引言
欢迎!
在当前阶段把人工智能写成一本纸质书,几乎等于试图让时间停下来。因此我选择数字形式,这样材料可以以接近该领域变化速度的节奏更新。
这份材料的目标不是穷尽主题,而是作为一份实用参考指南,让你能够提取具体信息、复制一个 prompt,并按照自己的场景进行改写。
如有疑问,欢迎联系我。在本电子书最后的“联系”部分,你会看到多个可用渠道。
这本电子书优先针对大屏设备优化,如电脑和平板,但在较小屏幕上也可以使用。
Basic mechanics das ferramentas de IA
尽量把理论定义压缩到最低限度:理解 AI 工具如何工作,是获得更好结果的前提。这也是为什么值得花一点时间掌握它们的基本原理,而且并不会太复杂。你可能已经听说过,ChatGPT 及类似工具在很大程度上像一个大型文本预测器。我们在日常应用里其实已经接触过类似机制。例如在手机上回复邮件时,往往刚打出开头,系统就会给出下一段文字建议(图 01)。
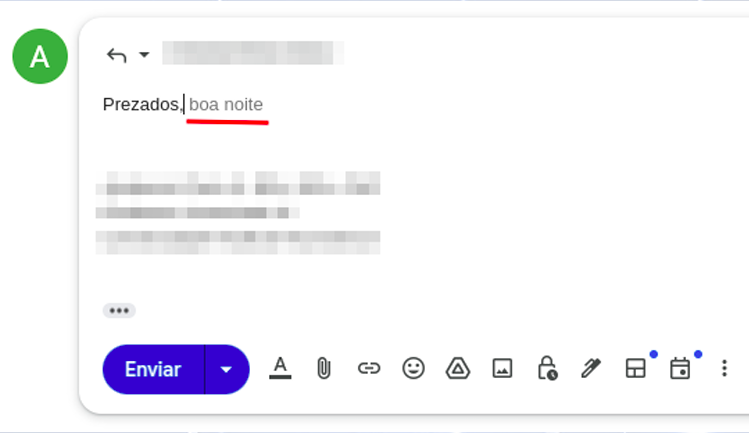
这种自动补全之所以存在,是因为上下文以及词语在序列中出现的概率。如果我让你补全句子“天空是 [___]”,你最先想到什么词?你想到“蓝色”或“辽阔”的概率,显然高于想到“深红”。这些句子在语法上都成立,但它们在日常语言中的出现频率并不相同。
这与 AI 工具有什么关系?这些系统在训练时分析了数十亿级别的文本和材料,因此掌握了词语连续出现的概率信息。真实机制当然远比这个类比复杂,但这已经足以帮助我们更有效地理解和使用这些工具。
在本电子书的语境里,“训练”可以简单理解为:向 AI 系统提供各类来源材料,例如不同语言的文本,让它识别模式,并据此判断下一个最可能出现的词语或文本片段。
AI 模型
当你打开 Gemini、ChatGPT 等 AI 工具时,通常会看到不同模型可供选择。你可以把它们理解为 AI 的不同“版本”,就像自行车有不同配置、汽车有不同车型一样。并不存在绝对“对”或“错”的模型,只有更适合某类任务的模型,它们在能力、价格和使用限制上各不相同。
这里有两类尤其值得注意:所谓的推理型模型,以及更常规的模型。理论上,推理型模型更适合处理复杂任务,因为这类任务往往需要同时权衡多个因素。它们在处理能力上更强,但生成回答时通常也更慢。
在实际使用中,不必过度纠结这一点。到了 2026 年,许多模型本身已经具备推理特征,或者平台根本不会让你明确选择。更实用的做法是直接测试现有产品和模型,观察哪一种在具体任务上表现最好。
主要工具
我最常被问到的问题之一是:“哪个工具最好?”最诚实的回答永远是:“这取决于任务。”锤子、螺丝刀和钳子,哪个更好?答案取决于你要完成什么工作。
AI 助手也是同样的逻辑。GPT、Gemini 和 Claude 是最知名的几类。GPT 目前提供最强的 Deep Research 体验;Gemini 的优势在于它与 Google 生态的整合,而且自发布以来提升明显;Claude 则在写作和编程相关任务上表现尤其突出。
如果你正在考虑为某个 AI 助手付费,建议遵循以下步骤:
- 先连续使用一到两个月的免费版本,再决定是否订阅。
- 不要轻易订阅所谓的“AI 聚合平台”,也就是那些以低价出售多个模型访问权限的网站。它们往往无法真正满足你的需求,而在 Gemini 和 ChatGPT 已有较实惠方案的情况下,中间层通常并不值得。
- 你可以在 https://ai.dev 免费使用 Google 的模型。
下面列出的是目前较为重要的一些 AI 工具,包含免费与付费选项。
使用这些工具:问题、输入或 prompt
先从 prompt 说起。这是一个基础概念:prompt 是我们交给人工智能工具的指令。
prompt 的基本要点
用最直接的方式理解 prompt:假设你正在吃点心,这时朋友对你说“把袖子递给我”。如果你是裁缝,这句话是一种意思;如果你正在吃水果,同一个词又可能让人想到别的东西。上下文一变,含义就变了。AI 也是这样:没有上下文,模型就可能沿着错误的解释去理解你的指令。
上下文很重要。在 prompting 中尤其重要。有效的 prompts 是具体的 prompts。
更有效的 prompts 既具体又提供上下文。
这又引出一个重要概念:与其把 prompt 看成“对”或“错”,不如把它们看成“高效”或“低效”。真正决定 prompt 质量的,是我们能否把写下来的内容准确匹配到要解决的任务上。从这个意义上说,prompting 本质上就是一种有意图的沟通方式。
prompt 示例:
1)直接 prompt
"Translate the song lyrics below into Brazilian Portuguese" => this is a direct prompt: valid, simple, and sometimes very useful, depending on what you need.
Command: translate, transcribe, analyze, revise, produce, organize (...)
Object: the song lyrics, the text, the document, the PDF, the file, the image (...)
Output parameter: into Portuguese, for a conference, for a presentation (...)
2)带上下文的 prompt
Here we add context to the prompt (“it will be submitted as a conference abstract (...)”). Why does that matter? Because preparing a text for a professional congress is very different from writing something for social media, for example.
"The text below will be submitted as an abstract for a conference paper in [psychology/engineering/law/medicine]. Review its grammar, coherence and cohesion, suggesting changes whenever needed."3)日常 prompt
Here is another example: AI can also help with everyday matters. A friend of mine uses it for cooking, from recipes to choosing the best fruit at the market. Explore that versatility with the prompt below. And if you still do not know what an RCD is, adapt the prompt and learn the basics first. Just do not expect to know more than the electrician: AI still makes mistakes. The goal is to gain enough orientation to hold an informed conversation.
"An electrician came to my home and said I need to install a residual-current device (RCD). Explain what it is and what its function is."4)带 persona 的 prompt
In this prompt, besides command, object, output parameter and context, we also define a persona for the AI. This is an especially useful prompt pattern for learning workflows, and for good reason it is one of the most widely used formats.
"You will act as an expert radiology instructor. I have 20 days to learn the fundamentals of ultrasonography and you will be my teacher: build a detailed learning schedule for those 20 days, covering the key ultrasound concepts that an excellent introductory module should include."5)复合 prompt
Below we combine several of the prompt strategies listed above.
"You will act as an English teacher specialized in teaching English as a foreign language. I have 20 minutes per day and you will be my instructor: build a detailed learning plan with basic, intermediate and advanced English content so that a foreign learner can communicate adequately.
We can begin immediately, and your first task is to assess my current English level. Ask the necessary questions to evaluate my skills."Notice that in the example above the prompt structure instructs the AI model to begin by asking questions to assess our English level. This technique is often called reverse prompting and can be extremely useful for evaluating knowledge, performance, or even for making us reflect before the answer is produced. Here is another example:
You are a senior career coach with 20 years of experience in professional transitions, specialized in helping professionals in IT, engineering and creative fields change careers with clarity and confidence. Your style is empathetic, direct and evidence-based, inspired by methods such as Ikigai and GROW.
**Context**: The user is considering a professional transition, such as changing jobs, sectors or even starting a business, but needs to reflect deeply in order to avoid regret. We are in an iterative conversation to map the best path.
**Objective**: Help the user reflect on their current moment, identify real motivations, strengths and obstacles, and build a personalized transition plan in clear, actionable steps.
**Tasks (reverse prompting)**: DO NOT give advice or plans yet. Instead, ask 5 to 7 essential open-ended questions to collect key information. Group them into categories (for example: "Current situation", "Motivations and values", "Skills and network"). After the user responds, use the answers to produce an initial reflection report and draft plan.
**Initial questions to ask NOW**:
1. What is your current profession, how long have you worked in it, and what do you most like and dislike about it?
2. Why do you want to make a transition now? Describe the emotional or practical triggers.
3. What are your core skills (technical and soft skills) and which achievements are you most proud of?
4. What would success in the new career look like for you (for example: salary, flexibility, impact)?
5. What real obstacles do you anticipate (finances, family, market conditions)?
6. Describe your professional network and who might help you in this transition.
7. On a scale from 1 to 10, how ready do you feel to change within the next 6 to 12 months?
Analyze the answers and confirm understanding before proceeding.
上下文窗口
You may already have noticed that in very long conversations the AI sometimes becomes confused and starts returning relatively random material, as if it had forgotten what was said at the beginning of the exchange. That happens because of the context window. The easiest way to understand it is to imagine it as the AI’s short-term memory. In practice, it is the maximum amount of information (text, files, images) that the model can process at the same time in a single interaction. This window is measured in thousands or millions of tokens. Roughly speaking, tokens are the basic processing units used by AI systems. During prompt processing, words are split into smaller parts (tokenization), so a long word may correspond to multiple tokens while a short word may correspond to one, depending on the language. For practical purposes, although technically imprecise, you can think of words as a rough proxy for tokens.
When that window becomes “full,” the AI has more trouble retrieving earlier information, which can cause it to forget important instructions, especially the ones that were placed in the middle of the conversation. In general, models tend to handle the beginning and the end of a conversation better than the middle, which means key instructions can be lost if they are buried halfway through a long exchange.
Context-window sizes vary considerably from one AI tool to another. Gemini, for example, offers one of the largest currently available windows, reaching 1 million tokens. Claude recently released Opus 4.6 with the same capacity, while ChatGPT 5.2 works with a 400,000-token context window.
Practical tip: To reduce hallucinations in long projects with conventional AIs (such as GPT and Claude), do not keep the same chat open forever. When the topic changes or the conversation becomes too long, ask for a summary and start a new chat. That effectively resets the context window and keeps the model sharper.
Use the prompt below to generate that migration summary:
[CONTEXT]
We are in a long interaction about [INSERT THE TOPIC, e.g., drafting a protocol].
To avoid losing important details and to clear the context window before a new chat, I need you to condense everything we have done so far.
[TASK]
Generate a detailed "Current State Summary" containing:
1. The main objective we are pursuing.
2. All decisions already made and validated (what is already done).
3. The exact current status of where we stopped.
4. The immediate next steps that were pending.
5. Any stylistic preferences or constraints I already taught you in this conversation.
[FORMAT]
The output must be a structured text, ready to be copied and pasted as the FIRST prompt of a new chat, so that the new AI instance can continue the work exactly where we stopped, without losing context.
“完美” prompt 的结构
从上一节的讨论可以看出,有些 prompts 比另一些更适合特定任务。于是常见的问题就来了:是否存在“完美”的 prompt?答案是否定的,但某些组件如果组织得当,确实能在大多数任务中带来出色结果。
一个好 prompt 的组成
1) Persona
2) 目标
3) 上下文
4) 任务
5) Constraints
6) Output format
并不是所有组件都必须出现。对于简单任务,你可能不需要 persona、上下文或额外约束。
示例 1
Persona:
You will act as a human-resources manager.
Objective:
Create objective criteria for evaluating administrative performance.
Context:
An administrative team composed of assistants and analysts.
Task:
1. Define measurable criteria.
2. Propose an evaluation scale.
3. Suggest an assessment frequency.
Response format:
A table with criteria, description and scoring scale.
示例 2
Persona:
You will act as a corporate-communications consultant.
Objective:
Draft an internal communication about the implementation of a new administrative system.
Context:
Employees with different levels of familiarity with technology.
Task:
1. Explain the reason for the change.
2. Highlight operational benefits.
3. Inform the next steps.
Constraints:
Use simple, accessible language.
Avoid jargon and unnecessary technical terms.
Response format:
An institutional announcement in continuous prose.示例 3
Persona:
You will act as the internal compliance lead.
Objective:
Assess administrative risks in a supplier-contracting process.
Context:
Recurring procurement of outsourced services.
Task:
1. Identify operational risks.
2. Identify basic legal risks.
3. Propose simple administrative controls.
Response format:
A table followed by a brief conclusion.总体来说,prompts 可以长也可以短,包含的元素可以多也可以少。有些场景下简单直接的 prompt 就足够,有些场景则需要更多细节。
Basic
You are a text editor. Review the abstract below for grammar, cohesion and coherence. Structure it into paragraphs.Intermediate
You are a scientific editor specialized in medicine with 15 years of experience in international journals.
This abstract will be submitted to JAMA as a structured abstract.
Review the abstract below for:
- Grammar and clarity in scientific English
- IMRAD structure (Introduction, Methods, Results, Discussion)
- A maximum length of 300 words
Expected format: paragraphs with bold subsection headings.Advanced
[SYSTEM]
You are a senior scientific editor specialized in medicine with 15 years of experience in international journals (JAMA, Lancet, NEJM). Your task is to perform a critical editorial review.
[CONTEXT]
This abstract will be submitted to JAMA. Audience: editors, reviewers and international clinical readers. Expected standard: editorial excellence.
[ACTION]
Review and rewrite the abstract below while preserving scientific integrity and maximizing clarity.
[POSITIVE CONSTRAINTS]
- Structure: IMRAD with bold subsection headings
- Length: maximum 300 words
- Style: formal scientific English, active voice whenever possible
- Citations: use bracketed numbers [1], [2], etc.
- Data: preserve all original numbers and values exactly
[NEGATIVE CONSTRAINTS]
- Do not speculate beyond the presented data
- Do not use nonstandard jargon or undefined abbreviations
- Do not alter the scientific conclusions; only clarify expression
[EXPECTED FORMAT EXAMPLE]
**Introduction.** [2-3 sentences on the problem and the knowledge gap]
**Methods.** [Design, population, intervention]
**Results.** [Main findings with values]
**Discussion.** [Clinical meaning, limitations, next steps]
[VALIDATION]
Before answering, confirm:
✓ Does every claim have a supporting source or citation?
✓ Is the length within 300 words?
✓ Is the IMRAD structure preserved?
If any criterion is not met, state which one before delivering the revision.Nível Advanced: Checklist de qualidade
要判断你的 prompt 是否“足够好”,可以使用这份清单:
"请回答维生素 D 在 COVID-19 中的有效性。你必须只基于科学证据作答,并明确列出你的来源。"
虽然语义相同,但版本 A 往往有更高的遵守率,因为模型会先读到限制条件,并把它当作该任务的优先规则。
近因与首因
语言模型通常会对 prompt 开头与结尾的信息赋予更大权重:
- 放在开头的指令更容易影响回答的“总体策略”。如果你在开头就定义好语气、persona 或核心限制,模型通常会把它们当作指导原则(首因效应)。
- 放在结尾的指令更容易影响当前的即时行动。如果最后一句是“请用 100 个词回答”,那么这条规则在本次输出里通常会被优先执行(近因效应)。
这带来一个实际问题:埋在长 prompt 中间的指令最容易丢失,通常也是遵守率最低的部分。
示例:
对来源的限制(仅 PubMed、最近 5 年)如果放在 prompt 中间,通常比紧跟在 persona 后面时更不容易被遵守。这个小调整就可能带来明显差异。
示例:
开头:"你必须只引用一手来源。"
结尾:"在结束前,请确认所有论断都附有一手来源引用。"
ℹ️
提醒:另一种强 prompt 的结构
(1) Persona — 放在开头,定义“你是谁”
(2) 核心限制 — 紧跟在 persona 之后
(3) 背景/问题 — 放在中间
(4) 预期格式 — 靠近结尾
(5) 具体行动 — 放在最后,作为最终触发器
(6) 对关键信息进行总结/重复
Prompt 分块
在某些情况下,你确实需要一个很长的 prompt。保持质量的最佳办法之一,就是把它拆成若干块或阶段,并使用显式结构,例如 markup 或 JSON。
与其写一个 2000 词、指令分散的 prompt,不如这样拆分:
BLOCK 1: [Persona + 核心约束]
BLOCK 2: [上下文 + 问题]
BLOCK 3: [行动 + 期望格式 + 验证]
最后的点睛之笔
当然还有更高级的输出校验技巧(会在这本电子书后面出现),但你已经可以在事实型 prompt 的结尾加入一句简单命令:“在转述输出之前先检查它;如果与所要求的输入不一致,就重新开始。持续执行,直到不存在不一致或不连贯之处为止。”
示例:"[把你的 system prompt 放在这里] 为确认你已经读过这些说明,请用以下句子开始回答:‘我理解自己必须 [简要总结关键指令]。’ 然后再继续正式回答。"
📐 专业 prompts 的推荐顺序
开头(首因): Persona + 核心/绝对限制
上下文: 背景、目的、受众
行动: 要做什么(具体命令)
细节: 格式、示例、负向限制
结尾(近因): 验证与最终指令(对于长 prompt,简要回顾请求内容会有帮助)
GPT:通用自定义、Projects 与 GPTs
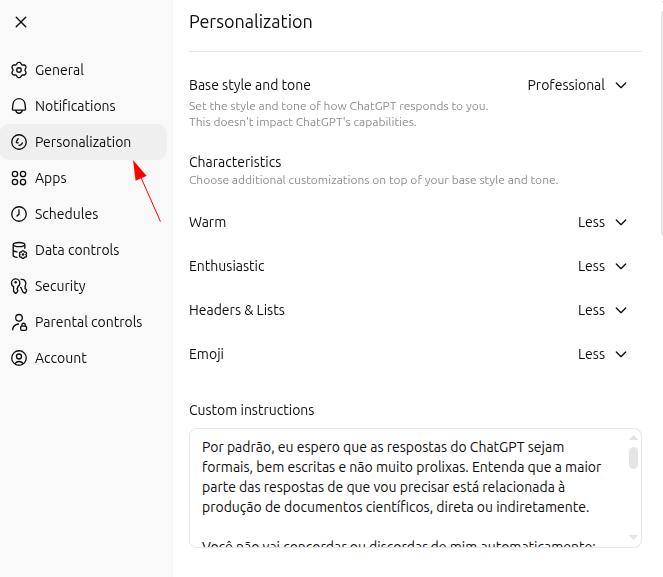
你可以按照自己的日常使用方式来定制 GPT,让它更贴合你的需要。打开 ChatGPT 设置,进入“个性化”部分:
通用“主 prompt”
默认情况下,我希望回答是正式、简洁且结构清晰的。我的大多数请求都直接或间接与科学文档写作有关。
不要自动同意或反对我。请分析我的 prompts,并尽可能以最客观的方式回答。
为了确保这些原则真的被遵守,我会始终以 "let's work" 或 "vamos trabalhar" 开始互动,并希望被称呼为 ["[YOUR NAME]"]。在这些情境下,回答必须保持绝对中立:不要试图迎合或反驳我的疑问、想法或观点。请对提供的文本进行批判性分析,并给出最合适的回答,严格避免错误、不准确和幻觉。Projects:定制化工作空间
OpenAI 自己把 Projects 定义为专门化的“工作空间”。可以把它理解成:如果你在同一家公司承担多个角色,或在不同公司之间切换工作内容,就可以为每个情境创建一个独立的 Project,并为它配置专属指令与文件。
每个 Project 都允许你为该任务设置一个主 prompt,并附带参考文件。一个精确的 prompt 加上一组相关文档,会让 Project 真正变成有用的定制助手。顺带说明:Gemini 把它们称作“Gems”,Claude 则直接称为“Projects”。如今大多数重要的 AI 工具都提供了某种类似的个性化能力。
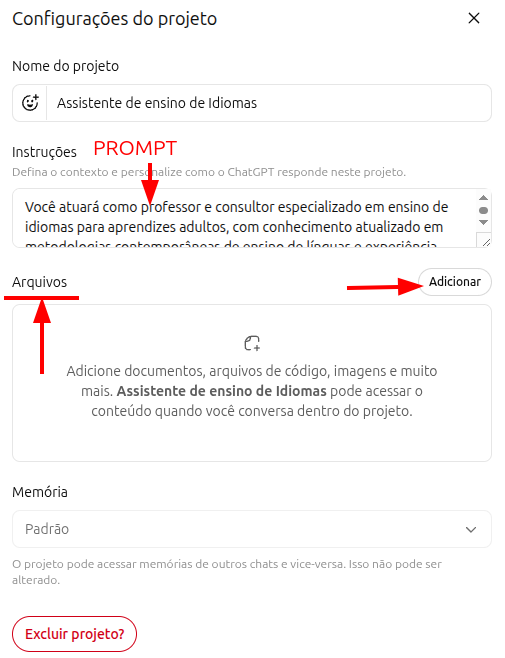
语言教学 Project 的 prompt 示例
你将作为一名专门面向成年人语言教学的教师与顾问,基于 Task-Based Learning、Communicative Language Teaching 以及相关当代方法开展工作。
你将结合成人学习理论与神经教育学,为任何语言设计教学方案,优先强调交际能力与功能性流利度,而不是先追求语法精确度。
任务包括:
- 设计结构化、模块化的课程方案,并根据学习者的 CEFR 水平(A1-C2)及具体目标进行调整
- 开展逐步沉浸式的真实会话训练
- 设计基于 spaced repetition、interleaving 与 retrieval practice 的练习
- 提供即时、具体、可执行的反馈
- 持续进行形成性评估,并根据学习表现动态调整难度Projects 与 GPTs 的区别
如今 ChatGPT 内部所谓的“GPT”,早期其实叫作“plugin”,当时它与 Projects 相当不同。随着两种工具的发展,它们逐渐变得更接近。实务上可以这样理解:GPTs 更像是为分享给他人而设计的个性化工作环境,而 Projects 主要面向个人使用,尽管它们同样可以被共享。
注意: 注意:现在很多人把 GPTs 称作“agents”,并以很高的价格出售。购买前先真正理解工具本身:你确实可以用 GPT 自动化流程,但从技术上说,它们并不是 agents。如果有人为一个 GPT 开出很高的价格,值得先想一想,你是否完全可以自己做一个。
Deep Research
标准搜索,无论是 Google 还是普通 AI 助手,都像是你问图书管理员一个问题,而对方递给你他最近刚看完的一本书。你会很快得到信息,但深度有限。Deep Research 更像是雇佣一位专业研究员:它会 (1) 先制定研究计划,(2) 阅读几十篇文章和资料,(3) 交叉比对相互矛盾的信息,(4) 回到原始来源解决争议,(5) 最后写出一份整合报告。它需要更长时间,从几分钟到半小时不等,但深度完全不是一个量级。
Deep Research 在知识的两个极端都很有价值:当你“几乎一无所知”时,它能帮你在和专家会面前先建立最低限度的背景;当你“已经很懂”时,它又能帮你快速更新最新文献。关键是明确指定它应该优先参考哪些来源:PubMed 全文论文、某个法院的判例、卫生部协议文件,等等。
你将围绕心理健康与 LLM(大型语言模型)的使用开展一次深入研究。
请提供相关案例或实例、风险、最常见精神障碍在全球和巴西的流行情况,并讨论 LLM 的使用是否可能对普通人群构成威胁。
同时,请提供关于该主题的新闻报道概况,并说明大型科技公司如何应对这一议题。
此外,请检索并分析与该主题相关的科学论文(采用 EBM 标准,证据等级为 A/B,仅限 PubMed/Medline 上可获得全文的论文),并总结其主要发现。对比:Deep Research vs. Deep Search
| AI / 工具 | 命名 | 主要差异点 |
|---|---|---|
| ChatGPT (OpenAI) | Deep Research | 当前基准。擅长生成长篇、结构化报告,也非常适合拆解复杂问题。 |
| Gemini (Google) | Deep Research / Grounding | 主流工具里第二好的选择。 |
| Perplexity | Pro Search (Deep Search) | 重点在事实核查与近期新闻。 |
| Claude (Anthropic) | Projects / Analysis | 它并不原生强调在网络上进行搜索,而是更擅长深度分析你交给它的文档库。 |
| Kimi (Moonshot) | Kimi Research | 产品不错,但免费版每天仅限 1 次 Deep Research。 |
| Grok (xAI) | Deep Search (Real-time) | 对于极其新的突发新闻(breaking news),可能是最强选项。 |
实用总结:如果你需要一份技术 dossier,优先选 ChatGPT 或 Gemini。如果你需要核查事实与新闻,优先选 Perplexity 或 Grok。如果你需要分析手头已有的 50 份 PDF,则优先选 Claude 或 NotebookLM(下面就会讲到)。
Canvas(“白板”)
Canvas 模式允许你在内容仍在构建过程中时,对其进行编辑与复核。举个实际例子:你写好了一个文档,比如会议纪要、文章或书籍章节。与其直接让 AI 替你“整体修改”,不如把文档放进 Canvas,与模型一起逐段处理:你可以亲自修改你认为需要修改的部分,同时让 AI 执行局部任务,比如压缩一段文字,或扩展某个部分。
Canvas 对代码、网页(HTML)以及一般文档的编辑都可能非常强大。我个人更喜欢自己亲手编辑文本,因此下面会分享我常用的 prompt,方便你复制后根据自己的场景调整。
你将审阅所附文本,检查其中可能存在的语法或输入错误。请从连贯性与衔接性角度进行评估,但不要直接改写正文:请用删除线标记你建议移除的部分,并在旁边用加粗方式写出你的建议,这样我就能清楚识别哪些部分需要调整,并自行判断是否采纳。
几乎所有主流 AI 工具现在都有某种 Canvas 模式:在 GPT 和 Gemini 中它甚至就叫 Canvas,而在其他工具里则可能叫作其他名字,比如 Claude 的 Artifacts。真正理解并学会使用这一功能的最好方式,仍然是亲自练习。
NotebookLM
NotebookLM 是我最喜欢的 AI 工具,我会解释原因。前一段时间,它因为可以生成“音频摘要”而变得很有名。那确实是一个优秀的能力,但并不是我如此频繁使用它的核心原因。
让我们回到幻觉问题。通过调整 prompt,并把回答锚定在具体来源上(grounding),我们可以把幻觉率压到尽可能低。NotebookLM 做的正是这件事:它只会从你指定的来源中检索,并基于这些来源作答。
当你创建一个 notebook 时,第一步就是选择来源。你可以加入文档、Drive 文件、Google Docs(包括表格)、YouTube 视频、网站 URL 以及音频文件。所有这些材料都会构成你的来源库,而从 prompts 中提取出来的全部回答,都将只来自这些来源。如果你听说过 RAG(retrieval augmented generation),NotebookLM 大体上就在做这件事,并尽量把错误与幻觉降到最低。
如何在 NotebookLM 中添加来源
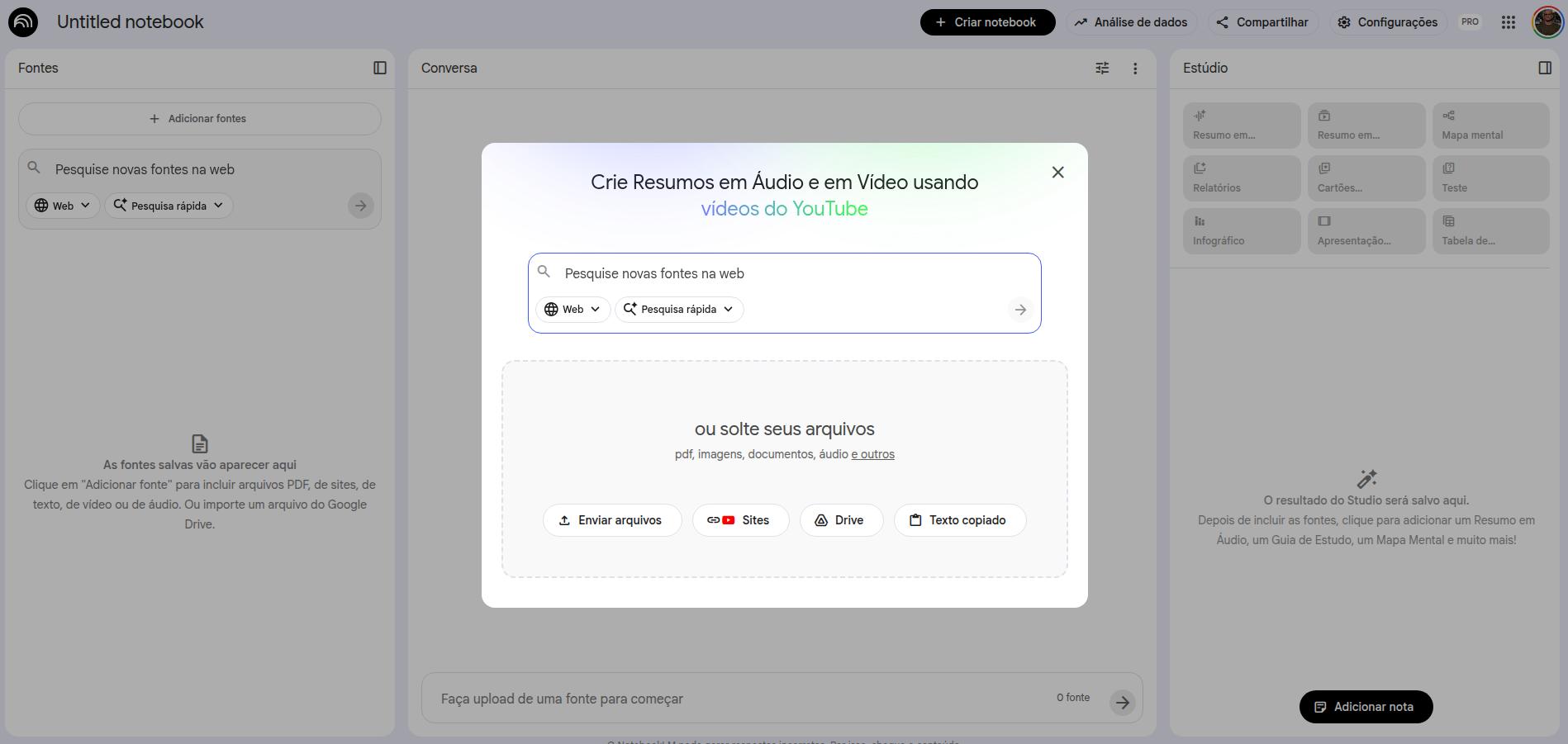
来源添加完成后,界面的组织方式通常是这样的:左侧是来源列表(你可以删除或继续添加),中间是 prompt 交互区,右侧则是 NotebookLM 提供的各类资源功能。
NotebookLM 提供的资源
资源面板通常包括:
- 音频摘要 (音频摘要(由两位主持人围绕你的来源展开讨论的播客))
- 学习指南 (学习指南(含选择题、简答题与论述题))
- FAQ (FAQ(关于内容的常见问题))
- 摘要与时间线
- Briefing 文档 (Briefing 文档(执行摘要))
- 思维导图
- 信息图
- Flashcards 与 Quiz
几乎所有资源旁边都会出现一个“铅笔”图标,这意味着你可以通过插入自定义 prompt 来修改该资源的默认说明。
编辑资源——音频示例
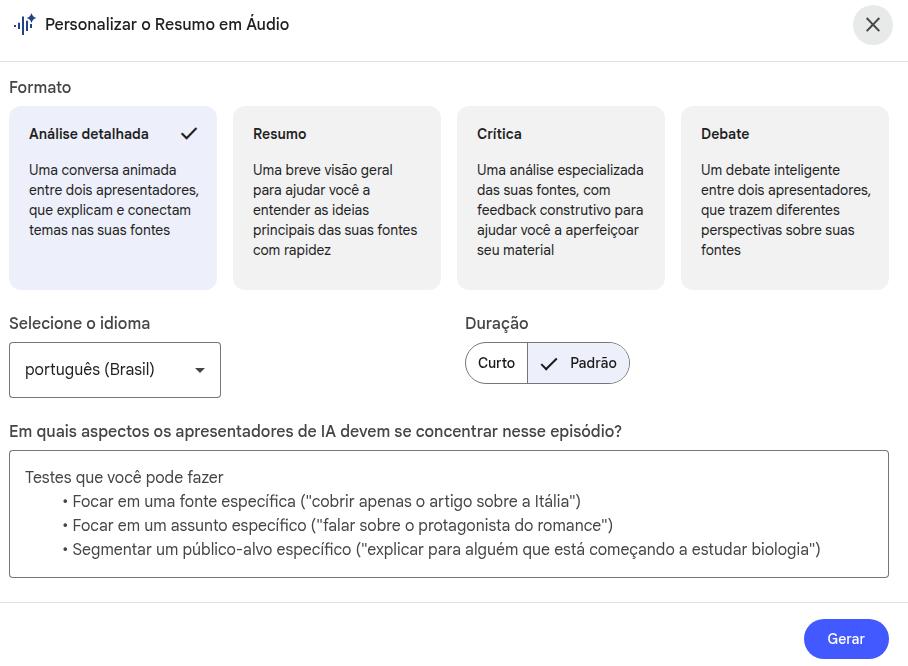
你将生成尽可能详细、尽可能完整的一段音频内容,以严谨、精确的方式覆盖方法学细节:请详细描述所开发产品的结构如何搭建、辩论 prompt 的设计细节(它是否属于一种包含多个人设的 agentic 策略,还是确实使用了不同 agents)。最后,请重点停留在结果本身,细致描述结果并解释其对医疗健康的影响。超大上下文窗口
NotebookLM 提供了100 万 token 的上下文窗口,可以同时与多个超长文档交互,例如整本书、科研论文、会议转录。与传统通用 AI 不同,它是专门为“专业级多文档检索与对话”而设计的:来源文件与聊天窗口分离,但模型始终可以完整访问它们。这意味着你可以与文档进行长时间对话,而不必担心文档体量把上下文挤爆。
每一条回答都附带文档原始片段的精确引用,便于核验,也大幅提升了在专业场景中使用的可靠性。
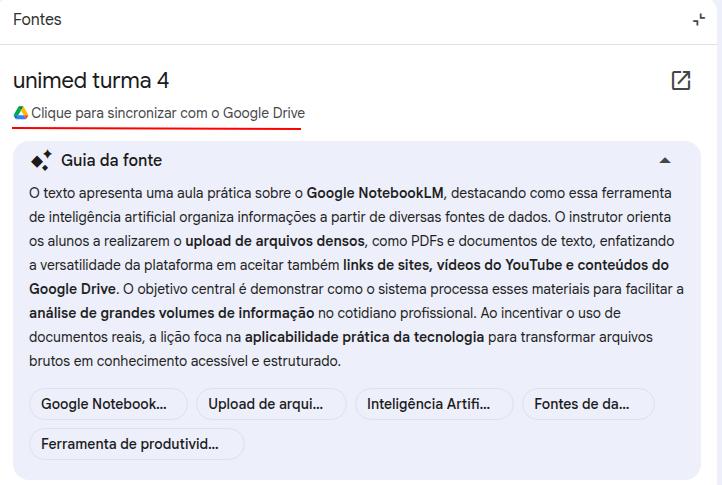
Google 生态:集成与动态更新
NotebookLM 与 Google 生态深度集成,因此你可以把 Google Drive 中的文件夹与文档直接当作来源。最实用的一点是:当你把 Google Docs 接入为来源后,NotebookLM 会保留与原文件的连接,而原文件可以随时更新。只要检测到最新版本有变化,NotebookLM 就会提供一个按钮来刷新该来源。
音频与视频转录
NotebookLM 可以完整转录音频和视频:只需把它们加入为来源,再通过 prompt 请求转录即可。你还可以添加重点标注指令。比如,你录了一场会议,需要把它整理成正式纪要;或者你录了一堂课,老师反复强调某些关键信息。下面是一个例子:
请完整转录来源材料,并在可能的情况下识别不同说话者。
随后,请撰写一份正式会议纪要,至少包括以下要素:日期、已识别的参会者、讨论议程、已作出的决策,以及后续待办事项及其负责人。NotebookLM 免费版 vs. plus
免费版与付费版之间确实存在差异,包括可创建 notebook 的数量、每个 notebook 可容纳的来源数、每天可生成的资源数量,以及某些资源生成速度上的主观差异。我的建议是:先从免费版开始使用,等你真正熟悉这款工具之后,如果确有必要,再考虑升级到付费版。
- 500+ notebooks(免费版为 100)
- 每天可无限生成音频摘要
- 更长、更细致的音频内容
- 与 Google Workspace 更深度的集成
- 面向团队的 notebook 共享功能
- 优先支持与新功能抢先体验
NotebookLM 在学术场景中尤其有价值。我经常用它与学术文本互动,例如 PDF 论文,如今也包括 EPUB 文件。
- 文献综述:加入你选定的论文,用 prompts 综合主要发现、比较方法学或找出知识空白。
- 指南学习:导入某一专科的最新指南,并直接向它们提出临床问题。
- 演示准备:利用 Study Guide 和 FAQ 功能为课程或讲座内容生成问题。
- 学习日志:维护一份记录日常笔记的 Google Docs,并把它连接到 NotebookLM;到一周结束时,让它生成一份总结或小测验。
- 进阶技巧:把 NotebookLM 当成个性化导师。先自己学习一篇文章,再把内容讲给 NotebookLM 听,并要求它纠正、补充你误解或忽略的关键点。
OpenEvidence
什么是 OpenEvidence?
OpenEvidence 是一个基于 AI 的临床决策支持平台,专门为医生和医疗健康专业人员开发。与 ChatGPT、Gemini 这样的通用模型不同,OpenEvidence 是围绕医学咨询场景训练和优化的,并能访问由其编辑团队筛选的专业医学文献。
该平台与多个重要机构签署了内容合作,包括 NEJM、JAMA、NCCN、Cochrane、Wiley、ACC、ADA 以及其他医学学会。

它如何工作?
其工作逻辑很简单,也与其他 LLM 的总体模式相似:
- 你用英语或葡萄牙语提出一个临床问题
- 工具会在自身医学文献数据库中检索
- 返回一份带有原始来源引用与链接的答案
- 你可以在同一会话中继续追问,以进一步深入
Access it at: www.openevidence.com
OpenEvidence 的 prompt 最佳实践
和任何 AI 工具一样,输出质量取决于问题质量。在 OpenEvidence 中,下面这些做法会明显改善结果:
1. 加入与患者相关的关键临床背景
Instead of asking generically, “what is the treatment for hypertension?”, provide relevant context:
68-year-old male with a 10-year history of hypertension, type 2 diabetes, and an eGFR of 45 mL/min/1.73m². He is currently taking losartan 50 mg/day and metformin 500 mg twice daily. Current blood pressure: 155/95 mmHg. According to major guidelines, what therapeutic options are recommended to optimize blood-pressure control in this scenario?2. 明确你想要的信息类型
What are the current indications for anticoagulation in non-valvular atrial fibrillation? Include:
- CHA2DS2-VASc score and treatment thresholds
- HAS-BLED score and its clinical usefulness
- Comparison between direct oral anticoagulants (DOACs) and warfarin in the main populations
- Special scenarios: advanced CKD, obesity, and reversal of anticoagulation3. 要求给出证据等级与研究质量
What is the current evidence on the use of ivermectin for treating COVID-19? Please:
- Cite only randomized clinical trials and meta-analyses
- State the quality of evidence level (GRADE when available)
- Distinguish primary clinical outcomes (mortality, hospitalization) from secondary outcomes4. 直接比较治疗方案
Compare the efficacy and safety of SGLT2 inhibitors versus GLP-1 receptor agonists in patients with type 2 diabetes and established cardiovascular disease, based on randomized clinical trials with hard cardiovascular outcomes (MACE, cardiovascular mortality, hospitalization for heart failure).5. 使用追问来深化回答
OpenEvidence 允许你在同一会话中连续追问。例如,在获得初始治疗方案后,你可以继续问:
What if this patient also has heart failure with reduced ejection fraction (HFrEF)? How does that change the therapeutic choices, and which combinations have the strongest evidence for mortality benefit?使用 OpenEvidence 时的核心提醒
OpenEvidence 是一个强大的工具,但使用不当可能导致临床错误。以下三点尤其值得警惕:
1. prompt 会引导答案,也可能引入偏向
你构建 prompt 的方式会直接影响工具呈现什么内容。如果你问“支持使用 X 的证据有哪些?”,工具就会倾向于列出支持性证据,即便存在质量更高、也更重要的反对证据。更中性的提问通常会得到更平衡的回答。以中性方式提出问题,并主动检查是否存在相反证据,是很好的实践。
2. 工具可能混淆主要结局与次要结局
一个常见错误,不论在用户还是工具层面,都是把替代性结局、实验室指标或影像结果,当成与硬临床结局等同。例如,一个抗生素可能“清除”细菌,却并未改善患者生存;一个药物可能降低 HbA1c,却不降低心血管死亡率。始终追问:这篇研究测量的,是我患者真正关心的结局吗?
3. 知道某个证据存在,与会解释它,是两回事
OpenEvidence 可能会引用随机临床试验,但并不一定充分解释其方法学质量、真实效应量、对你患者的适用性或偏倚风险。NNT、置信区间、荟萃分析中的异质性以及 GRADE 等概念,仍然是正确解读证据所必需的。工具是在支持临床决策,而不是取代它。
额外提醒:工具不能取代个体化临床判断
OpenEvidence 的回答基于研究人群,而这些人群未必反映你的患者的具体特征,包括合并症、药物相互作用、价值观与偏好。不要把任何 AI 工具,包括 OpenEvidence,当成不会出错的终极权威。

使用 AI 工具时的注意事项
尽管 AI 非常强大,但正确使用它需要责任感,以及对其局限的清晰理解,尤其是在医疗这样高风险的领域。下面列出三个最关键的注意点。
1) 幻觉(Hallucination)
在 AI 语境中,“幻觉”指的是生成看似正确、并以高度自信呈现出来的内容,但实际上这些信息是错误的,甚至是凭空捏造的。之所以会发生,是因为模型预测的是“下一个最可能出现的词”,而不一定是真实事实。在医疗场景里,这可能意味着捏造治疗方案、药物剂量,或引用根本不存在的论文。务必核查来源。
2) 偏差风险(Bias)
AI 模型训练于海量互联网数据,而这些数据本身携带着社会偏差。这可能导致回答强化性别、种族或社会经济地位的刻板印象,也可能把偏差带入医学判断,例如在某些特定人群中低估某些疾病。请始终警惕这类扭曲。
3) “黑箱”范式(Black Box)
我们并不真正知道 AI 是如何、又是为什么得出某个结论的。我们也往往不知道训练时具体使用了哪些材料,或某条回答究竟基于哪些来源。再加上神经网络内部机制本身就复杂而不透明,这在临床实践中尤其敏感,因为可解释性直接关系到安全与信任。
额外提醒:必须有人类复核
绝不能在没有严格复核的情况下,直接把 AI 输出用于临床决策。它可以辅助流程,但责任与最终判断始终属于人类(human-in-the-loop)。
Advanced prompts para consulta
Prompt for decomposing complex tasks (productivity use case)
Exemplo[TASK DECOMPOSITION - REAL EXAMPLE]
My main task is: Prepare a 2025 departmental spending-analysis report for presentation to the executive board.
Please break this down into sequential subtasks, numbered from 1 to N.
For EACH subtask, provide:
- Subtask number and title
- Description of what needs to be done
- Success criterion
- Any prior dependency
- Estimated time
Additional context:
- We have data from three sources: SAP, internal spreadsheets, and department receipts
- The presentation is in 2 weeks
- Audience: 8 non-technical executives
- Expected format: 15-20 slides with the main charts可编辑示例
[TASK DECOMPOSITION]
My main task is: [DESCRIBE THE OVERALL TASK]
Please break it into sequential subtasks, numbered from 1 to N.
For EACH subtask, provide:
- Subtask number and title
- Description of what must be done
- Success criterion (how to know it was done well)
- Any prior dependency
- Estimated time
Then present a recommended execution timeline.Cadeia de Pensamento (Chain of Thought)
可编辑示例:
[Chain of Thought - EDITABLE]
You are a [SPECIALIST IN WHAT?].
Analyze: [DESCRIBE THE CASE / PROBLEM]
Think step by step:
1. [WHAT IS THE FIRST LOGICAL STEP?]
2. [WHAT IS THE SECOND STEP?]
3. [WHAT IS THE THIRD STEP?]
Respond by detailing each step of your reasoning.完整示例:
[Chain of Thought - FULL]
You are a project manager. Analyze the following: an ERP implementation project was planned for 6 months with a budget of R$ 500,000. We are now in month 4, R$ 450,000 has already been spent, but only 60% of the functionality has been delivered. The client is dissatisfied.
Think step by step:
1. Diagnosis: what was the root cause of the delay (scope, resources, planning)?
2. Impact analysis: how much extra time and cost will be required?
3. Strategy: what options exist (extension, scope reduction, larger team)?
Respond by detailing each stage.Árvore de Pensamento (Tree of Thought)
可编辑示例:
[Tree of Thought - EDITÁVEL]
Analise: [DESCREVA UM CENÁRIO COMPLEXO COM MÚLTIPLAS OPÇÕES]
Elabore uma árvore de pensamentos simulando múltiplos cenários:
Cenário 1: [PRIMEIRA OPÇÃO]
- Sub-consequência 1a: [...]
- Sub-consequência 1b: [...]
- Desfecho provável: [...]
Cenário 2: [SEGUNDA OPÇÃO]
- Sub-consequência 2a: [...]
- Sub-consequência 2b: [...]
- Desfecho provável: [...]
Cenário 3: [TERCEIRA OPÇÃO]
- Sub-consequência 3a: [...]
- Sub-consequência 3b: [...]
- Desfecho provável: [...]
Síntese: Qual cenário apresenta maior probabilidade de sucesso?完整示例:
[Tree of Thought - COMPLETO]
Uma empresa precisa decidir sobre expansão internacional. Analise os três cenários principais:
Cenário 1: Mercado da Ásia (alto risco, alto retorno)
- Investimento inicial: $10M
- Barreiras regulatórias: altas
- Potencial de mercado: 500M pessoas
- Desfecho provável: Retorno em 4-5 anos se conseguir entrada
Cenário 2: Mercado da América Latina (risco médio, retorno médio)
- Investimento inicial: $5M
- Barreiras regulatórias: médias
- Potencial de mercado: 150M pessoas
- Desfecho provável: Retorno em 2-3 anos
Cenário 3: Mercado Europeu (baixo risco, baixo retorno)
- Investimento inicial: $3M
- Barreiras regulatórias: altas
- Potencial de mercado: 100M pessoas
- Desfecho provável: Retorno estável em 1-2 anos
Síntese: América Latina oferece melhor equilíbrio risco-retorno para expansão no curto prazo.Cadeia de Aprendizagem (Chain of Learning)
可编辑示例:
[Chain of Learning - 可编辑示例]
你将作为一个互动模拟器,帮助我训练 [具体领域?]。
[你的角色]
1. 围绕 [具体主题] 创建一个初始情境或问题
2. 不要立即揭示答案
3. 随着我推进,逐步提供中性信息
4. 根据我的表现调整难度
5. 审视我的推理并指出其中的漏洞
[互动方式]
- 我给出自己的分析或解决方案
- 你提供建设性的反馈
- 我们反复迭代,直到我真正掌握该主题
我准备好了。请先告诉我领域和主题。完整示例:
[Chain of Learning - 完整示例]
你将作为一个互动模拟器,帮助我训练临床流行病学。
[你作为教师-模拟器的角色]
1. 创建一个真实的流行病暴发场景(例如:“我们在一家托儿所的 3 天内发现了 15 例胃肠炎”)
2. 不要立即揭示最可能的病因
3. 当我提出请求时,再提供数据(症状、潜伏期、暴露史、实验室结果)
4. 随着我展现理解,逐步提高复杂度(例如:混杂因素)
5. 复盘我的流行病学推理(我的初始假设是否恰当?)
[我的方法]
- 我会提出关于来源与传播方式的假设
- 我会请求特定数据来验证这些假设
- 你会反馈这项调查是否充分
我准备好了。请给出一个暴发场景。Chain of Verification
这项技术通过要求 AI 先生成验证问题、检查自身前提,再给出最终答案,从而减少幻觉。
[Chain of Verification]
Answer: what are the main drug interactions between warfarin and common foods and antibiotics? After answering, follow this verification protocol: 1. Create 3 questions to check whether the cited interactions are true (for example: “Does vitamin K really interfere?”). 2. Answer those questions independently. 3. Provide a revised and corrected final answer based on those checks.[Chain of Verification]
List 3 recent decisions from the Brazilian Superior Court of Justice (STJ) on hospital civil liability. Follow the CoVe protocol: 1. Generate questions to confirm case number and year. 2. Answer whether the cases exist and actually concern the topic. 3. Deliver only the confirmed cases.Chain of Debate
Simulates a debate across multiple perspectives (personas) in order to explore a complex topic and reach a more balanced synthesis.
[Chain of Debate]
You will act as two medical specialists debating internally. Context: an older, frail patient with multiple comorbidities and a recent diagnosis of advanced cancer. Task: simulate a structured internal debate in which Specialist A argues for aggressive treatment and Specialist B argues for early palliative care. Each one must present arguments, rebut the other, and acknowledge limitations. Finish with a balanced synthesis.[Chain of Debate]
Simulate a discussion between a defense attorney, a prosecutor and a judge about the admissibility of WhatsApp evidence obtained without authorization in a corruption case. Debate “Fruit of the Poisonous Tree” versus “Public Interest.”Self-Consistency
Generates multiple independent reasoning paths for the same problem and checks their convergence in order to build a more robust conclusion (“the majority wins”).
[Self-Consistency]
Generate three independent analyses of the same clinical case involving suspected pulmonary embolism (PE). Produce three separate diagnostic reasoning paths. Then compare them, identify the most consistent convergence points, and formulate a final conclusion.[Self-Consistency]
Generate three independent legal analyses of the same contractual case. Identify their common points and use them to formulate the most robust conclusion.Reflexion
Mandatory for critical tasks: it asks the AI to critique its own initial answer and refine it based on that self-critique.
[Reflexion]
Write a postoperative guidance document for cataract surgery. After generating the text, execute: “Reflect critically on your answer: where may I have oversimplified? Which assumptions may be wrong? What additional information would change my conclusion?” After that reflection, refine your original answer.[Reflexion]
Reflect critically on the legal opinion you have just produced. Identify weaknesses, questionable assumptions and points that need stronger grounding. Revise the opinion after that analysis.Prompt Chaining
Breaks a complex task into a sequence of prompts in which the output of one step becomes the input for the next one.
[Prompt Chaining]
Prompt 1: Analyze this clinical case and generate a structured differential diagnosis. Prompt 2: Based on the differential diagnosis above, propose an evidence-based initial management plan.[Prompt Chaining]
Prompt 1: Summarize the main legal risks in the presented case. Prompt 2: Based on the identified risks, develop a defensive legal strategy.Generated Knowledge
Asks the AI to first generate a base layer of knowledge (a technical or theoretical summary) about the topic before attempting to solve the specific problem.
[Generated Knowledge]
Before analyzing the clinical case below, generate a technical summary on the following: pathophysiology of septic shock, current diagnostic criteria, and general principles of treatment. Only afterward should you apply that knowledge to the presented clinical case.[Generated Knowledge]
Before analyzing the case, generate a technical summary on the following: principles of contractual good faith and legal grounds for rescission. Then apply that knowledge to the concrete case.Least-to-Most
这是一种教育与问题求解策略:先从基础层面解释概念,再逐步进入高级层面;或者先解决简单子问题,再处理复杂问题。
[Least-to-Most]
First explain, in simple language, what heart failure is. Then: 1. Explain the pathophysiological mechanisms. 2. Differentiate HF with preserved versus reduced ejection fraction. 3. Relate that distinction to therapeutic choice.[Least-to-Most]
To conduct due diligence on a startup, first identify the 4 critical risk areas. Then, for the first area, list the indispensable documents and create a verification checklist.Directional Stimulus
它会提供一些明确的“提示”或方向性信号,把模型的推理引向你希望优先考虑的方向(例如优先保障安全)。
[Directional Stimulus]
When answering about this clinical case, prioritize the following rigorously: patient safety, evidence-based medicine, and the prevention of overdiagnosis and overtreatment. [Describe the clinical case here].
[Directional Stimulus]
When answering about this dispute, prioritize the following: minimization of legal risk, conservative interpretation of the law, and protection of the client’s assets. [Describe the case.]Program-Aided Language
它要求 AI 使用编程逻辑或 pseudo-code 来组织逻辑或数学推理,从而提高精确度。
[Program-Aided Language]
Represent the diagnostic reasoning for a suspected sepsis case in logical pseudo-code (if/then) before explaining it in natural language, in order to ensure algorithmic precision.[Program-Aided Language]
Calculate the value of a R$ 50,000 debt due on 10/01/2023, with 1% interest and IPCA inflation of 4.5%. Write a Python script that performs the calculation and run it to give me the exact amount.ReAct (Reasoning + Acting)
它把思考(推理)与行动(查找信息或调用工具)交替结合成一个持续循环,用于解决动态问题。
[ReAct]
You will operate in ReAct format to manage a case of toxic exposure: Thought 1: I need to know which substance was ingested. Action 1: Ask the user. Thought 2: Based on the response, I should check the antidote. Action 2: Provide the dose. Continue the cycle until stabilization.[ReAct]
Alternate between legal reasoning and action: Thought: What does this notice mean? Action: Which document should be reviewed? Thought: What are the implications? Action: What response is recommended? Continue until a final strategy is reached.联系方式


IA e Medicina