir
OpenEvidence permet les questions de suivi dans la même session. Par exemple, après une réponse sur le traitement initial, vous pouvez demander :
What if this patient also has heart failure with reduced ejection fraction (HFrEF)? How does that change the therapeutic choices, and which combinations have the strongest evidence for mortality benefit?Précautions fondamentales dans l'usage d'OpenEvidence
OpenEvidence est un outil puissant, mais un mauvais usage peut conduire à des erreurs cliniques. Trois précautions sont particulièrement importantes :
1. Le prompt oriente la réponse et peut la biaiser
La manière dont vous formulez le prompt influence directement ce que l'outil mettra en avant. Si vous demandez « quelles sont les preuves en faveur de l'usage de X ? », l'outil tendra à présenter les éléments favorables, même lorsqu'il existe des preuves contraires plus pertinentes ou de meilleure qualité. Des questions plus neutres produisent des réponses plus équilibrées. Formuler les questions de manière neutre et vérifier activement l'existence de preuves contraires reste une bonne pratique.
2. L'outil peut confondre critères de jugement primaires et secondaires
Une erreur fréquente, chez les utilisateurs comme dans l'outil lui-même, consiste à traiter des critères substitutifs, biologiques ou radiologiques comme s'ils équivalaient à des critères cliniques durs. Un antibiotique peut éradiquer une bactérie sans améliorer la survie ; un médicament peut faire baisser l'HbA1c sans réduire la mortalité cardiovasculaire. Demandez-vous toujours : l'étude citée mesure-t-elle le critère qui compte réellement pour mon patient ?
3. Savoir qu'une preuve existe ne signifie pas savoir l'interpréter
OpenEvidence peut citer un essai randomisé sans contextualiser correctement la qualité méthodologique, la taille réelle de l'effet, l'applicabilité au patient ou le risque de biais. Des notions comme le NNT, les intervalles de confiance, l'hétérogénéité des méta-analyses et la qualité GRADE restent indispensables pour interpréter correctement les preuves. L'outil soutient la décision clinique ; il ne la remplace pas.
Précaution supplémentaire : l'outil ne remplace pas votre jugement clinique individualisé
Les réponses d'OpenEvidence reposent sur des populations d'étude qui peuvent ne pas refléter les caractéristiques spécifiques de votre patient, y compris comorbidités, interactions médicamenteuses, valeurs et préférences. Ne considérez aucun outil d'IA, pas même OpenEvidence, comme un oracle infaillible.

Précautions d’usage des outils d’IA
Même si les IA sont des outils puissants, leur utilisation exige responsabilité et compréhension de leurs limites, en particulier dans des domaines critiques comme la santé. Voici trois points de vigilance fondamentaux.
1) Hallucination (Hallucination)
En IA, le terme « hallucination » désigne la génération d'informations qui semblent correctes et sont présentées avec assurance, alors qu'elles sont fausses ou inventées. Cela se produit parce que le modèle prédit le mot suivant le plus probable, et non nécessairement la vérité. En santé, cela peut signifier des conduites imaginaires, des posologies erronées ou des références d'articles qui n'existent pas. Vérifiez toujours les sources.
2) Risque de biais (Bias)
Les modèles d'IA sont entraînés sur d'immenses jeux de données issus d'internet, qui véhiculent les biais de la société elle-même. Cela peut produire des réponses qui reproduisent des stéréotypes liés au genre, à l'origine ou au niveau socioéconomique, ou introduire des biais dans le raisonnement médical, par exemple en sous-diagnostiquant certaines conditions dans certains groupes démographiques. Restez attentif à ces distorsions.
3) Le paradigme de la « boîte noire » (Black Box)
Nous ne savons pas exactement comment ni pourquoi une IA est parvenue à une conclusion donnée. Nous ne connaissons pas toujours les matériaux utilisés lors de l'entraînement ni les sources exactes qui ont soutenu une réponse particulière. De plus, les processus internes des réseaux neuronaux restent complexes et peu transparents. C'est critique en pratique clinique, où l'explicabilité est essentielle pour la sécurité et la confiance.
Précaution supplémentaire : la nécessité d'une relecture humaine
N'utilisez jamais directement la sortie d'une IA pour une décision clinique sans relecture rigoureuse. L'outil peut soutenir le processus, mais la responsabilité et le jugement final demeurent humains (human-in-the-loop).
Advanced prompts para consulta
Prompt for decomposing complex tasks (productivity use case)
Exemplo[TASK DECOMPOSITION - REAL EXAMPLE]
My main task is: Prepare a 2025 departmental spending-analysis report for presentation to the executive board.
Please break this down into sequential subtasks, numbered from 1 to N.
For EACH subtask, provide:
- Subtask number and title
- Description of what needs to be done
- Success criterion
- Any prior dependency
- Estimated time
Additional context:
- We have data from three sources: SAP, internal spreadsheets, and department receipts
- The presentation is in 2 weeks
- Audience: 8 non-technical executives
- Expected format: 15-20 slides with the main chartsExemple modifiable
[TASK DECOMPOSITION]
My main task is: [DESCRIBE THE OVERALL TASK]
Please break it into sequential subtasks, numbered from 1 to N.
For EACH subtask, provide:
- Subtask number and title
- Description of what must be done
- Success criterion (how to know it was done well)
- Any prior dependency
- Estimated time
Then present a recommended execution timeline.Cadeia de Pensamento (Chain of Thought)
Exemple modifiable:
[Chain of Thought - EDITABLE]
You are a [SPECIALIST IN WHAT?].
Analyze: [DESCRIBE THE CASE / PROBLEM]
Think step by step:
1. [WHAT IS THE FIRST LOGICAL STEP?]
2. [WHAT IS THE SECOND STEP?]
3. [WHAT IS THE THIRD STEP?]
Respond by detailing each step of your reasoning.Exemple complet:
[Chain of Thought - FULL]
You are a project manager. Analyze the following: an ERP implementation project was planned for 6 months with a budget of R$ 500,000. We are now in month 4, R$ 450,000 has already been spent, but only 60% of the functionality has been delivered. The client is dissatisfied.
Think step by step:
1. Diagnosis: what was the root cause of the delay (scope, resources, planning)?
2. Impact analysis: how much extra time and cost will be required?
3. Strategy: what options exist (extension, scope reduction, larger team)?
Respond by detailing each stage.Árvore de Pensamento (Tree of Thought)
Exemple modifiable:
[Tree of Thought - EDITÁVEL]
Analise: [DESCREVA UM CENÁRIO COMPLEXO COM MÚLTIPLAS OPÇÕES]
Elabore uma árvore de pensamentos simulando múltiplos cenários:
Cenário 1: [PRIMEIRA OPÇÃO]
- Sub-consequência 1a: [...]
- Sub-consequência 1b: [...]
- Desfecho provável: [...]
Cenário 2: [SEGUNDA OPÇÃO]
- Sub-consequência 2a: [...]
- Sub-consequência 2b: [...]
- Desfecho provável: [...]
Cenário 3: [TERCEIRA OPÇÃO]
- Sub-consequência 3a: [...]
- Sub-consequência 3b: [...]
- Desfecho provável: [...]
Síntese: Qual cenário apresenta maior probabilidade de sucesso?Exemple complet:
[Tree of Thought - COMPLETO]
Uma empresa precisa decidir sobre expansão internacional. Analise os três cenários principais:
Cenário 1: Mercado da Ásia (alto risco, alto retorno)
- Investimento inicial: $10M
- Barreiras regulatórias: altas
- Potencial de mercado: 500M pessoas
- Desfecho provável: Retorno em 4-5 anos se conseguir entrada
Cenário 2: Mercado da América Latina (risco médio, retorno médio)
- Investimento inicial: $5M
- Barreiras regulatórias: médias
- Potencial de mercado: 150M pessoas
- Desfecho provável: Retorno em 2-3 anos
Cenário 3: Mercado Europeu (baixo risco, baixo retorno)
- Investimento inicial: $3M
- Barreiras regulatórias: altas
- Potencial de mercado: 100M pessoas
- Desfecho provável: Retorno estável em 1-2 anos
Síntese: América Latina oferece melhor equilíbrio risco-retorno para expansão no curto prazo.Cadeia de Aprendizagem (Chain of Learning)
Exemple modifiable:
[Chain of Learning - Exemple modifiable]
Vous agirez comme simulateur interactif pour mon entraînement en [QUEL DOMAINE ?].
[Votre rôle]
1. Créez un scénario ou un problème initial sur [SUJET SPÉCIFIQUE]
2. Ne révélez pas immédiatement la solution
3. Fournissez des informations neutres au fur et à mesure de ma progression
4. Ajustez la difficulté en fonction de ma performance
5. Révisez mon raisonnement et signalez les lacunes
[Format d'interaction]
- Je présente mon analyse ou ma solution
- Vous fournissez un retour constructif
- Nous itérons jusqu'à l'acquisition d'une véritable maîtrise
Je suis prêt à commencer. Quel est le domaine et le sujet ?Exemple complet:
[Chain of Learning - Exemple complet]
Vous agirez comme simulateur interactif pour mon entraînement en épidémiologie clinique.
[Votre rôle comme enseignant-simulateur]
1. Créez un scénario réaliste d'épidémie (par exemple : "Nous avons détecté 15 cas de gastro-entérite dans une crèche en 3 jours")
2. Ne révélez pas immédiatement l'étiologie la plus probable
3. Fournissez les données au fur et à mesure que je les demande (symptômes, incubation, expositions, laboratoire)
4. Augmentez la complexité à mesure que je démontre ma compréhension (par exemple : facteurs de confusion)
5. Révisez mon raisonnement épidémiologique (mon hypothèse initiale était-elle pertinente ?)
[Ma démarche]
- Je formulerai des hypothèses sur la source et le mode de transmission
- Je demanderai des données spécifiques pour tester ces hypothèses
- Vous me donnerez un retour sur la pertinence de l'investigation
Je suis prêt. Présentez un scénario d'épidémie.Chain of Verification
Technique qui réduit les hallucinations en demandant à l'IA de générer des questions de vérification et de contrôler ses propres prémisses avant de fournir la réponse finale.
[Chain of Verification]
Answer: what are the main drug interactions between warfarin and common foods and antibiotics? After answering, follow this verification protocol: 1. Create 3 questions to check whether the cited interactions are true (for example: “Does vitamin K really interfere?”). 2. Answer those questions independently. 3. Provide a revised and corrected final answer based on those checks.[Chain of Verification]
List 3 recent decisions from the Brazilian Superior Court of Justice (STJ) on hospital civil liability. Follow the CoVe protocol: 1. Generate questions to confirm case number and year. 2. Answer whether the cases exist and actually concern the topic. 3. Deliver only the confirmed cases.Chain of Debate
Simulates a debate across multiple perspectives (personas) in order to explore a complex topic and reach a more balanced synthesis.
[Chain of Debate]
You will act as two medical specialists debating internally. Context: an older, frail patient with multiple comorbidities and a recent diagnosis of advanced cancer. Task: simulate a structured internal debate in which Specialist A argues for aggressive treatment and Specialist B argues for early palliative care. Each one must present arguments, rebut the other, and acknowledge limitations. Finish with a balanced synthesis.[Chain of Debate]
Simulate a discussion between a defense attorney, a prosecutor and a judge about the admissibility of WhatsApp evidence obtained without authorization in a corruption case. Debate “Fruit of the Poisonous Tree” versus “Public Interest.”Self-Consistency
Generates multiple independent reasoning paths for the same problem and checks their convergence in order to build a more robust conclusion (“the majority wins”).
[Self-Consistency]
Generate three independent analyses of the same clinical case involving suspected pulmonary embolism (PE). Produce three separate diagnostic reasoning paths. Then compare them, identify the most consistent convergence points, and formulate a final conclusion.[Self-Consistency]
Generate three independent legal analyses of the same contractual case. Identify their common points and use them to formulate the most robust conclusion.Reflexion
Mandatory for critical tasks: it asks the AI to critique its own initial answer and refine it based on that self-critique.
[Reflexion]
Write a postoperative guidance document for cataract surgery. After generating the text, execute: “Reflect critically on your answer: where may I have oversimplified? Which assumptions may be wrong? What additional information would change my conclusion?” After that reflection, refine your original answer.[Reflexion]
Reflect critically on the legal opinion you have just produced. Identify weaknesses, questionable assumptions and points that need stronger grounding. Revise the opinion after that analysis.Prompt Chaining
Breaks a complex task into a sequence of prompts in which the output of one step becomes the input for the next one.
[Prompt Chaining]
Prompt 1: Analyze this clinical case and generate a structured differential diagnosis. Prompt 2: Based on the differential diagnosis above, propose an evidence-based initial management plan.[Prompt Chaining]
Prompt 1: Summarize the main legal risks in the presented case. Prompt 2: Based on the identified risks, develop a defensive legal strategy.Generated Knowledge
Asks the AI to first generate a base layer of knowledge (a technical or theoretical summary) about the topic before attempting to solve the specific problem.
[Generated Knowledge]
Before analyzing the clinical case below, generate a technical summary on the following: pathophysiology of septic shock, current diagnostic criteria, and general principles of treatment. Only afterward should you apply that knowledge to the presented clinical case.[Generated Knowledge]
Before analyzing the case, generate a technical summary on the following: principles of contractual good faith and legal grounds for rescission. Then apply that knowledge to the concrete case.Least-to-Most
Stratégie pédagogique et de résolution de problème qui demande d'expliquer le concept du niveau le plus simple au plus avancé, ou de résoudre d'abord les sous-problèmes simples avant d'aborder le problème complexe.
[Least-to-Most]
First explain, in simple language, what heart failure is. Then: 1. Explain the pathophysiological mechanisms. 2. Differentiate HF with preserved versus reduced ejection fraction. 3. Relate that distinction to therapeutic choice.[Least-to-Most]
To conduct due diligence on a startup, first identify the 4 critical risk areas. Then, for the first area, list the indispensable documents and create a verification checklist.Directional Stimulus
Fournit des indices ou des signaux directionnels spécifiques pour orienter le raisonnement du modèle vers une priorité souhaitée (par exemple, la sécurité).
[Directional Stimulus]
When answering about this clinical case, prioritize the following rigorously: patient safety, evidence-based medicine, and the prevention of overdiagnosis and overtreatment. [Describe the clinical case here].
[Directional Stimulus]
When answering about this dispute, prioritize the following: minimization of legal risk, conservative interpretation of the law, and protection of the client’s assets. [Describe the case.]Program-Aided Language
Demande à l'IA d'utiliser une logique de programmation ou du pseudo-code pour structurer des raisonnements logiques ou mathématiques avec davantage de précision.
[Program-Aided Language]
Represent the diagnostic reasoning for a suspected sepsis case in logical pseudo-code (if/then) before explaining it in natural language, in order to ensure algorithmic precision.[Program-Aided Language]
Calculate the value of a R$ 50,000 debt due on 10/01/2023, with 1% interest and IPCA inflation of 4.5%. Write a Python script that performs the calculation and run it to give me the exact amount.ReAct (Reasoning + Acting)
Alterne pensée (raisonnement) et action (recherche d'information ou usage d'un outil) dans une boucle continue pour résoudre des problèmes dynamiques.
[ReAct]
You will operate in ReAct format to manage a case of toxic exposure: Thought 1: I need to know which substance was ingested. Action 1: Ask the user. Thought 2: Based on the response, I should check the antidote. Action 2: Provide the dose. Continue the cycle until stabilization.[ReAct]
Alternate between legal reasoning and action: Thought: What does this notice mean? Action: Which document should be reviewed? Thought: What are the implications? Action: What response is recommended? Continue until a final strategy is reached.Contacts


IA e Medicina