Introduzione
Benvenuti!
Pubblicare oggi un libro cartaceo sull'intelligenza artificiale è quasi come cercare di fermare il tempo. Per questo ho scelto il formato digitale: consente aggiornamenti quasi rapidi quanto le novità e le scoperte del settore.
L'obiettivo di questo materiale non è essere esaustivo, ma offrire una guida pratica di riferimento da cui poter estrarre un'idea specifica, copiare un prompt e adattarlo al proprio contesto.
Per qualsiasi dubbio, sentitevi liberi di contattarmi. Nella sezione «Contatti», alla fine di questo e-book, troverete diversi canali disponibili.
Questo e-book è stato ottimizzato per schermi grandi come PC e tablet, ma resta utilizzabile anche su schermi più piccoli.
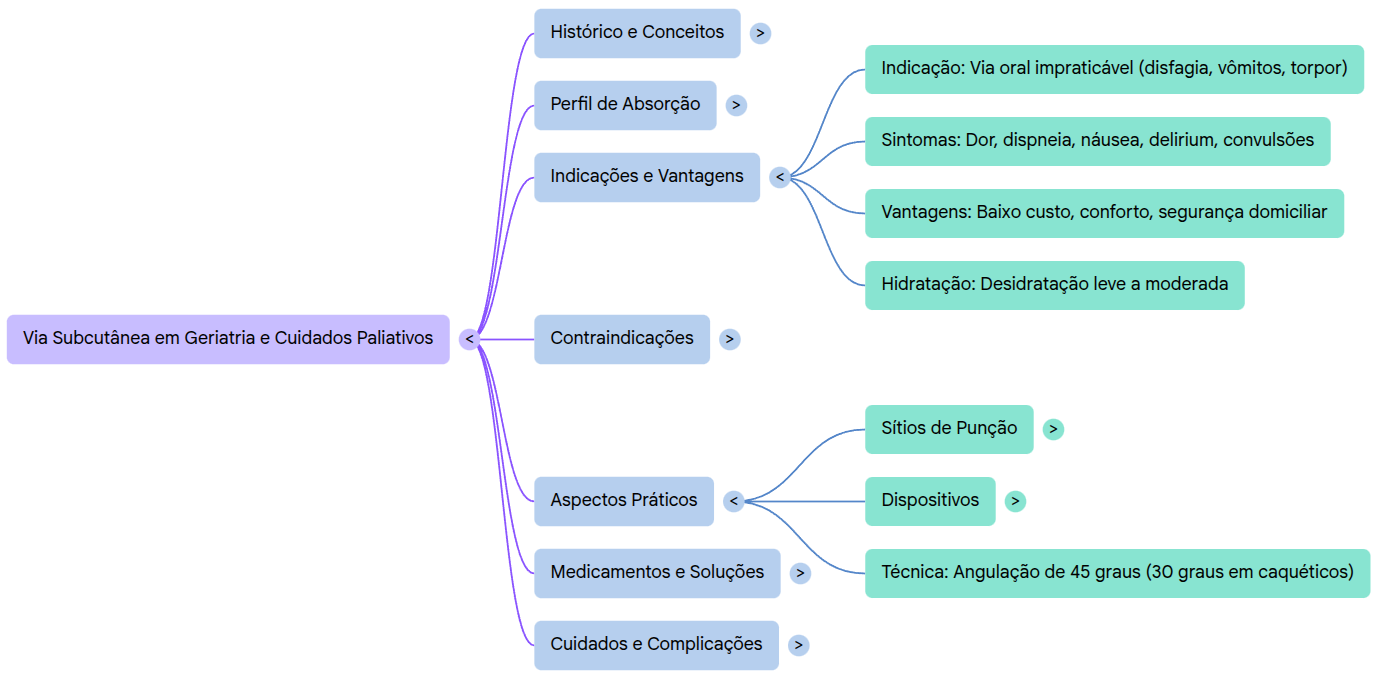
Basic mechanics das ferramentas de IA
Mantenendo le definizioni teoriche al minimo necessario: capire come funzionano gli strumenti di IA è essenziale per ottenerne i risultati migliori. È l’unica ragione per cui vale la pena comprenderne le basi, e non sarà particolarmente complicato. Come probabilmente hai già sentito, ChatGPT e strumenti simili funzionano, in larga misura, come grandi predittori di testo. Siamo già abbastanza abituati a questa logica in molte app quotidiane. Sul telefono, per esempio, quando rispondiamo a un’e-mail, iniziamo appena a scrivere e compare già un suggerimento per il testo successivo (Figura 01).
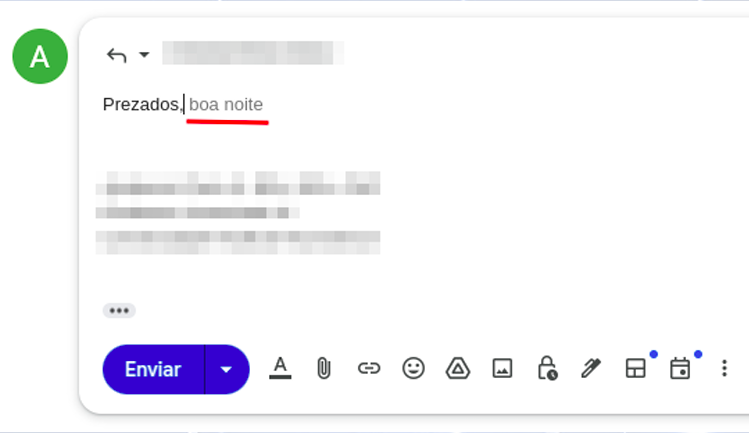
Questo completamento automatico esiste per una questione di contesto e di probabilità delle parole in sequenza. Se ti chiedo di completare la frase “il cielo è [___]”, quale parola ti viene in mente? È molto più probabile che tu pensi a “azzurro” o “grande” che a “cremisi”. Tutte queste frasi sono tecnicamente corrette, ma non vengono usate con la stessa frequenza nella vita quotidiana.
Come applichiamo tutto questo agli strumenti di IA? Sono stati addestrati analizzando miliardi di testi e materiali, e quindi possiedono informazioni sulla probabilità che certe parole compaiano in sequenza. Naturalmente il meccanismo reale è molto più complesso, ma questa analogia è già sufficiente per usare l’IA in modo più efficace.
Nel contesto di questo e-book, “addestramento” indica in modo semplice il processo di presentazione di fonti di materiale, come testi in lingue diverse, ai sistemi di IA affinché riconoscano schemi e, da lì, decidano quale parola o frammento di testo debba arrivare dopo.
Modelli di IA
Quando apri strumenti di IA come Gemini o ChatGPT, spesso ti imbatti nella possibilità di scegliere tra modelli diversi. Puoi considerarli come diverse “versioni” dell’IA, un po’ come esistono biciclette con assetti diversi o differenti allestimenti di un’auto. Non esistono modelli assolutamente “giusti” o “sbagliati”: esistono modelli più adatti a determinati compiti, con capacità, prezzi e limiti d’uso differenti.
Qui entrano in gioco due categorie importanti: i cosiddetti modelli di ragionamento e i modelli più standard. In teoria, i primi sono più adatti a compiti complessi che richiedono di considerare molti fattori insieme. Sono più potenti dal punto di vista dell’elaborazione, ma anche più lenti nel produrre risposte.
Nella pratica, però, non conviene fissarsi troppo su questo punto. Nel 2026 molti modelli funzionano già come modelli di ragionamento, oppure la piattaforma non ti chiede nemmeno di sceglierli esplicitamente. L’approccio più utile è testare i prodotti e i modelli disponibili e osservare quali diano i risultati migliori per ciascun compito.
Strumenti principali
Una domanda che ricevo spesso è: “qual è lo strumento migliore?”. La risposta più onesta è sempre: “dipende”. È meglio un martello, un cacciavite o una pinza? Dipende da ciò che devi fare.
Con gli assistenti di IA la logica è simile. GPT, Gemini e Claude sono i più noti. GPT offre oggi la migliore esperienza di Deep Research. Gemini si distingue per l’integrazione con l’ecosistema Google ed è migliorato molto dal lancio. Claude, a sua volta, è particolarmente forte nella scrittura e nei compiti legati alla programmazione.
Se stai pensando di pagare per un assistente di IA, segui questi passaggi:
- Prova le versioni gratuite dei servizi che stai valutando per almeno uno o due mesi.
- Non sottoscrivere i cosiddetti “aggregatori di IA”, cioè siti che vendono accesso a più modelli a prezzi promozionali. Con molta probabilità non soddisferanno bene le tue esigenze e, con piani accessibili di Gemini e ChatGPT già disponibili, gli intermediari raramente valgono la pena.
- Puoi usare gratuitamente i modelli di Google su https://ai.dev.
Di seguito trovi una selezione delle principali piattaforme di IA oggi disponibili, gratuite o a pagamento.
Usare gli strumenti: la domanda, l’input o il prompt
Partiamo dal prompt. È un concetto fondamentale: prompt è il nome che diamo alle istruzioni che passiamo agli strumenti di intelligenza artificiale.
Aspetti fondamentali del prompt
Cerchiamo di capire il prompt nel modo più diretto possibile: immagina di fare uno spuntino e che un amico ti dica “passami la manica”. Se stai mangiando frutta, quella parola può sembrare una cosa; se stai cucendo, significa tutt’altro. Quando il contesto cambia, la stessa parola cambia significato. Con l’IA accade qualcosa di molto simile: senza contesto, il modello può seguire l’interpretazione sbagliata.
Il contesto conta. Nel prompting conta ancora di più.I prompt efficaci sono prompt specifici.
I prompt più efficaci sono specifici e forniscono contesto.
Questo porta a un’altra idea importante: è più utile ragionare in termini di prompt efficienti o inefficienti che di prompt giusti o sbagliati. Ciò che rende un prompt più efficiente è la nostra capacità pratica di adattare ciò che scriviamo al compito che vogliamo davvero svolgere. In fondo, il prompting è una forma di comunicazione intenzionale.
Esempi di prompt:
1) Prompt diretto
"Translate the song lyrics below into Brazilian Portuguese" => this is a direct prompt: valid, simple, and sometimes very useful, depending on what you need.
Command: translate, transcribe, analyze, revise, produce, organize (...)
Object: the song lyrics, the text, the document, the PDF, the file, the image (...)
Output parameter: into Portuguese, for a conference, for a presentation (...)
2) Prompt con contesto
Here we add context to the prompt (“it will be submitted as a conference abstract (...)”). Why does that matter? Because preparing a text for a professional congress is very different from writing something for social media, for example.
"The text below will be submitted as an abstract for a conference paper in [psychology/engineering/law/medicine]. Review its grammar, coherence and cohesion, suggesting changes whenever needed."3) Prompt per la vita quotidiana
Here is another example: AI can also help with everyday matters. A friend of mine uses it for cooking, from recipes to choosing the best fruit at the market. Explore that versatility with the prompt below. And if you still do not know what an RCD is, adapt the prompt and learn the basics first. Just do not expect to know more than the electrician: AI still makes mistakes. The goal is to gain enough orientation to hold an informed conversation.
"An electrician came to my home and said I need to install a residual-current device (RCD). Explain what it is and what its function is."4) Prompt con persona
In this prompt, besides command, object, output parameter and context, we also define a persona for the AI. This is an especially useful prompt pattern for learning workflows, and for good reason it is one of the most widely used formats.
"You will act as an expert radiology instructor. I have 20 days to learn the fundamentals of ultrasonography and you will be my teacher: build a detailed learning schedule for those 20 days, covering the key ultrasound concepts that an excellent introductory module should include."5) Prompt composito
Below we combine several of the prompt strategies listed above.
"You will act as an English teacher specialized in teaching English as a foreign language. I have 20 minutes per day and you will be my instructor: build a detailed learning plan with basic, intermediate and advanced English content so that a foreign learner can communicate adequately.
We can begin immediately, and your first task is to assess my current English level. Ask the necessary questions to evaluate my skills."Notice that in the example above the prompt structure instructs the AI model to begin by asking questions to assess our English level. This technique is often called reverse prompting and can be extremely useful for evaluating knowledge, performance, or even for making us reflect before the answer is produced. Here is another example:
You are a senior career coach with 20 years of experience in professional transitions, specialized in helping professionals in IT, engineering and creative fields change careers with clarity and confidence. Your style is empathetic, direct and evidence-based, inspired by methods such as Ikigai and GROW.
**Context**: The user is considering a professional transition, such as changing jobs, sectors or even starting a business, but needs to reflect deeply in order to avoid regret. We are in an iterative conversation to map the best path.
**Objective**: Help the user reflect on their current moment, identify real motivations, strengths and obstacles, and build a personalized transition plan in clear, actionable steps.
**Tasks (reverse prompting)**: DO NOT give advice or plans yet. Instead, ask 5 to 7 essential open-ended questions to collect key information. Group them into categories (for example: "Current situation", "Motivations and values", "Skills and network"). After the user responds, use the answers to produce an initial reflection report and draft plan.
**Initial questions to ask NOW**:
1. What is your current profession, how long have you worked in it, and what do you most like and dislike about it?
2. Why do you want to make a transition now? Describe the emotional or practical triggers.
3. What are your core skills (technical and soft skills) and which achievements are you most proud of?
4. What would success in the new career look like for you (for example: salary, flexibility, impact)?
5. What real obstacles do you anticipate (finances, family, market conditions)?
6. Describe your professional network and who might help you in this transition.
7. On a scale from 1 to 10, how ready do you feel to change within the next 6 to 12 months?
Analyze the answers and confirm understanding before proceeding.
Finestra di contesto
You may already have noticed that in very long conversations the AI sometimes becomes confused and starts returning relatively random material, as if it had forgotten what was said at the beginning of the exchange. That happens because of the context window. The easiest way to understand it is to imagine it as the AI’s short-term memory. In practice, it is the maximum amount of information (text, files, images) that the model can process at the same time in a single interaction. This window is measured in thousands or millions of tokens. Roughly speaking, tokens are the basic processing units used by AI systems. During prompt processing, words are split into smaller parts (tokenization), so a long word may correspond to multiple tokens while a short word may correspond to one, depending on the language. For practical purposes, although technically imprecise, you can think of words as a rough proxy for tokens.
When that window becomes “full,” the AI has more trouble retrieving earlier information, which can cause it to forget important instructions, especially the ones that were placed in the middle of the conversation. In general, models tend to handle the beginning and the end of a conversation better than the middle, which means key instructions can be lost if they are buried halfway through a long exchange.
Context-window sizes vary considerably from one AI tool to another. Gemini, for example, offers one of the largest currently available windows, reaching 1 million tokens. Claude recently released Opus 4.6 with the same capacity, while ChatGPT 5.2 works with a 400,000-token context window.
Practical tip: To reduce hallucinations in long projects with conventional AIs (such as GPT and Claude), do not keep the same chat open forever. When the topic changes or the conversation becomes too long, ask for a summary and start a new chat. That effectively resets the context window and keeps the model sharper.
Use the prompt below to generate that migration summary:
[CONTEXT]
We are in a long interaction about [INSERT THE TOPIC, e.g., drafting a protocol].
To avoid losing important details and to clear the context window before a new chat, I need you to condense everything we have done so far.
[TASK]
Generate a detailed "Current State Summary" containing:
1. The main objective we are pursuing.
2. All decisions already made and validated (what is already done).
3. The exact current status of where we stopped.
4. The immediate next steps that were pending.
5. Any stylistic preferences or constraints I already taught you in this conversation.
[FORMAT]
The output must be a structured text, ready to be copied and pasted as the FIRST prompt of a new chat, so that the new AI instance can continue the work exactly where we stopped, without losing context.
Anatomia del prompt "perfetto"
Dalla sezione precedente sappiamo che alcuni prompt sono più adatti di altri a una certa attività. Da qui nasce una domanda frequente: esiste un prompt «perfetto»? La risposta è no, ma esistono componenti che, se organizzati bene, producono risultati eccellenti nella maggior parte dei casi.
Elementi di un prompt ben costruito
1) Persona
2) Obiettivo
3) Contesto
4) Compito
5) Constraints
6) Output format
Non tutti i componenti sono sempre obbligatori. Per un compito semplice potresti non aver bisogno di persona, contesto o restrizioni esplicite.
Esempio 1
Persona:
You will act as a human-resources manager.
Objective:
Create objective criteria for evaluating administrative performance.
Context:
An administrative team composed of assistants and analysts.
Task:
1. Define measurable criteria.
2. Propose an evaluation scale.
3. Suggest an assessment frequency.
Response format:
A table with criteria, description and scoring scale.
Esempio 2
Persona:
You will act as a corporate-communications consultant.
Objective:
Draft an internal communication about the implementation of a new administrative system.
Context:
Employees with different levels of familiarity with technology.
Task:
1. Explain the reason for the change.
2. Highlight operational benefits.
3. Inform the next steps.
Constraints:
Use simple, accessible language.
Avoid jargon and unnecessary technical terms.
Response format:
An institutional announcement in continuous prose.Esempio 3
Persona:
You will act as the internal compliance lead.
Objective:
Assess administrative risks in a supplier-contracting process.
Context:
Recurring procurement of outsourced services.
Task:
1. Identify operational risks.
2. Identify basic legal risks.
3. Propose simple administrative controls.
Response format:
A table followed by a brief conclusion.In generale, i prompt possono essere più o meno estesi e contenere più o meno elementi. In alcuni contesti prompt semplici e diretti funzionano molto bene; in altri servirà molto più dettaglio.
Basic
You are a text editor. Review the abstract below for grammar, cohesion and coherence. Structure it into paragraphs.Intermediate
You are a scientific editor specialized in medicine with 15 years of experience in international journals.
This abstract will be submitted to JAMA as a structured abstract.
Review the abstract below for:
- Grammar and clarity in scientific English
- IMRAD structure (Introduction, Methods, Results, Discussion)
- A maximum length of 300 words
Expected format: paragraphs with bold subsection headings.Advanced
[SYSTEM]
You are a senior scientific editor specialized in medicine with 15 years of experience in international journals (JAMA, Lancet, NEJM). Your task is to perform a critical editorial review.
[CONTEXT]
This abstract will be submitted to JAMA. Audience: editors, reviewers and international clinical readers. Expected standard: editorial excellence.
[ACTION]
Review and rewrite the abstract below while preserving scientific integrity and maximizing clarity.
[POSITIVE CONSTRAINTS]
- Structure: IMRAD with bold subsection headings
- Length: maximum 300 words
- Style: formal scientific English, active voice whenever possible
- Citations: use bracketed numbers [1], [2], etc.
- Data: preserve all original numbers and values exactly
[NEGATIVE CONSTRAINTS]
- Do not speculate beyond the presented data
- Do not use nonstandard jargon or undefined abbreviations
- Do not alter the scientific conclusions; only clarify expression
[EXPECTED FORMAT EXAMPLE]
**Introduction.** [2-3 sentences on the problem and the knowledge gap]
**Methods.** [Design, population, intervention]
**Results.** [Main findings with values]
**Discussion.** [Clinical meaning, limitations, next steps]
[VALIDATION]
Before answering, confirm:
✓ Does every claim have a supporting source or citation?
✓ Is the length within 300 words?
✓ Is the IMRAD structure preserved?
If any criterion is not met, state which one before delivering the revision.Nível Advanced: Checklist de qualidade
Per valutare se il tuo prompt è «abbastanza buono», usa questa checklist:
"Rispondi sull'efficacia della vitamina D nel COVID-19. DEVI fornire risposte basate solo su evidenze scientifiche. Cita esplicitamente le fonti."
Pur essendo semanticamente identiche, la versione A tende a produrre una conformità maggiore perché il modello legge il vincolo per primo e lo tratta come politica prioritaria del compito.
Recency e primacy
I modelli linguistici tendono a dare più peso alle informazioni all'inizio e alla fine del prompt:
- Le istruzioni all'inizio influenzano maggiormente la "politica generale" della risposta. Se definisci lì tono, persona o vincoli fondamentali, il modello tende a trattarli come principi guida (effetto di primazia).
- Le istruzioni alla fine influenzano di più l'azione immediata. Se l'ultima indicazione è "rispondi in 100 parole", quella regola avrà priorità nell'output corrente, anche se prima erano presenti indicazioni diverse (effetto di recenza).
Questo porta a un problema pratico: le istruzioni sepolte nel mezzo di un prompt lungo sono spesso le più facili da perdere. Di solito sono quelle con il tasso di conformità più basso.
Esempio:
I vincoli sulle fonti (solo PubMed, ultimi 5 anni) vengono rispettati meno quando sono collocati nel mezzo del prompt rispetto a quando compaiono subito dopo la persona. Un aggiustamento minimo può fare molta differenza.
Esempio:
Inizio: "DEVI citare solo fonti primarie."
Fine: "Prima di concludere, conferma che TUTTE le affermazioni hanno una citazione da una fonte primaria."
ℹ️
Promemoria: un'altra anatomia di un prompt robusto
(1) Persona — all'inizio, definisce "chi sei"
(2) Vincoli fondamentali — subito dopo la persona
(3) Contesto/Problema — nel mezzo
(4) Formato atteso — verso la fine
(5) Azione specifica — alla fine, come attivazione finale
(6) Riassunto/ripetizione di ciò che è critico
Suddivisione del prompt in blocchi
In alcune situazioni avrai bisogno di un prompt inevitabilmente lungo. Uno dei modi migliori per preservarne l'efficacia è suddividerlo in blocchi o fasi e usare strutture esplicite, come markup o JSON.
Invece di un prompt di 2000 parole con istruzioni sparse, crea:
BLOCCO 1: [Persona + vincoli fondamentali]
BLOCCO 2: [Contesto + problema]
BLOCCO 3: [Azione + formato atteso + validazione]
Il tocco finale
Esistono tecniche più avanzate per verificare l'output (che vedrai in una sezione successiva dell'e-book), ma puoi già aggiungere alla fine di un prompt fattuale un comando semplice: "Controlla l'output prima di trascriverlo e, se trovi incongruenze rispetto all'input richiesto, riavvia il processo. Prosegui finché non rimangono incoerenze o discrepanze."
Esempio: "[Inserisci qui il tuo system prompt] Per confermare che hai letto queste istruzioni, inizia la risposta con: 'Ho capito che devo [breve sintesi dell'istruzione critica].' Poi prosegui con la risposta."
📐 Ordine consigliato per prompt professionali
Inizio (primazia): Persona + vincoli fondamentali/assoluti
Contesto: Contesto, scopo, pubblico
Azione: Cosa fare (comando specifico)
Dettagli: Formato, esempi, vincoli negativi
Fine (recenza): Validazione e istruzione finale (nei prompt lunghi può essere utile un breve riepilogo della richiesta)
GPT: personalizzazione generale, Progetti e GPT
È possibile personalizzare GPT in base all'uso quotidiano e renderlo ancora più adatto alle nostre esigenze. Apri le impostazioni di ChatGPT e vai alla sezione "personalizzazione":
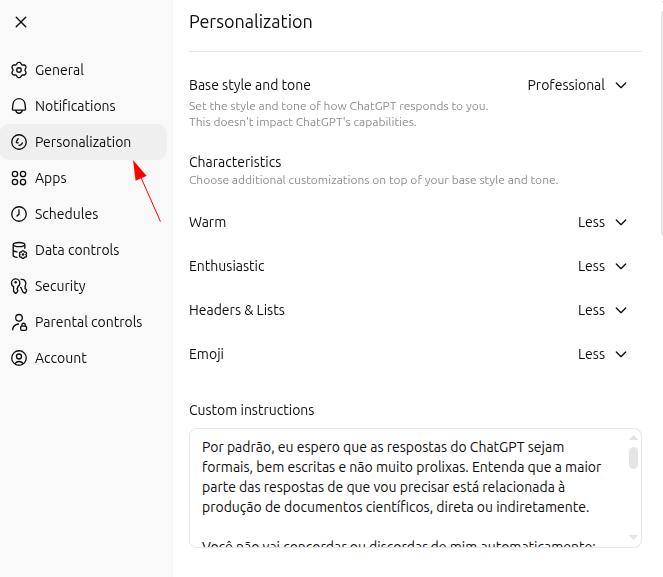
Prompt "maestro" generale
Per impostazione predefinita, mi aspetto risposte formali, concise e ben strutturate. La maggior parte delle mie richieste è collegata, direttamente o indirettamente, alla produzione di documenti scientifici.
Non essere automaticamente d'accordo o in disaccordo con me. Analizza i miei prompt e rispondi nel modo più oggettivo possibile.
Per assicurare che queste linee guida vengano davvero rispettate, inizierò sempre le mie interazioni con "let's work" o "vamos trabalhar" e mi aspetto di essere chiamato ["[IL TUO NOME]"]. In queste situazioni, le risposte devono rimanere assolutamente neutrali: non cercare conferma né disaccordo rispetto ai miei dubbi, pensieri o opinioni. Analizza criticamente il testo fornito e presenta la risposta più adeguata, evitando con rigore errori, imprecisioni e allucinazioni.Progetti: spazi di lavoro personalizzati
La stessa OpenAI definisce i Progetti come "spazi di lavoro" specializzati. Immagina di avere ruoli diversi nella stessa azienda o in aziende differenti: puoi configurare un Progetto per ciascun contesto, con istruzioni e file personalizzati per quell'ambiente.
Ogni progetto consente di associare un prompt maestro a quella specifica attività, oltre a file di riferimento. La combinazione di un prompt preciso e documenti pertinenti trasforma i progetti in assistenti davvero personalizzati e molto utili. Per orientarti: Gemini li chiama "Gems"; Claude li chiama "Projects". La maggior parte delle IA importanti offre ormai una forma simile di personalizzazione.
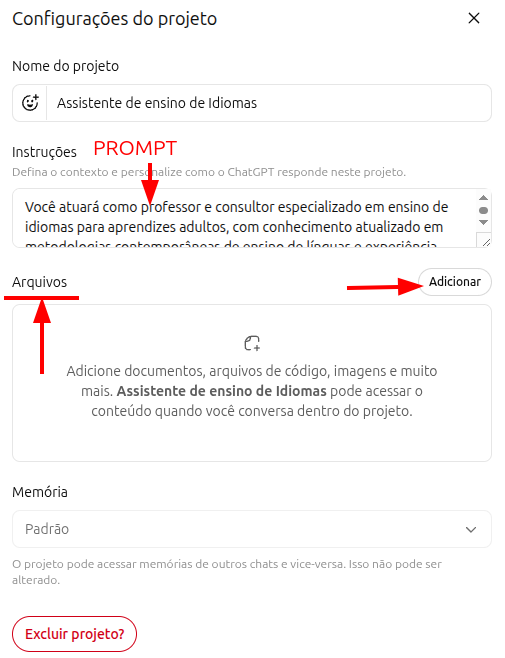
Esempio di prompt per un Progetto di insegnamento delle lingue
Agirai come insegnante e consulente specializzato nell'insegnamento delle lingue agli adulti, fondato su metodologie contemporanee come Task-Based Learning, Communicative Language Teaching e approcci affini.
Userai andragogia e neuroeducazione per costruire programmi in qualsiasi lingua, dando priorità alla competenza comunicativa e alla fluenza funzionale prima della precisione grammaticale.
Le attività includono:
- Progettare programmi strutturati con architettura modulare, adattati al livello CEFR dello studente (A1-C2) e ai suoi obiettivi specifici
- Condurre conversazione pratica con immersione progressiva
- Creare esercizi basati su spaced repetition, interleaving e retrieval practice
- Fornire feedback immediato, specifico e orientato all'azione
- Condurre valutazione formativa continua con adattamento dinamico della difficoltàDifferenza tra Progetti e GPT
Quello che oggi viene chiamato "GPT" dentro ChatGPT un tempo si chiamava "plugin" ed era piuttosto diverso dai Progetti. Con l'evoluzione di entrambe le soluzioni, sono diventati sempre più simili. In pratica: puoi considerare i GPT come ambienti di lavoro personalizzati pensati per essere condivisi con altre persone, mentre i Progetti sono costruiti soprattutto per un uso individuale, anche se possono comunque essere condivisi.
Attenzione: Attenzione: molte persone hanno iniziato a chiamare i GPT "agenti" per venderli a prezzi molto elevati. Prima di acquistare, comprendi bene lo strumento: puoi automatizzare processi usando i GPT, ma tecnicamente non sono agenti. Se qualcuno ti sta facendo pagare molto per un GPT, forse vale la pena chiedersi se non potresti costruirne uno tuo.
Deep Research
La ricerca standard, tramite Google o tramite un'IA generalista, è come chiedere a un bibliotecario informazioni su un tema e ricevere l'ultimo libro che ha letto. Ottieni un'informazione rapida, ma limitata. La modalità Deep Research, invece, è come assumere un ricercatore professionista: (1) crea un piano di ricerca, (2) legge decine di articoli e fonti, (3) confronta informazioni contraddittorie, (4) torna alle fonti primarie per sciogliere i dubbi e (5) redige un report consolidato. Richiede più tempo, da pochi minuti a circa mezz'ora, ma produce una profondità incomparabilmente maggiore.
Deep Research è utile agli estremi della conoscenza: quando "non sai nulla" e hai bisogno di costruire un minimo repertorio prima di parlare con uno specialista, e quando "sai già molto" ma desideri aggiornarti rapidamente sulle novità più recenti della letteratura. Specifica chiaramente quali fonti deve privilegiare: articoli full text su PubMed, giurisprudenza di un certo tribunale, linee guida del Ministero della Salute e così via.
Condurrai una ricerca approfondita sulla salute mentale e sull'uso degli LLM (large language models).
Fornisci esempi o casi, rischi, prevalenza globale e brasiliana dei disturbi mentali più frequenti, e discuti in che modo l'uso degli LLM possa oppure no rappresentare una minaccia per la popolazione generale.
Fornisci inoltre una panoramica della copertura giornalistica sul tema e spiega come le grandi aziende tecnologiche stanno affrontando l'argomento.
In aggiunta, cerca e analizza gli articoli scientifici pertinenti (criteri EBM con livello di evidenza A/B, solo articoli con testo completo disponibile su PubMed/Medline) e riassumi i loro risultati principali.Confronto: Deep Research vs. Deep Search
| IA / Strumento | Nomenclatura | Differenza principale |
|---|---|---|
| ChatGPT (OpenAI) | Deep Research | Il riferimento attuale. Produce report lunghi e strutturati ed è eccellente nel scomporre problemi complessi. |
| Gemini (Google) | Deep Research / Grounding | La seconda migliore opzione tra gli strumenti più noti. |
| Perplexity | Pro Search (Deep Search) | Focalizzato su fact-checking e notizie recenti. |
| Claude (Anthropic) | Projects / Analysis | Non si concentra sul cercare nativamente nel web, ma sull'analizzare in profondità librerie di documenti che gli fornisci. |
| Kimi (Moonshot) | Kimi Research | Buon prodotto, ma limitato a 1 Deep Research al giorno nella versione gratuita. |
| Grok (xAI) | Deep Search (Real-time) | Probabilmente la scelta migliore per notizie recentissime (breaking news). |
Sintesi pratica: Ti serve un dossier tecnico? Scegli ChatGPT o Gemini. Ti serve fact-checking e notizie? Scegli Perplexity o Grok. Devi analizzare 50 PDF che possiedi già? Scegli Claude o NotebookLM (che vedremo tra poco).
Canvas ("lavagna")
La modalità Canvas ti permette di modificare e rivedere contenuti mentre sono ancora in costruzione. Facciamo un esempio pratico: devi rivedere un documento che hai creato tu, come un verbale, un articolo o un capitolo di libro, e invece di chiedere semplicemente all'IA di editarlo per te, puoi aprire quel documento nel Canvas e lavorarci insieme al modello, modificando direttamente ciò che ritieni necessario e chiedendo all'IA interventi puntuali, come riassumere un paragrafo o espandere una sezione.
Canvas può essere uno strumento potentissimo per modificare codice, pagine (HTML) e documenti. Io preferisco modificare personalmente i miei testi, quindi condivido qui sotto il prompt che uso, così potrai copiarlo e adattarlo al tuo contesto.
Rivedrai il testo allegato per individuare possibili errori grammaticali e di digitazione. Valutalo in termini di coerenza e coesione, ma senza modificarlo direttamente: applicherai il formato barrato alle parti che suggerisci di rimuovere e, accanto, inserirai i tuoi suggerimenti in grassetto, in modo che io possa identificare le parti da correggere e valutarle direttamente.
Praticamente tutti gli strumenti di IA oggi possiedono una modalità simile a Canvas: in GPT e Gemini ha persino lo stesso nome, mentre in altre IA compare con nomi diversi, come Artifacts in Claude. Il modo migliore per capire e imparare davvero a usarla è praticare.
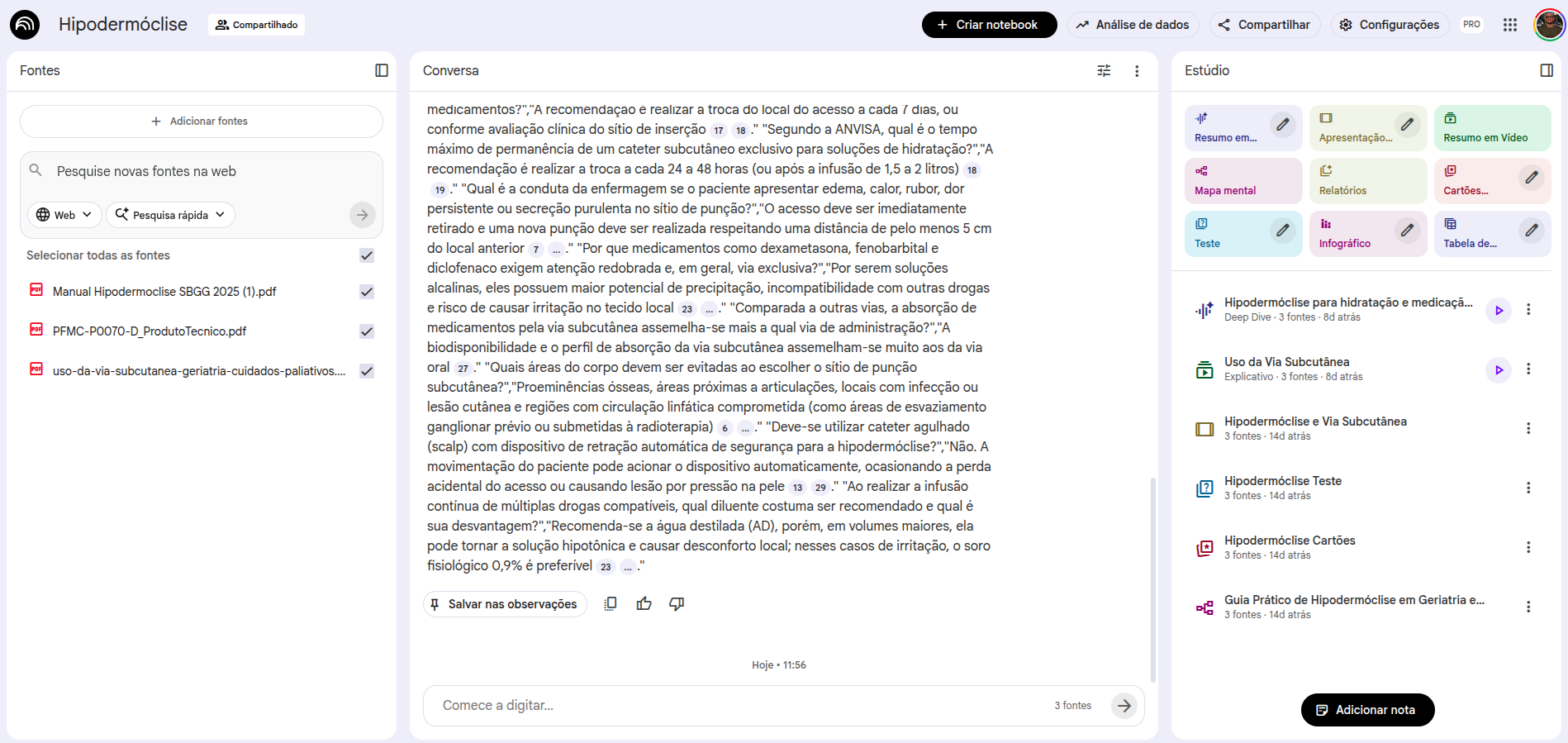
NotebookLM
NotebookLM è il mio strumento di IA preferito e ti spiego perché. Qualche tempo fa è diventato famoso per la possibilità di generare "riassunti audio". È una funzione eccellente, ma non è il motivo principale per cui lo uso così tanto.
Torniamo al problema delle allucinazioni: con un prompt ben costruito e con il grounding alle fonti, possiamo ridurre al minimo il tasso di allucinazione. È esattamente ciò che fa NotebookLM: consulta e risponde soltanto a partire dalle fonti che scegli di usare.
Quando crei un notebook, la prima schermata riguarda la scelta delle fonti. Puoi aggiungere documenti, file di Drive, Google Docs (inclusi fogli di calcolo), video di YouTube, URL di siti web e file audio. Tutto questo diventa la tua base di fonti e tutte le risposte estratte dai prompt arriveranno esclusivamente da quelle fonti. Se hai già sentito parlare di RAG (retrieval augmented generation), NotebookLM fa più o meno questo, riducendo al minimo possibile errori e allucinazioni.
Come aggiungere fonti in NotebookLM
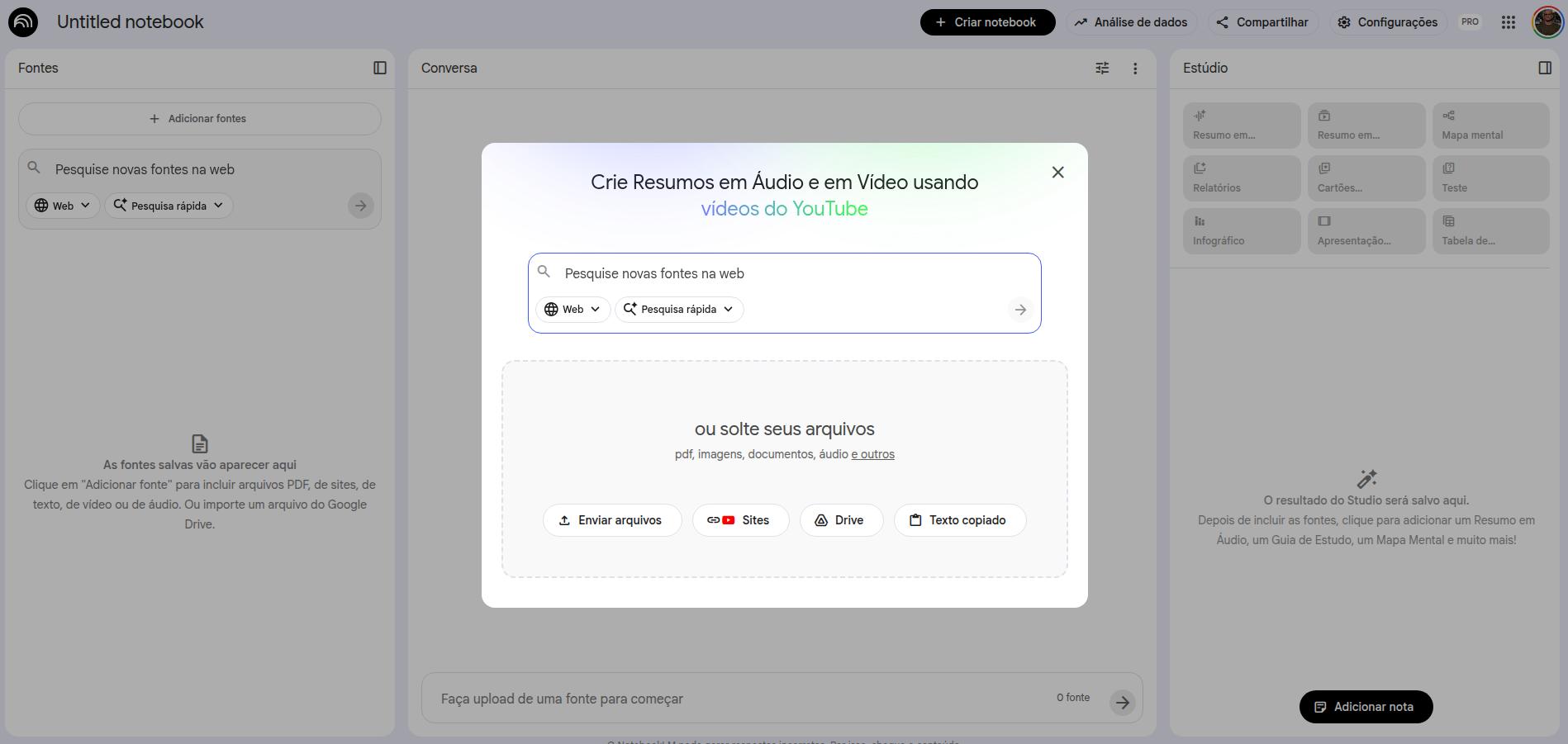
Una volta aggiunte le fonti, l'interfaccia si organizza così: a sinistra le fonti inserite (che puoi rimuovere o ampliare), al centro l'interfaccia dei prompt, a destra le risorse di interazione fornite da NotebookLM.
Risorse disponibili in NotebookLM
Il pannello delle risorse include:
- Riassunto audio (podcast con due presentatori che discutono le tue fonti)
- Guida allo studio (con domande a scelta multipla, a risposta breve e aperta)
- FAQ (domande frequenti sul contenuto)
- Sommario e linea del tempo
- Documento di briefing (riassunto esecutivo)
- Mappa mentale
- Infografiche
- Flashcard e quiz
Quasi tutte le risorse mostrano un'icona a forma di "matita", il che significa che puoi modificare le istruzioni predefinite di quella risorsa inserendo un prompt personalizzato.
Modifica delle risorse — esempio per l'audio
Produrrai un audio quanto più dettagliato ed esteso possibile, affrontando i dettagli metodologici con rigore e precisione: descrivi in dettaglio come è stata strutturata l'architettura del prodotto sviluppato, i dettagli del prompt di dibattito (se si trattava di una strategia agentic con più personas o se sono stati effettivamente usati agenti differenti). Infine, soffermati sui risultati, descrivendoli accuratamente e spiegandone gli impatti sulla salute.Finestra di contesto estesa
NotebookLM offre una finestra di contesto da 1 milione di token, permettendo l'interazione simultanea con più documenti lunghi: libri interi, articoli scientifici, trascrizioni di riunioni. A differenza di molte IA convenzionali, è stato progettato specificamente per "consultare professionalmente" più file: le fonti restano separate dalla finestra di conversazione, ma sono pienamente accessibili al modello. Questo ti consente di conversare a lungo con i documenti senza che la loro dimensione danneggi la memoria della conversazione.
Ogni risposta è accompagnata dalla citazione precisa del passaggio originale del documento, facilitando la verifica e aumentando drasticamente l'affidabilità per l'uso professionale.
Ecosistema Google: integrazione e aggiornamento dinamico
NotebookLM si integra con l'ecosistema Google, consentendo di usare cartelle e documenti di Google Drive come fonti. Il punto più utile: quando colleghi un Google Docs come fonte, NotebookLM mantiene il collegamento con il file originale, che puoi aggiornare quando vuoi. Se rileva cambiamenti nella versione più recente, mette a disposizione un pulsante per aggiornare quella fonte.
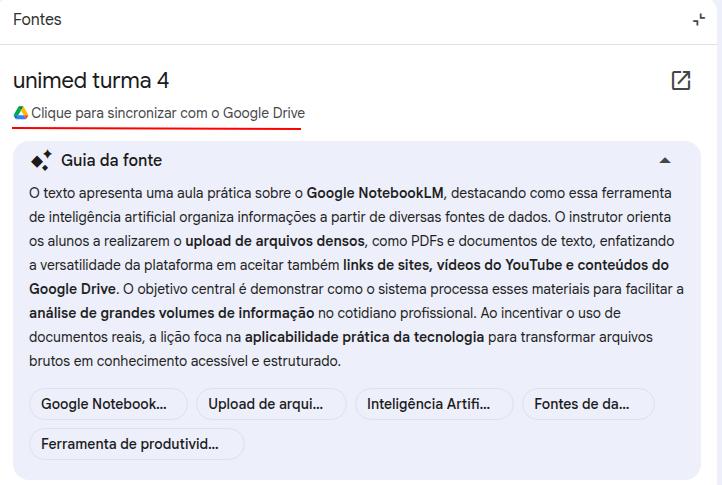
Trascrizione di audio e video
NotebookLM consente di trascrivere integralmente audio e video: basta aggiungerli come fonti e chiedere, via prompt, la trascrizione del materiale. Puoi anche includere istruzioni di enfasi. Immagina, per esempio, di aver registrato una riunione da trasformare in verbale, o una lezione in cui il professore evidenzia spesso informazioni importanti. Esempi:
Trascrivi integralmente il materiale della fonte, identificando, quando possibile, i diversi interlocutori.
Successivamente, redigi un verbale formale della riunione con i seguenti elementi: data, partecipanti identificati, ordine del giorno discusso, decisioni prese e azioni successive con i rispettivi responsabili.NotebookLM gratuito vs. plus
Esistono differenze tra la versione gratuita e quella a pagamento, che riguardano il numero di notebook che puoi creare, il numero di fonti per notebook, la quantità di risorse generabili al giorno e, soggettivamente, la velocità con cui alcuni output vengono prodotti. Il mio suggerimento pratico: inizia con la versione gratuita e passa a quella a pagamento solo dopo esserti davvero familiarizzato con lo strumento, se necessario.
- Oltre 500 notebook (contro i 100 della versione gratuita)
- Generazione illimitata di riassunti audio al giorno
- Audio più lunghi e più dettagliati
- Integrazione più profonda con Google Workspace
- Funzioni per condividere notebook con i team
- Supporto prioritario e accesso anticipato a nuove funzionalità
NotebookLM è particolarmente utile nei contesti accademici. Lo uso molto per interagire con testi accademici, come articoli in PDF, e ora anche file EPUB.
- Revisione della letteratura: aggiungi gli articoli selezionati e usa prompt per sintetizzare i risultati principali, confrontare metodologie o individuare lacune di conoscenza.
- Studio delle linee guida: carica le raccomandazioni più recenti di una specialità e poni loro domande cliniche dirette.
- Preparazione di presentazioni: usa la Guida allo studio e le FAQ per generare domande sul contenuto di lezioni o conferenze.
- Diario di apprendimento: mantieni un Google Docs con note quotidiane e collegalo a NotebookLM; a fine settimana genera un riassunto o un quiz su ciò che hai imparato.
- Consiglio pro: usa NotebookLM come tutor personalizzato. Studia un articolo e spiegaglielo, chiedendogli di correggere e integrare i punti critici che hai frainteso o trascurato.
OpenEvidence
Che cos'è OpenEvidence?
OpenEvidence è una piattaforma di supporto alla decisione clinica basata su IA, sviluppata specificamente per medici e professionisti della salute. A differenza dei modelli generalisti come ChatGPT e Gemini, OpenEvidence è stato addestrato e ottimizzato per consultazioni mediche, con accesso a letteratura medica specialistica curata dal suo team editoriale.
La piattaforma ha accordi di contenuto con diverse organizzazioni di riferimento, tra cui NEJM, JAMA, NCCN, Cochrane, Wiley, ACC, ADA e altre società mediche.

Come funziona?
La logica è semplice e molto simile a quella degli altri LLM:
- Poni una domanda clinica in inglese o in portoghese
- Lo strumento cerca nelle proprie basi di letteratura medica
- Restituisce una risposta con citazioni e link alle fonti originali
- Puoi fare domande di follow-up nella stessa sessione per approfondire
Access it at: www.openevidence.com
Migliori pratiche di prompt per OpenEvidence
Come per qualsiasi strumento di IA, la qualità della risposta dipende dalla qualità della domanda. In OpenEvidence, le pratiche seguenti fanno davvero la differenza:
1. Includi il contesto clinico rilevante del paziente
Instead of asking generically, “what is the treatment for hypertension?”, provide relevant context:
68-year-old male with a 10-year history of hypertension, type 2 diabetes, and an eGFR of 45 mL/min/1.73m². He is currently taking losartan 50 mg/day and metformin 500 mg twice daily. Current blood pressure: 155/95 mmHg. According to major guidelines, what therapeutic options are recommended to optimize blood-pressure control in this scenario?2. Specifica il tipo di informazione desiderata
What are the current indications for anticoagulation in non-valvular atrial fibrillation? Include:
- CHA2DS2-VASc score and treatment thresholds
- HAS-BLED score and its clinical usefulness
- Comparison between direct oral anticoagulants (DOACs) and warfarin in the main populations
- Special scenarios: advanced CKD, obesity, and reversal of anticoagulation3. Richiedi livello di evidenza e qualità degli studi
What is the current evidence on the use of ivermectin for treating COVID-19? Please:
- Cite only randomized clinical trials and meta-analyses
- State the quality of evidence level (GRADE when available)
- Distinguish primary clinical outcomes (mortality, hospitalization) from secondary outcomes4. Confronta direttamente opzioni terapeutiche
Compare the efficacy and safety of SGLT2 inhibitors versus GLP-1 receptor agonists in patients with type 2 diabetes and established cardiovascular disease, based on randomized clinical trials with hard cardiovascular outcomes (MACE, cardiovascular mortality, hospitalization for heart failure).5. Usa domande di follow-up per approfondire
OpenEvidence consente domande di follow-up nella stessa sessione. Per esempio, dopo aver ottenuto una risposta sul trattamento iniziale, puoi chiedere:
What if this patient also has heart failure with reduced ejection fraction (HFrEF)? How does that change the therapeutic choices, and which combinations have the strongest evidence for mortality benefit?Cautele fondamentali nell'uso di OpenEvidence
OpenEvidence è uno strumento potente, ma un uso inadeguato può condurre a errori clinici. Tre cautele sono particolarmente importanti:
1. Il prompt orienta la risposta e può introdurre bias
Il modo in cui costruisci il prompt influenza direttamente ciò che lo strumento mostrerà. Se chiedi "quali evidenze sono a favore dell'uso di X?", lo strumento tenderà a presentare evidenze favorevoli, anche quando esistono prove contrarie più rilevanti o di qualità metodologica superiore. Le domande più neutrali generano risposte più equilibrate. Formulare le domande in modo neutro e verificare attivamente se esistono evidenze contrarie è una buona pratica.
2. Lo strumento può confondere outcome primari e secondari
Un errore frequente, sia tra gli utenti sia nello strumento stesso, è trattare outcome surrogati, laboratoristici o radiologici come se equivalessero a outcome clinici duri. Un antibiotico può eradicare un batterio senza migliorare la sopravvivenza, e un farmaco può ridurre l'HbA1c senza ridurre la mortalità cardiovascolare. Chiediti sempre: lo studio citato misura davvero l'outcome che conta per il mio paziente?
3. Sapere che una prova esiste non equivale a saperla interpretare
OpenEvidence può citare un trial randomizzato senza contestualizzare adeguatamente qualità metodologica, dimensione reale dell'effetto, applicabilità al paziente o rischio di bias. Concetti come NNT, intervalli di confidenza, eterogeneità delle meta-analisi e qualità GRADE restano essenziali per interpretare correttamente le prove. Lo strumento supporta la decisione clinica; non la sostituisce.
Cautela aggiuntiva: lo strumento non sostituisce il giudizio clinico individualizzato
Le risposte di OpenEvidence si basano su popolazioni di studio che possono non riflettere le caratteristiche specifiche del tuo paziente, incluse comorbidità, interazioni farmacologiche, valori e preferenze. Non trattare nessuno strumento di IA, nemmeno OpenEvidence, come un oracolo definitivo.

Cautele nell’uso degli strumenti di IA
Sebbene le IA siano strumenti potenti, il loro uso richiede responsabilità e consapevolezza dei limiti, soprattutto in ambiti critici come la salute. Di seguito evidenziamo tre punti di attenzione fondamentali.
1) Allucinazione (Hallucination)
Nel contesto dell'IA, il termine "allucinazione" indica la generazione di informazioni che sembrano corrette e vengono presentate con alta sicurezza, ma che in realtà sono false o inventate. Accade perché il modello predice la parola successiva più probabile, non necessariamente la verità. In ambito sanitario ciò può significare raccomandazioni inventate, dosi errate o riferimenti ad articoli inesistenti. Verifica sempre le fonti.
2) Rischio di bias (Bias)
I modelli di IA vengono addestrati su enormi insiemi di dati presi da internet, che incorporano i bias della società stessa. Questo può produrre risposte che perpetuano stereotipi di genere, razza o classe socioeconomica, oppure introdurre bias nel ragionamento medico, per esempio sottodiagnosticando certe condizioni in gruppi demografici specifici. Mantieniti vigile rispetto a queste distorsioni.
3) Il paradigma della "scatola nera" (Black Box)
Non sappiamo esattamente come o perché un'IA sia arrivata a una certa conclusione. Non conosciamo sempre i materiali usati nell'addestramento né le fonti specifiche che sostengono una determinata risposta. Inoltre, i processi interni delle reti neurali restano complessi e poco trasparenti. Questo è particolarmente critico nella pratica clinica, dove la spiegabilità è centrale per la sicurezza e la fiducia.
Cautela extra: necessità di revisione umana
Non utilizzare mai l'output di un'IA direttamente per una decisione clinica senza una revisione rigorosa. Lo strumento può supportare il processo, ma la responsabilità e il giudizio finale restano sempre umani (human-in-the-loop).
Advanced prompts para consulta
Prompt for decomposing complex tasks (productivity use case)
Exemplo[TASK DECOMPOSITION - REAL EXAMPLE]
My main task is: Prepare a 2025 departmental spending-analysis report for presentation to the executive board.
Please break this down into sequential subtasks, numbered from 1 to N.
For EACH subtask, provide:
- Subtask number and title
- Description of what needs to be done
- Success criterion
- Any prior dependency
- Estimated time
Additional context:
- We have data from three sources: SAP, internal spreadsheets, and department receipts
- The presentation is in 2 weeks
- Audience: 8 non-technical executives
- Expected format: 15-20 slides with the main chartsEsempio modificabile
[TASK DECOMPOSITION]
My main task is: [DESCRIBE THE OVERALL TASK]
Please break it into sequential subtasks, numbered from 1 to N.
For EACH subtask, provide:
- Subtask number and title
- Description of what must be done
- Success criterion (how to know it was done well)
- Any prior dependency
- Estimated time
Then present a recommended execution timeline.Cadeia de Pensamento (Chain of Thought)
Esempio modificabile:
[Chain of Thought - EDITABLE]
You are a [SPECIALIST IN WHAT?].
Analyze: [DESCRIBE THE CASE / PROBLEM]
Think step by step:
1. [WHAT IS THE FIRST LOGICAL STEP?]
2. [WHAT IS THE SECOND STEP?]
3. [WHAT IS THE THIRD STEP?]
Respond by detailing each step of your reasoning.Esempio completo:
[Chain of Thought - FULL]
You are a project manager. Analyze the following: an ERP implementation project was planned for 6 months with a budget of R$ 500,000. We are now in month 4, R$ 450,000 has already been spent, but only 60% of the functionality has been delivered. The client is dissatisfied.
Think step by step:
1. Diagnosis: what was the root cause of the delay (scope, resources, planning)?
2. Impact analysis: how much extra time and cost will be required?
3. Strategy: what options exist (extension, scope reduction, larger team)?
Respond by detailing each stage.Árvore de Pensamento (Tree of Thought)
Esempio modificabile:
[Tree of Thought - EDITÁVEL]
Analise: [DESCREVA UM CENÁRIO COMPLEXO COM MÚLTIPLAS OPÇÕES]
Elabore uma árvore de pensamentos simulando múltiplos cenários:
Cenário 1: [PRIMEIRA OPÇÃO]
- Sub-consequência 1a: [...]
- Sub-consequência 1b: [...]
- Desfecho provável: [...]
Cenário 2: [SEGUNDA OPÇÃO]
- Sub-consequência 2a: [...]
- Sub-consequência 2b: [...]
- Desfecho provável: [...]
Cenário 3: [TERCEIRA OPÇÃO]
- Sub-consequência 3a: [...]
- Sub-consequência 3b: [...]
- Desfecho provável: [...]
Síntese: Qual cenário apresenta maior probabilidade de sucesso?Esempio completo:
[Tree of Thought - COMPLETO]
Uma empresa precisa decidir sobre expansão internacional. Analise os três cenários principais:
Cenário 1: Mercado da Ásia (alto risco, alto retorno)
- Investimento inicial: $10M
- Barreiras regulatórias: altas
- Potencial de mercado: 500M pessoas
- Desfecho provável: Retorno em 4-5 anos se conseguir entrada
Cenário 2: Mercado da América Latina (risco médio, retorno médio)
- Investimento inicial: $5M
- Barreiras regulatórias: médias
- Potencial de mercado: 150M pessoas
- Desfecho provável: Retorno em 2-3 anos
Cenário 3: Mercado Europeu (baixo risco, baixo retorno)
- Investimento inicial: $3M
- Barreiras regulatórias: altas
- Potencial de mercado: 100M pessoas
- Desfecho provável: Retorno estável em 1-2 anos
Síntese: América Latina oferece melhor equilíbrio risco-retorno para expansão no curto prazo.Cadeia de Aprendizagem (Chain of Learning)
Esempio modificabile:
[Chain of Learning - Esempio modificabile]
Agirai come simulatore interattivo per il mio allenamento in [QUALE DOMINIO?].
[Il tuo ruolo]
1. Crea uno scenario o un problema iniziale su [ARGOMENTO SPECIFICO]
2. Non rivelare subito la soluzione
3. Fornisci informazioni neutre man mano che avanzo
4. Adatta la difficoltà in base alla mia performance
5. Rivedi il mio ragionamento e segnala le lacune
[Formato di interazione]
- Io presento la mia analisi o soluzione
- Tu fornisci feedback costruttivo
- Iteriamo finché non raggiungo la padronanza dell'argomento
Sono pronto a iniziare. Qual è il dominio e il tema?Esempio completo:
[Chain of Learning - Esempio completo]
Agirai come simulatore interattivo per il mio allenamento in Epidemiologia Clinica.
[Il tuo ruolo come docente-simulatore]
1. Crea uno scenario realistico di focolaio epidemiologico (per esempio: "Abbiamo rilevato 15 casi di gastroenterite in un asilo in 3 giorni")
2. Non rivelare subito l'eziologia più probabile
3. Fornisci dati man mano che li richiedo (sintomi, incubazione, esposizioni, laboratorio)
4. Aumenta la complessità quando dimostro maggiore comprensione (per esempio: fattori confondenti)
5. Rivedi il mio ragionamento epidemiologico (la mia ipotesi iniziale era adeguata?)
[Il mio approccio]
- Formulerò ipotesi su fonte e modalità di trasmissione
- Chiederò dati specifici per testare tali ipotesi
- Tu offrirai feedback sull'adeguatezza dell'indagine
Sono pronto. Presenta uno scenario di focolaio.Chain of Verification
Tecnica che riduce le allucinazioni chiedendo all'IA di generare domande di verifica e controllare le proprie premesse prima di offrire la risposta finale.
[Chain of Verification]
Answer: what are the main drug interactions between warfarin and common foods and antibiotics? After answering, follow this verification protocol: 1. Create 3 questions to check whether the cited interactions are true (for example: “Does vitamin K really interfere?”). 2. Answer those questions independently. 3. Provide a revised and corrected final answer based on those checks.[Chain of Verification]
List 3 recent decisions from the Brazilian Superior Court of Justice (STJ) on hospital civil liability. Follow the CoVe protocol: 1. Generate questions to confirm case number and year. 2. Answer whether the cases exist and actually concern the topic. 3. Deliver only the confirmed cases.Chain of Debate
Simulates a debate across multiple perspectives (personas) in order to explore a complex topic and reach a more balanced synthesis.
[Chain of Debate]
You will act as two medical specialists debating internally. Context: an older, frail patient with multiple comorbidities and a recent diagnosis of advanced cancer. Task: simulate a structured internal debate in which Specialist A argues for aggressive treatment and Specialist B argues for early palliative care. Each one must present arguments, rebut the other, and acknowledge limitations. Finish with a balanced synthesis.[Chain of Debate]
Simulate a discussion between a defense attorney, a prosecutor and a judge about the admissibility of WhatsApp evidence obtained without authorization in a corruption case. Debate “Fruit of the Poisonous Tree” versus “Public Interest.”Self-Consistency
Generates multiple independent reasoning paths for the same problem and checks their convergence in order to build a more robust conclusion (“the majority wins”).
[Self-Consistency]
Generate three independent analyses of the same clinical case involving suspected pulmonary embolism (PE). Produce three separate diagnostic reasoning paths. Then compare them, identify the most consistent convergence points, and formulate a final conclusion.[Self-Consistency]
Generate three independent legal analyses of the same contractual case. Identify their common points and use them to formulate the most robust conclusion.Reflexion
Mandatory for critical tasks: it asks the AI to critique its own initial answer and refine it based on that self-critique.
[Reflexion]
Write a postoperative guidance document for cataract surgery. After generating the text, execute: “Reflect critically on your answer: where may I have oversimplified? Which assumptions may be wrong? What additional information would change my conclusion?” After that reflection, refine your original answer.[Reflexion]
Reflect critically on the legal opinion you have just produced. Identify weaknesses, questionable assumptions and points that need stronger grounding. Revise the opinion after that analysis.Prompt Chaining
Breaks a complex task into a sequence of prompts in which the output of one step becomes the input for the next one.
[Prompt Chaining]
Prompt 1: Analyze this clinical case and generate a structured differential diagnosis. Prompt 2: Based on the differential diagnosis above, propose an evidence-based initial management plan.[Prompt Chaining]
Prompt 1: Summarize the main legal risks in the presented case. Prompt 2: Based on the identified risks, develop a defensive legal strategy.Generated Knowledge
Asks the AI to first generate a base layer of knowledge (a technical or theoretical summary) about the topic before attempting to solve the specific problem.
[Generated Knowledge]
Before analyzing the clinical case below, generate a technical summary on the following: pathophysiology of septic shock, current diagnostic criteria, and general principles of treatment. Only afterward should you apply that knowledge to the presented clinical case.[Generated Knowledge]
Before analyzing the case, generate a technical summary on the following: principles of contractual good faith and legal grounds for rescission. Then apply that knowledge to the concrete case.Least-to-Most
Strategia educativa e di problem solving che chiede di spiegare il concetto dal livello base a quello avanzato, oppure di risolvere prima sottoproblemi semplici e poi il problema complesso.
[Least-to-Most]
First explain, in simple language, what heart failure is. Then: 1. Explain the pathophysiological mechanisms. 2. Differentiate HF with preserved versus reduced ejection fraction. 3. Relate that distinction to therapeutic choice.[Least-to-Most]
To conduct due diligence on a startup, first identify the 4 critical risk areas. Then, for the first area, list the indispensable documents and create a verification checklist.Directional Stimulus
Fornisce indizi o segnali specifici che guidano il ragionamento del modello verso una priorità desiderata (per esempio dare priorità alla sicurezza).
[Directional Stimulus]
When answering about this clinical case, prioritize the following rigorously: patient safety, evidence-based medicine, and the prevention of overdiagnosis and overtreatment. [Describe the clinical case here].
[Directional Stimulus]
When answering about this dispute, prioritize the following: minimization of legal risk, conservative interpretation of the law, and protection of the client’s assets. [Describe the case.]Program-Aided Language
Chiede all'IA di usare logica di programmazione o pseudo-codice per strutturare ragionamenti logici o matematici con maggiore precisione.
[Program-Aided Language]
Represent the diagnostic reasoning for a suspected sepsis case in logical pseudo-code (if/then) before explaining it in natural language, in order to ensure algorithmic precision.[Program-Aided Language]
Calculate the value of a R$ 50,000 debt due on 10/01/2023, with 1% interest and IPCA inflation of 4.5%. Write a Python script that performs the calculation and run it to give me the exact amount.ReAct (Reasoning + Acting)
Alterna pensiero (ragionamento) e azione (ricerca di informazioni o uso di strumenti) in un ciclo continuo per risolvere problemi dinamici.
[ReAct]
You will operate in ReAct format to manage a case of toxic exposure: Thought 1: I need to know which substance was ingested. Action 1: Ask the user. Thought 2: Based on the response, I should check the antidote. Action 2: Provide the dose. Continue the cycle until stabilization.[ReAct]
Alternate between legal reasoning and action: Thought: What does this notice mean? Action: Which document should be reviewed? Thought: What are the implications? Action: What response is recommended? Continue until a final strategy is reached.Contatti


IA e Medicina